






















In Part 1 and Part 2 of this blog series we started a journey building a real-time pipeline to acquire, ingest, graph, and map public tidal data using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana. In this blog, we resume that journey and take an Apache “Camel” (Kafka Connector) through the desert (or the Australian Outback) to see if it is more or less robust than the connectors we previously tried.
1. Apache Camel Kafka Connectors
While driving along Outback roads in Australia you will inevitably come across wildlife warning signs! This one is a bit different from the norm. From right to left it’s telling you to watch out for kangaroos, guinea pigs? (actually Wombats which can weigh up to 35 kilograms or nearly 80 pounds), and the “odd one out”, camels! Camels are not native to Australia but were imported in large numbers as they are well adapted to desert transportation. Deserts make up around 35% of Australia, and camel trains were critical for opening up the Outback and connecting isolated communities. One of Australia’s most famous railways is named The Ghan in commemoration of the original Afghan camel drivers.

While looking for other Kafka talks at the recent ApacheCon@Home 2020 conference, I ran into Apache Camel (there were no warning signs) via the talk “Camel Kafka Connectors: When Camel Meets Kafka” (all 303 ApacheCon videos are available here; I gave two presentations on Kafka, one of which was recorded, so I was curious to see what else was happening in the Apache Kafka world).
This talk introduced me to both the top-level Apache Camel project (which I had heard of, but didn’t know much about) and the Apache Camel Kafka Connector sub-project (CKC for short). Apache Camel is a mature Apache project (over 10 years old), while the CKC sub-project is around a year old. Camel appears to have a unique role in the Apache Software Foundation ecosystem, as it’s focused on integration. Camel seems like a logical name for a project focused on integration—Camels are good at carrying heavy loads through harsh terrains, although they have a reputation for being bad-tempered!
Since there has been more than one computer in existence (or more than one computer manufacturer, which resulted in divergences such as the way bytes are stored in a computer word—Endianness), integration has been a critical and genuinely difficult problem to solve. However, integration often misses out on the attention given to more vertically focused domains, so it was encouraging to see a sustained level of interest in integration at ApacheCon this year.
CAMEL stands for Concise Application Message Exchange Language. Apache Camel is an open source Java framework that is focused on ease of integration. It provides concrete implementations of the Enterprise Integration Patterns (EIPs) via a combination of:
- Camel endpoints (for sending/receiving messages across different transports),
- Camel processors (to wire endpoints together with routing, transformation, mediation, interception, enrichment, validation, tracking, logging, etc.), and;
- Camel components (which act as a uniform endpoint interface and connectors to other systems).
Here’s the official Camel architecture diagram:
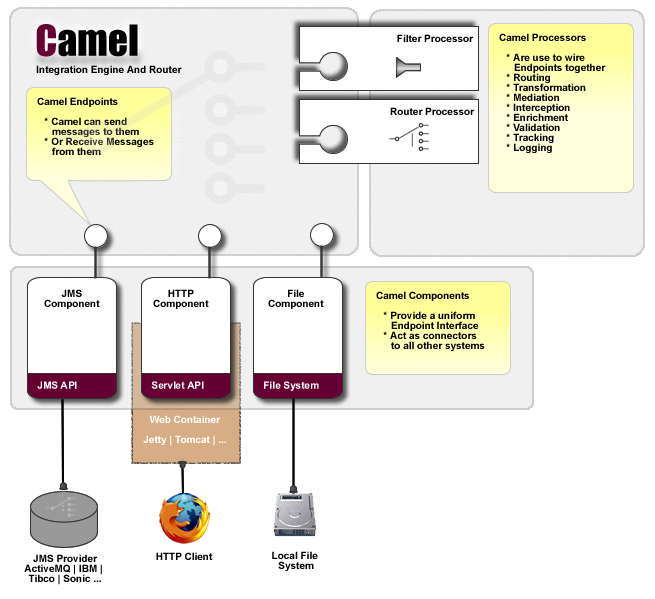
A component is a factory and manager of endpoints. Components can be used on their own or combined together, and are designed to make it easy to drop in new functionality. I was astonished to discover that there are about 355 Camel components, of which 346 are available as CKC connectors, making it by far the largest collection of open source Kafka connectors in existence.
How Did the CKC Sub-Project Get This Many Kafka Connectors?
Basically by being clever and leveraging the existing Camel components and available metadata. In fact, the CKC connectors (and the documentation) are automatically generated from the components, so there is a one-to-one relationship between components and connectors. If a Camel component supports the (Camel) consumer and producer then you’ll have both Kafka source and sink connectors, or else just one of the connector types. And some components are missing if they don’t make sense as Kafka connectors. The CKC configuration files also contain a mixture of Kafka connector configuration and Camel specific configuration.
Differences and Synergies Between Apache Camel Kafka Connector and Apache Kafka
Given that Apache Kafka was invented to solve an integration problem (at Linkedin), and Apache Camel is also focused on integration, there are differences and potential synergies.
Apache Camel focuses on routing and mediation and is designed to work in conjunction with a robust, scalable, messaging infrastructure. Obviously Kafka is a good choice to provide robust messaging, and there is in fact a Camel Kafka component. From this perspective, with Camel running in one of many supported run-time environments (basically, anywhere Java runs), Kafka enables reliable distributed message delivery for Camel; and Camel enhances Kafka, as you can then use any of the Camel functionality to perform complex message transformation, filtering, routing etc., which Kafka doesn’t support out of the box, as the Kafka broker can’t access message contents. Kafka is basically a simple, but highly scalable, topic-based pub-sub message broker.
On the other hand, using CKC with Kafka is more focused on providing Camel functionality as pre-generated Kafka connectors. Being Kafka connectors, they will just run in a Kafka connector cluster, so you don’t need a separate run-time. However, only a subset of the Camel functionality is available in the pre-generated connectors via Kafka connector configuration. But the source code can be extended to build custom connectors to include more Camel functionality (e.g. via aggregation and archetypes).
Enough of the theory, it’s time to saddle up a Camel (Kafka Connector) and take it for a ride.

