This blog provides an overview of the two fundamental concepts in Apache Kafka: Topics and Partitions. While developing and scaling our Anomalia Machina application we have discovered that distributed applications using Apache Kafka and Cassandra® clusters require careful tuning to achieve close to linear scalability, and critical variables included the number of Apache Kafka topics and partitions.
In this blog, we test that theory and answer questions like “What impact does increasing partitions have on throughput?” and “Is there an optimal number of partitions for a cluster to maximize write throughput?” And more!
1. Introduction to Kafka Partitions
Two fundamental concepts in Apache Kafka are Topics and Partitions
Topics are fundamental to how Kafka works as a streaming distributed system. They enable Kafka producers and Kafka consumers to be loosely coupled (isolated from each other) and are the mechanism that Apache Kafka uses to filter and deliver messages to specific consumers. Consumers subscribe to 1 or more topics of interest and receive messages that are sent to those topics by producers.
2. How partitioning works
Partitions are the main concurrency mechanism in Kafka. A topic is divided into 1 or more partitions, enabling producer and consumer loads to be scaled. Specifically, a consumer group supports multiple consumers—as many consumers as partitions for a topic. The consumers are shared evenly across the partitions, allowing for the consumer load to be linearly scaled by increasing both consumers and partitions. If a consumer instance fails, the partitions are rebalanced across the remaining consumers in the group.
You can have fewer consumers than partitions (in which case consumers get messages from multiple partitions), but if you have more consumers than partitions some of the consumers will be “starved” and not receive any messages until the number of consumers drops to (or below) the number of partitions; i.e. consumers don’t share partitions (unless they are in different consumer groups).
Here are some useful partition facts to get you started:
Each kafka topic can have one or more partitions.
- There is no theoretical upper limit to the number of Kafka partitions you can or should have, but there is a minimum of one partition per topic. You can request as many partitions as you like, but there are practical limits to the number of partitions Kafka can handle.
The size (in terms of messages stored) of partitions is limited to what can fit on a single node.
-
If you have more data in a topic than can fit on a single node you must increase the number of partitions. Partitions are spread across the nodes in a Kafka cluster.
Message ordering in Kafka is per partition only.
Avoid unbalanced partitions
-
If you are using an (optional) message key (required for event ordering within partitions, otherwise events are round-robin load balanced across the partitions—and therefore not ordered)—then you need to ensure you have many more distinct keys (> 20 is a good start) than partitions otherwise partitions may get unbalanced, and in some cases may not even have any messages (due to hash collisions).
Partitions can have copies to increase durability and availability
-
This will enable Kafka to failover to a broker with a replica of the partition if the broker with the leader partition fails. This is called the Replication Factor (RF) and can be 1 or more.
Replication Factor
The total number of copies of a partition is the replication factor—i.e. RF=1 means that the leader has the sole copy of the partition (there are no followers); 2 means there are 2 copies of the partition (the leader and a follower); and 3 means there are 3 copies (1 leader and 2 followers).
Note that the partition leader handles all writes and reads, as followers are purely for failover. Cleverly, followers just run Consumers to poll the data from the leaders. Partitions and Replication Factor can be configured cluster-wide or set/checked per topic (with the ic-Kafka-topics command for Instaclustr managed Kafka clusters).
