The annual 2020 Kakfa summit went ahead this year (August 24-25), but this time in a virtual format. This turned out to be a good thing for me as I’m in the wrong time zone to watch the talks live, so I could take my time after the summit to catch up. Actually, this format was a natural fit for an Apache Kafka conference, given that Kafka is a distributed large-scale publish-subscribe loosely-coupled message processing system!
All the Talks I Watched
There were 97 talks, given by 104 presenters. Many of the more technical talks were given by Confluent presenters (32), but there were also lots of Case Studies presented by other companies and organizations which made for more variety in perspective and theory vs. practice (but you do have to watch out for what’s really Open Source Apache Kafka vs. other more restrictive source licences or even closed source). If you have limited time, the lightning talks are short but still worth watching.
Here’s the selection of talks I watched:
- IMQTT and Apache Kafka: The Solution to Poor Internet Connectivity in Africa, Fadhili Juma (Remitly)
- Flattening the Curve with Kafka, Rishi Tarar (Northrop Grumman Corp.)
- Marching Towards a Trillion Kafka Messages Per Day: Running Kafka at Scale at PayPal [Lightning], Maulin Vasavada (PayPal)
- Tradeoffs in Distributed Systems Design: Is Kafka The Best? Ben Stopford and Michael Noll (Confluent)
- KafkaConsumer—Decoupling Consumption and Processing for Better Resource Utilization, Igor Buzatović (Inovativni trendovi d.o.o)
- Apache Pinot Case Study: Building Distributed Analytics Systems Using Apache Kafka, Neha Pawar (Stealth Mode Startup)
- Getting up to Speed with MirrorMaker 2, Mickael Maison (IBM), Ryanne Dolan
- Building a Modern, Scalable Cyber Intelligence Platform with Kafka [Lightning], Jac Noel (Intel)
- Building a Data Subscription Service with Kafka Connect, Danica Fine and Ajay Vyasapeetam (Bloomberg)
- A Tale of Two Data Centers: Kafka Streams Resiliency, Anna McDonald (Confluent)
- Redis and Kafka—Advanced Microservices Design Patterns Simplified [Sponsored], Allen Terleto (Redis Labs)
- Kafka ♥ Cloud, Jay Kreps (Confluent)
So, even though I only watched 12 out of a total of 97 possible talks, sampling approaches can often give good insights into the whole. For example, famous computer scientist Professor Donald Knuth used a “stratified sampling” approach to understand the Bible, by examining only one (and the same) Chapter (3) and verse (16) for every book. My sampling technique wasn’t as systematic as this, and I just watched talks that I thought looked interesting.
In this blog, I’ll focus on the first three talks from the list, which were some of the more impressive Apache Kafka use cases from the summit.
1. MQTT and Apache Kafka: The Solution to Poor Internet Connectivity in Africa—Fadhili Juma (Remitly)

Fadhili gave an inspirational presentation based on a challenging use case, motivating an elegant combination of Open Source messaging technologies. First the problem: You are a parent of school age children living in a remote rural village in Tanzania. To pay for school fees you use microfinance banks, but the only way to access them is via third-party providers using mobile terminals, and you have to get a receipt to give to the school as proof of payment. Not surprisingly there are some complications, particularly the need for disconnected operation resulting from intermittent/slow internet connectivity (over 2G phone networks) and power outages (terminals are battery powered and often run out of power, servers loose power), and resource constrained devices (terminals and servers). However, given that these are financial transactions you still need high levels of QoS, and the ability to get a receipt, potentially after multiple disconnections in the transaction path.
They initially started out by using HTTP to connect the terminals with the banking back-end systems. This didn’t work well given the above constraints, so they moved to MQTT, which did! Fadili gave a detailed technical explanation of why MQTT was a good fit. It works with poor connectivity and low power devices because it’s lightweight (e.g. low overhead protocol, length prefixed strings are easy to parse), and supports 1000s of edge connections (so more than enough for 100’s of terminals), 1000s of dynamic topics, buffering, auto reconnection, persistent sessions (so that client connected data is stored on the MQTT broker, avoiding reconnections and reducing sessions and handshakes), has a “last will and testament” message (so easy to discover which devices have failed), and retains messages, which is important as it allows receipts to be produced even after terminal failure. It also supports multiple QoS levels, and they use QoS level 1—at least once—which ensures reliable delivery with the least overhead (with duplicates handled by the application).
But this is only half the story. Given the financial nature of the transactions, and the need to integrate the edge systems with other banking systems, they chose Apache Kafka to complement MQTT to provide the missing durability and integration. The resulting architecture had many terminals connected via a load balancer to three MQTT brokers, which were integrated with Kafka using a MQTT-Kafka Connector (here’s an example Open Source MQTT-Kafka Connector, and an Open Source MQTT Broker). There was a long journey from the terminal devices, via MQTT to Kafka, then validation and finalizing transactions using stream processing, and ultimately producing and delivering a receipt back to the terminal that initiated the transaction, all over intermittent networks and devices.
But how did they send the receipt back to the originating terminal in the village? This is where MQTT came back into play. Kafka isn’t designed for 1000s of topics or sending replies back to edge devices (which is common in IoT use cases). MQTT enabled them to have a dedicated topic for each terminal, with the receipt being delivered from a single Kafka topic to the originating terminal’s topic in MQTT, for subsequent delivery to the parent and thus the school—making for a potentially long but eventually reliable roundtrip.
In the future, they plan to move the MQTT and Kafka clusters to the cloud. Instaclustr Managed Kafka (on multiple clouds and locations) would be a good solution, and we also offer Managed Kafka Connect, with Bring Your Own Connectors, enabling customers to run Open Source connectors (e.g. Kafka-MQTT) in a reliable cloud environment.
