Request Latency
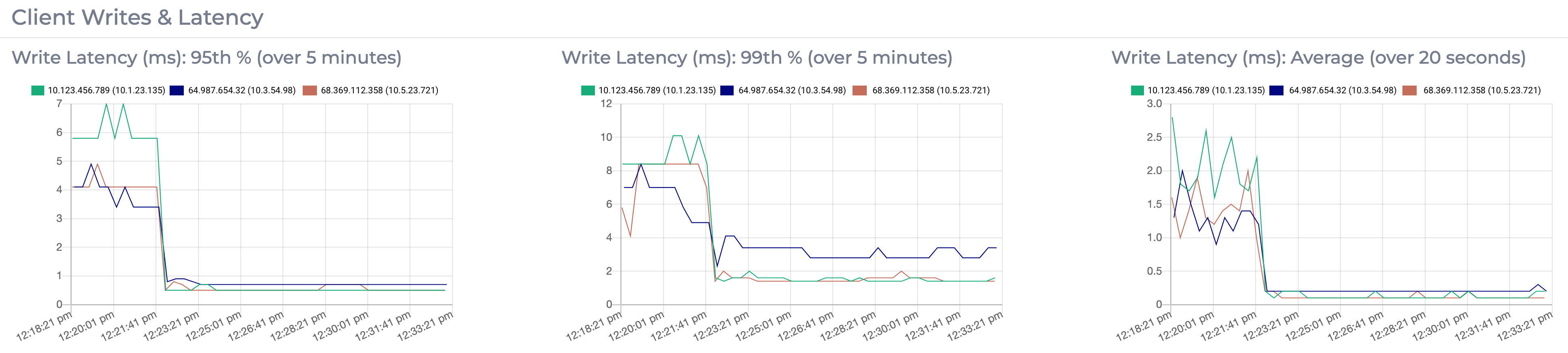
(Read or write) request latency is time to complete an operation as reported by the coordinator node. It’s the time taken between the client read or write request being received, to contacting the right replicas across the network and returning the data requested to the client.
Note: p95 is a 5-minute decaying statistic. Average is calculated over the 20 seconds between metrics collections and will be more volatile.
There are many potential causes of high request latency, such as cluster overload, a node falling behind in compactions and Cassandra having to read many SSTables in a read, high levels of tombstones or overly large partitions.
If you are concerned about high request latencies on your cluster, feel free to contact Instaclustr Support.