-
Kafka Partition Example
The following diagrams (from the insidebigdata series we published last year on Apache Kafka architecture) illustrate how Kafka partitions and leaders/followers work for a simple example (1 topic and 4 partitions), enable Kafka write scalability (including replication), and read scalability:
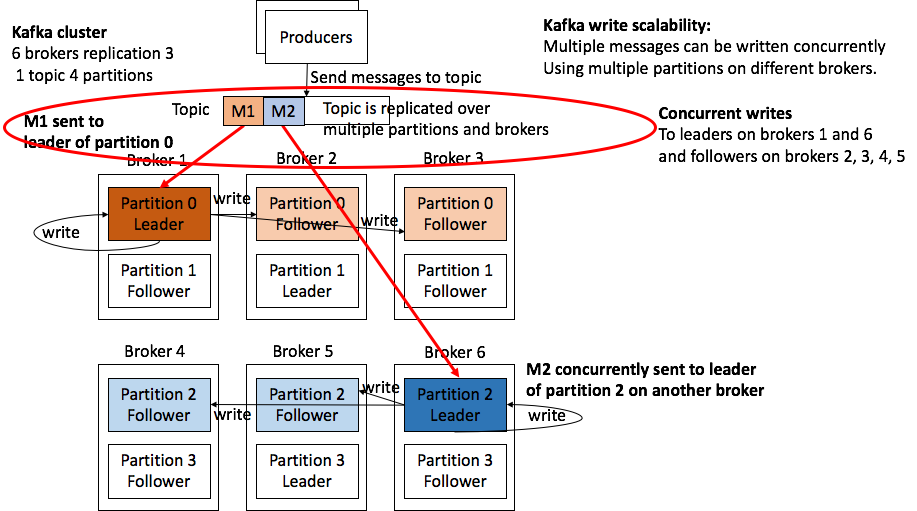
Figure 1: Kafka write scalability—showing concurrent replication to followers
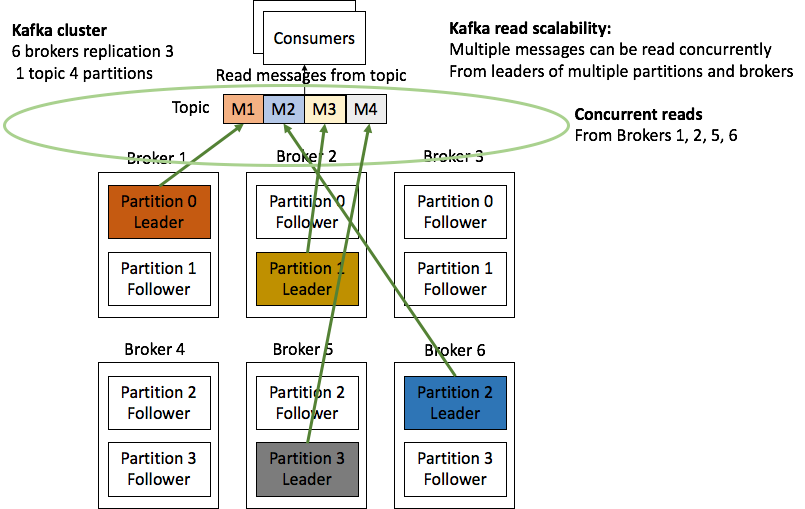
Figure 2: Kafka read scalability—partitions enable concurrent consumers
4. Kafka Partitions and Replication Factor
We were curious to better understand the relationship between the number of partitions and the throughput of Kafka clusters.
While developing and scaling our Anomalia Machina application we have discovered that distributed applications using Apache Kafka and Cassandra clusters require careful tuning to achieve close to linear scalability, and critical variables included the number of topics and partitions. We had also noticed that even without a load on the Kafka cluster (writes or reads), there was measurable CPU utilization which appeared to be correlated with having more partitions.
We had a theory that the overhead was due to (attempted) message replication—i.e. the polling of the leader partitions by the followers. If this is true, then for a replication factor of 1 (leaders only) there would be no CPU overhead with increasing partitions as there are no followers polling the leaders. Conversely, increasing the replication factor will result in increased overhead. Our methodology to test this theory was simply to measure the CPU utilization while increasing the number of partitions gradually for different replication factors.
The test setup used a small production Instaclustr managed Apache Kafka cluster as follows:
3 nodes x r5.xlarge (4 cores, 32GB RAM) Instaclustr managed Kafka cluster (12 cores in total)
This graph shows the CPU overhead on the Kafka cluster with partitions increasing from 1 to 20,000, with replication factor 1 (blue), 2 (orange), and 3 (grey), for 1 topic. We also tried 100 topics (yellow, RF=3) with increasing partitions for each topic giving the same number of total partitions.