2. Flattening the Curve with Kafka—Rishi Tarar (Northrop Grumman Corp.)
Rishi’s talk addressed another challenging problem, but at a continental scale—racing to introduce the USA’s Centers for Disease Control (CDC) COVID Electronic Lab reporting to beat the COVID-19 outbreak. The challenge was to collect all the states and territories COVID testing events, and make the results available to federal customers. The system had to work in real-time and be ready as soon as possible. Eventually it only took them 30 days to have a fully functioning real-time pipeline for the COVID pathogen. Similar to the previous Kafka use case, there are a lot of steps to get from a pop up test site to the final data consumers, and data continuity and provenance are critical in order for the results to be trustworthy.
Apache Kafka was the obvious choice of technology, and enabled them to receive testing event data from multiple locations, formats, and protocols, integrate, and then process the raw events into high quality multiple consumable results. Kafka streams processing was used to handle steps such as validation, transformation, translation, management of data policy, and governance etc.
The most difficult challenge wasn’t technical per se, but the rapid rate of development. Rishi emphasised that “Future state is a Mirage – Transition state is Reality”—the architecture needed to be able to “drift” but keep on delivering results. Kafka enabled them to rapidly deploy infrastructure, ingest, and integrate 100s of data sources, and implement streams processing pipelines and multiple federal consumer portals, all within 30 days, continue to make agile changes every few days, and deliver data and analysis products in real-time.
Here’s an example of one of the better known products, the public-facing CDC COVID data tracker:
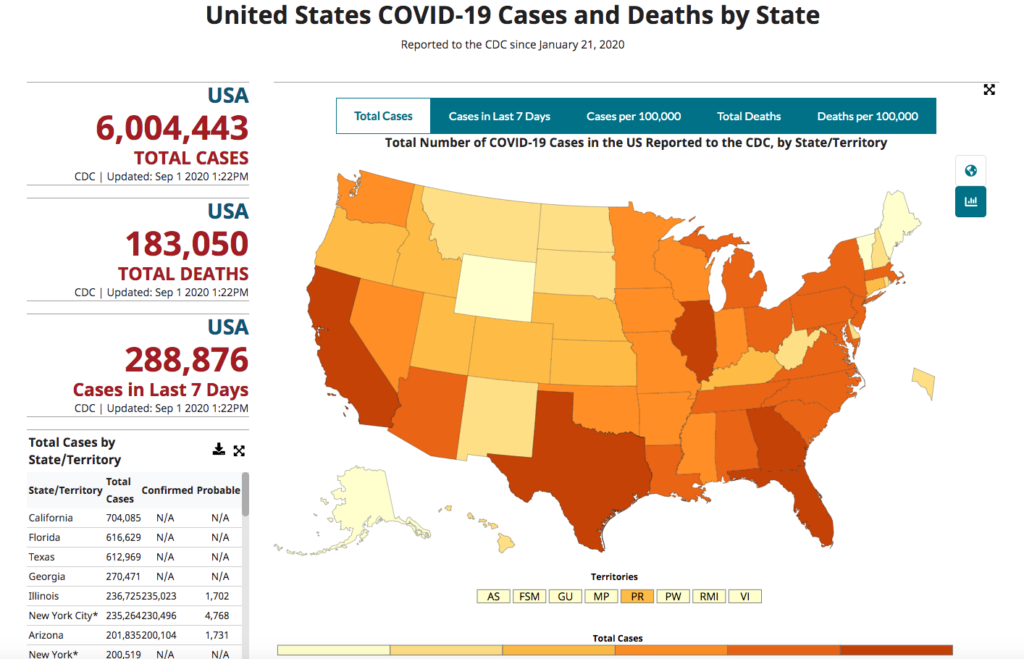
Coincidentally one of Instaclustr’s consultants focused on the same problem and technology stack and built a demonstration Open Source Big Data workbench for public COVID-19 data analysis and visualization. The code is available here
3. Marching Towards a Trillion Kafka Messages Per Day: Running Kafka at Scale at PayPal [Lightning]—Maulin Vasavada (PayPal)
Like the first Kafka use case, Paypal is also a FinTech company, but facing different challenges due to the massive scale of running a large fleet of global Kafka clusters (50+ Kafka clusters, 5k+ topics, 7PB of data) processing close to a Trillion Kafka messages a day (900 Billion a day and growing). Maulin gave a lightning talk so there wasn’t much time for detail, but the big picture was impressive. One of the key technical challenges they face is managing a polyglot client stack and ensuring high client resilience. To do this they use cluster abstraction implemented by a client-side library/proxy and a client configuration service. This keeps track of meta-data about Kafka clusters, topics, and partitions, and allows for topic shuffling and management of consumer/topic rebalancing. In common with most other use cases for Kafka, they also rely on the rich ecosystem of complementary Open Source technologies (e.g. Elasticsearch, Kibana, Apache Storm, Apache Spark, Apache Hadoop, etc.), and Kafka connectors for seamless integration.

I’m also in the process of building a demonstration low-latency globally distributed FinTech application (a stock broker) which explores some of the issues around latency and reliability at global scale (part 1, part 2, part 3)
And if, like Paypal, you are trying to run Kafka clusters yourself, why not investigate Instaclustr’s Managed Kafka and let us deal with all the operational complexity for you. Instaclustr’s Hosted Managed Service for Apache Kafka® is the best way to run Open Source Kafka in the cloud, providing you with a production-ready and fully supported Apache Kafka cluster in minutes. Our fully hosted and managed solution frees you to focus on your applications. Start your free trial now!
That’s all for this blog on Apache Kafka use cases, next blog I’ll take a look at some of the more interesting Kafka technology developments from the summit.