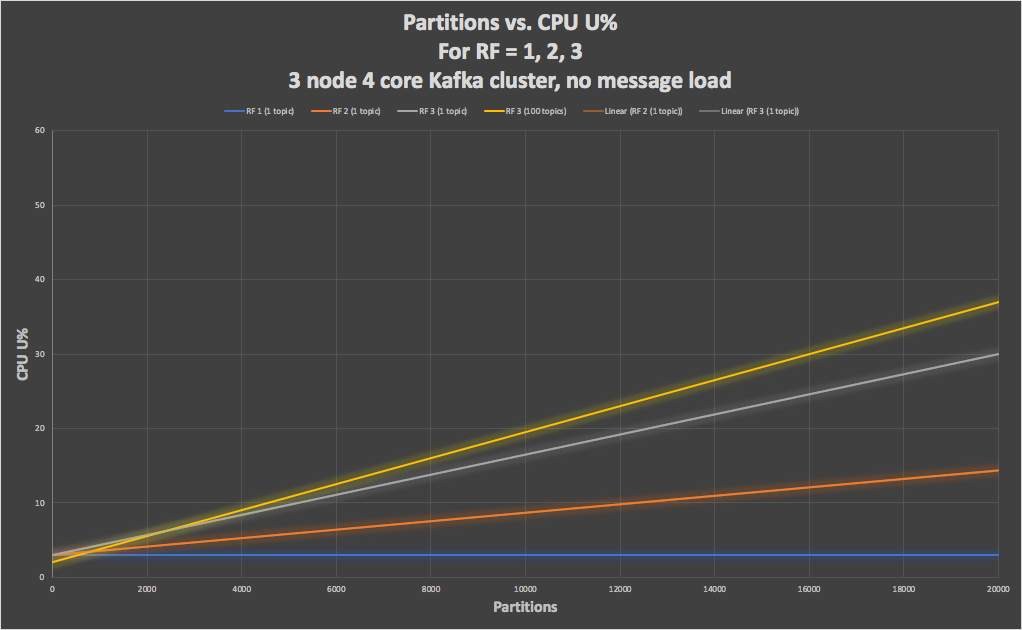
This graph confirms that CPU overhead increases due to increasing replication factor and partitions, as CPU with RF=1 is constant (blue). It also demonstrates that overhead is higher with increasing topics (but the same number of total partitions, yellow), i.e. 100 topics with 200 partitions each have more overhead than 1 topic with 20,000 partitions.
Note that we used up to 20,000 partitions purely to check our theory. In practice, too many partitions can cause long periods of unavailability if a broker fails. If there are many partitions it takes a long time (potentially 10s of seconds) to elect new leaders for all the partitions with leaders that are on the failed broker.
Also note that if the partitions are increased (e.g. using the ic-Kafka-topics command) too fast, or to a value that is too large, then the clusters can be overloaded and may become unresponsive. It pays to increase the number of Kafka partitions in small increments and wait until the CPU utilization has dropped back again.
Transparent, fair, and flexible pricing for your data infrastructure: See Instaclustr Pricing Here
5. Partitions and Producer Throughput
Next, we wanted to find out a couple of things with more practical applications: What impact does increasing Kafka partitions have on throughput? And is there an optimal number of partitions for a cluster (of this size) to maximize write throughput?
Our methodology was to initially deploy the Kafka producer from our Anomalia Machina application as a load generator on another EC2 instance as follows:
1 x m4.4xlarge (16 core, 64GB RAM) EC2 instance
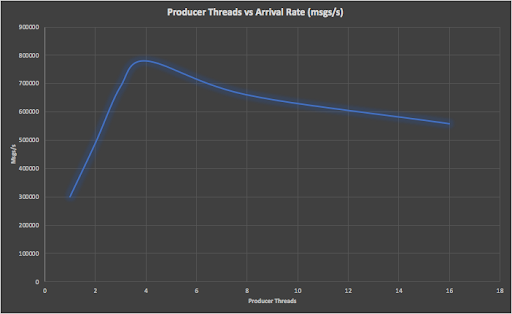
This isn’t a particularly large EC2 instance, but Kafka producers are very lightweight and the CPU utilization was consistently under 70% on this instance. We ran a series of load tests with a multi-threaded producer, gradually increasing the number of threads and therefore increasing the arrival rate until an obvious peak was found. We repeated this test for different numbers of partitions. The replication factor was 3, and the message size was 80 bytes. Here’s a graph showing one run for 3 partitions showing producer threads vs. arrival rate, with a peak at 4 threads.
Repeating this process for 3 to 5,000 partitions we recorded the maximum arrival rate for each number of partitions resulting in this graph (note that the x-axis, partitions, is logarithmic), which shows that the optimal write throughput is reached at 12 partitions, dropping substantially above 100 partitions. The throughput at 5,000 partitions is only 28% of the maximum throughput. There is however only a 7% variation in throughput between 3 and 100 partitions, showing that the number of partitions isn’t really critical until it exceeds 100.
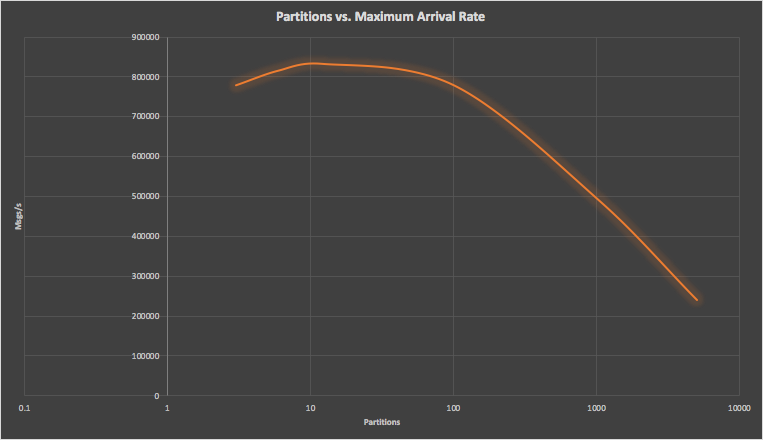
Twelve partitions also correspond to the total number of CPU cores in the Kafka cluster (3 nodes with 4 CPU cores each). Note that the total number of followers is (RF-1) x partitions = (3-1) x 12 = 24 which is higher but still in the “sweet spot” between 12 and 100 on the graph and maximizes the utilization of the available 12 CPU cores.
News Flash! In September 2022 we redid some of these experiments with the new version of Kafka with KRaft, and new hardware, and the results are surprising! Check out part 1 of the new series: Apache Kafka® KRaft Abandons the Zoo(Keeper): Part 1— Partitions and Data Performance
6. End-To-End Throughput and Latency Experiment
Real Kafka clusters naturally have messages going in and out, so for the next experiment, we deployed a complete application using both the Anomalia Machine Kafka producers and consumers (with the anomaly detector pipeline disabled as we are only interested in Kafka message throughput).
We used a single topic with 12 partitions, a producer with multiple threads, and 12 consumers. We monitored the producer and consumer message rates (to ensure the consumers were keeping up), and the total end-to-end latency (time from a message sent to message receive).
Replica Fetcher Threads and Producer Acks
Some articles (e.g. Kafka Performance Tuning—Ways for Kafka Optimization, Producer Performance Tuning for Apache Kafka, Processing Trillions of Events per Day With Apache Kafka on Azure) suggest that Kafka cluster throughput can be improved by tuning the number of replica threads (the Kafka configuration parameter “num.replica.fetchers”).
This parameter sets the number of fetcher threads available to a broker to replicate the message. As the number of partitions increases there may be thread contention if there’s only a single thread available (1 is the default), so increasing the number of threads will increase fetcher throughput at least.
Configuration Values
For Instaclustr managed Kafka clusters this isn’t a parameter that customers can change directly, but it can be changed dynamically for a cluster, i.e. without node restarts. We will typically do this as part of a joint performance tuning exercise with customers. Customers can inspect configuration values that have been changed with the kafka-configs command:
./kafka-configs.sh --command-config kafka.props --bootstrap-server <kafka broker public IP>:9092 --entity-type brokers --entity-default --describe
Default config for brokers in the cluster are:
num.replica.fetchers=4 sensitive=false synonyms={DYNAMIC_DEFAULT_BROKER_CONFIG:num.replica.fetchers=4}
Increasing Fetcher Threads
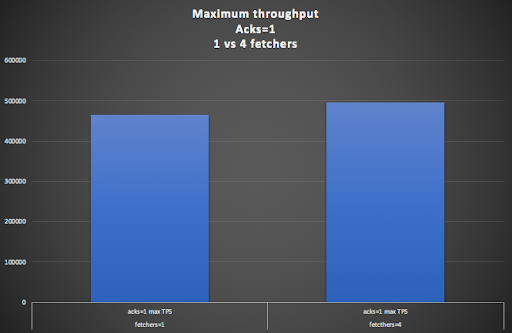
Starting with the default producer acks=1 setting, increasing the fetcher threads from 1 to 4 gave a slight increase (7%) in the throughput (8 or more fetchers resulted in a drop in throughput so we focused on 1 or 4). Latency ranged from a low of 7ms to 15ms at the peak throughput at both settings.
Comparing Different Settings
For comparison we also tried acks=all and the idempotent producer (in the producer set the “enable.idempotence” property to true) which ensures “exactly once” delivery (and which automatically sets acks=all). These two settings produced identical results so only the acks=all results are reported.
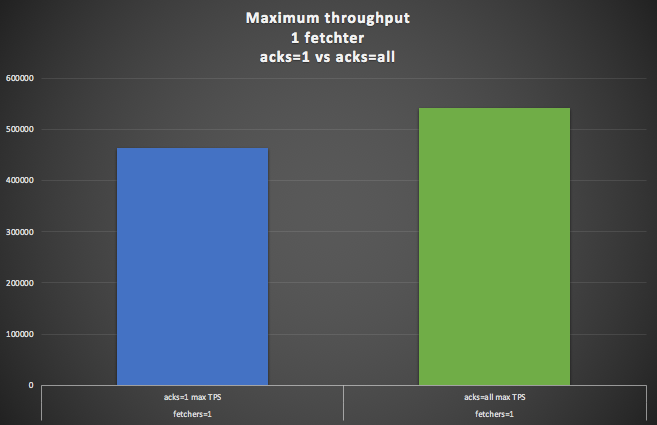
This graph compares the maximum throughput for acks=1 (blue) and acks=all (green) with 1 fetcher thread (the default). Suprisingly the acks=all setting gave a 16% higher throughput.
Latency at Maximum Throughput
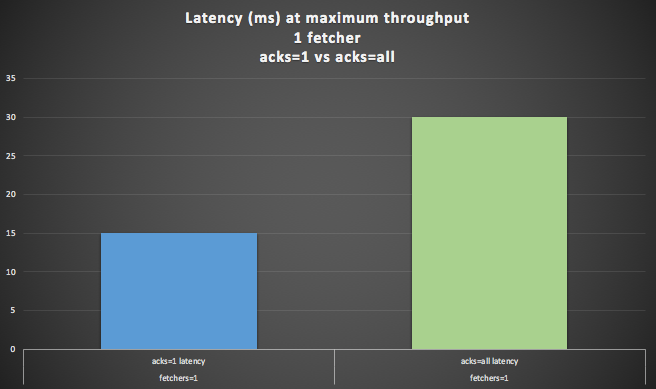
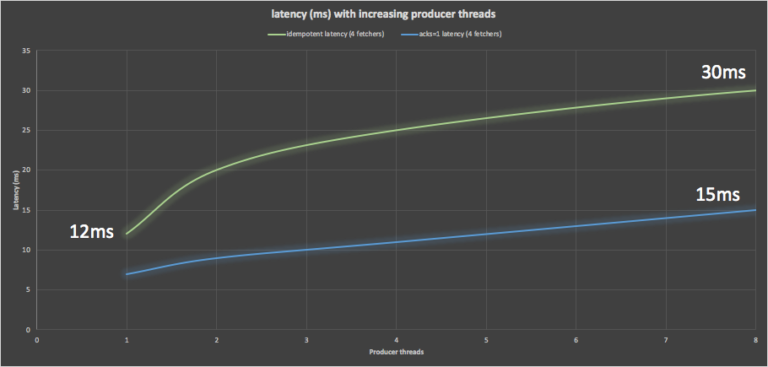
Less of a surprise (given that the producer waits for all the followers to replicate each record) is that the latency is higher for acks=all. The latency at the maximum throughput is double (30ms) that of the acks=1 setting (15ms).
This graph shows the maximum throughput for acks=1 (blue) and acks=all (green) with 1 and 4 fetchers. In practice, there wasn’t much difference in throughput between 1 and 4 fetchers for acks=all. Latencies were unchanged (i.e. latency of acks=all results were double the latency of acks=1 irrespective of fetcher threads).
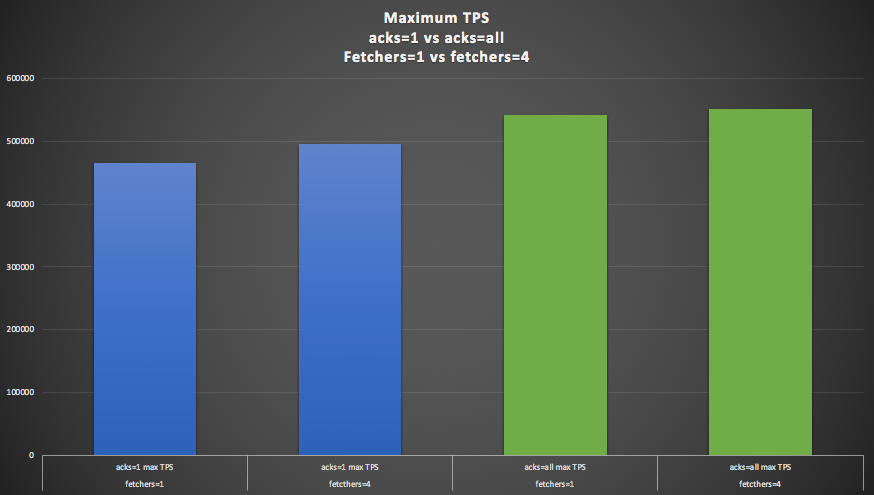
We were initially puzzled that throughput for acks=all was as good or better than with acks=1. It’s still not obvious how it can be better, but a reason that it should be comparable is that consumers only ever read fully acknowledged messages, so as long as the producer rate is sufficiently high (by running multiple producer threads) the end-to-end throughput shouldn’t be less with acks=all. Also note that as the Kafka producer is actually asynchronous, the impact of the acks setting doesn’t directly impact the producer throughput or latency (i.e. the writes are handled in the producer buffer which has separate threads).
We also tried changing the number of “min.insync.replicas” from the default of 1 to 3. However, this didn’t have any impact on the throughput. It turns out that changing the value only impacts durability and availability, as it only comes into play if a node gets out of sync, reducing the number of in-sync replicas and impacting how many replicas are guaranteed to have copies of the message and also availability (see below).
H2 7. Selecting the producer “acks” setting
How should you decide what producer acks settings out of the two that we tested (acks=1 or acks=all) to use? (note: acks=0 is also possible but it has no guarantee of message delivery if the leader fails).
You should set acks based firstly on your data durability and idempotency requirements, and then secondly on your latency requirements, and then lastly take into account throughput (as throughput can easily be increased with a bigger cluster). You can have both high durability and high throughput by using acks=all (or idempotent). Increasing the fetcher threads from 1 to 4 doesn’t have any negative impact and may improve throughput (slightly).
However, if you need low latency then acks=1 is hard to beat, although a lightly loaded cluster (e.g. < 50% CPU utilization) with acks=all may also work. This is because the lowest load acks=all result (green) had a similar latency (12ms) to the latency at the maximum load for the acks=1 result (blue, (15ms), but the latency increased rapidly to the reported 30ms at the maximum load.
You will also want to take into account availability when setting acks. With acks=1, writes will succeed as long as the leader partition is available, so for a RF=3, 3 node cluster, you can lose up to 2 nodes before writes fail. For acks=all, writes will succeed as long as the number of insync replicas is greater or equal to the min.insync.replicas. Acks=1 and Acks=All with min.insync.replicas=1 have the same availability (2 out of 3 nodes can fail), but as min.insync.replicas increases the availability decreases (1 node can fail with min.insync.replicas=2, and none can fail with 3).
The Impact of Acks
This handy table summarizes the impact of the producer acks settings (for RF=3) on Durability, Availability, Latency, and Throughput:
| Acks | min.insync.replicas | Durability | Availability | Latency | Throughput |
| 1 | any | Worst | Best | Best | Good |
| All | 1 | Worst | Best | Worst | Best |
| All | 2 | Good | Good | Worst | Best |
| All | 3 | Best | Worst | Worst | Best |
Writing Records to Partitions
Apache Kafka applications use the producer client to write records to a Kafka cluster—see the Apache producer documentation for further information. Since Kafka 2.4 the default behavior when there is no key has been to use the sticky partitioner. You can also create a custom partitioner like they did in this blog.
8. Conclusions
-
The optimal number of partitions (for maximum throughput) per cluster is around the number of CPU cores (or slightly more, up to 100 partitions), i.e. cluster CPU cores >= optimal partitions <= 100
-
Too many partitions result in a significant drop in throughput (however, you can get increased throughput for more partitions by increasing the size of your cluster).
-
At the optimal number of partitions (12 for our experiments), increasing num.replica.fetchers from the default of 1 to 4 doesn’t have a substantial impact on throughput or latency.
-
Setting producer acks=all can give comparable or even slightly better throughput compared with the default of acks=1.
-
Setting producer acks=all results in higher latencies compared with the default of acks=1.
-
Both producer acks=all and idempotence=true have comparable durability, throughput, and latency (i.e. the only practical difference is that idempotence=true guarantees exactly once semantics for producers).
Related Guides:
-
Apache Kafka: Architecture, deployment and ecosystem [2025 guide]
-
Complete guide to PostgreSQL: Features, use cases, and tutorial
Related Products:
Accelerate your Kafka deployment.