2. Configuring the Camel Kafka Elasticsearch Sink Connector
Given my mixed experiences in the previous blog with the robustness of some Elasticsearch sink connectors, I was eager to see how the Camel Kafka Elasticsearch sink connector compared.
In the Camel Kafka connectors list, there is just one option for Elasticsearch, the sink connector (documentation, and zipped jars). When you unzip it you get an example configuration file (which isn’t complete) and lots of jar files. Following our instructions on how to make custom connectors available in Instaclustr’s managed Kafka connector cluster (via AWS S3 in this case), and resyncing running connectors from our Kafka Connect GUI console, you get three new Camel connectors. Two of them appear to be generic Camel source and sink connectors, including the one we want:
|
1 2 |
org.apache.camel.kafkaconnector.elasticsearchrest.CamelElasticsearchrestSinkConnector |
Because the Camel Kafka connectors and the associated documentation are autogenerated from the Camel components, the CKC documentation isn’t 100% complete. For example, it doesn’t include generic Kafka Connect config fields, and the “required” fields are ambiguous (e.g. as in Camel values can be passed as headers or properties), so you also have to consult the associated Camel component documentation (in this case, the Camel Elasticsearch Rest Component).
Similar to my previous experiences, debugging the Kafka Connect configuration is a matter of trial and (lots of) error. The error messages can be somewhat cryptic (given that they are mostly Camel errors) but can be found in the Kafka Connect error logs topic.
Here’s the final Kafka Connect configuration that worked correctly (note that it uses “PUT” to create or update an existing connector, so the connector name is in the URL rather than the body):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
curl https://ip:port/connectors/camel-elastic-stocks20p/config -k -u user:password -X PUT -H 'Content-Type: application/json' -d ' { "connector.class" : "org.apache.camel.kafkaconnector.elasticsearchrest.CamelElasticsearchrestSinkConnector", "tasks.max" : 1, "topics" : "tides-topic", "camel.sink.endpoint.operation" : "Index", "camel.sink.endpoint.indexName" : "tides-index", "camel.sink.path.clusterName" : "elasticsearch", "camel.sink.endpoint.hostAddresses" : "ip:port", "camel.component.elasticsearch-rest.user" : "user", "camel.component.elasticsearch-rest.password" : "password", "errors.tolerance": "all", "errors.deadletterqueue.topic.name" : "camel-elastic-deadletter", "errors.log.enable" : "true", "errors.log.include.messages" : "true", "value.converter.schemas.enable": "false", "value.converter": "org.apache.kafka.connect.json.JsonConverter" }' |
Note that the “clusterName” is a Camel convention for naming Camel endpoints, and is required (but can be any name). The mandatory fields include the class, topics, indexName, operation (the connector supports multiple Elasticsearch operations), and hostAddresses.
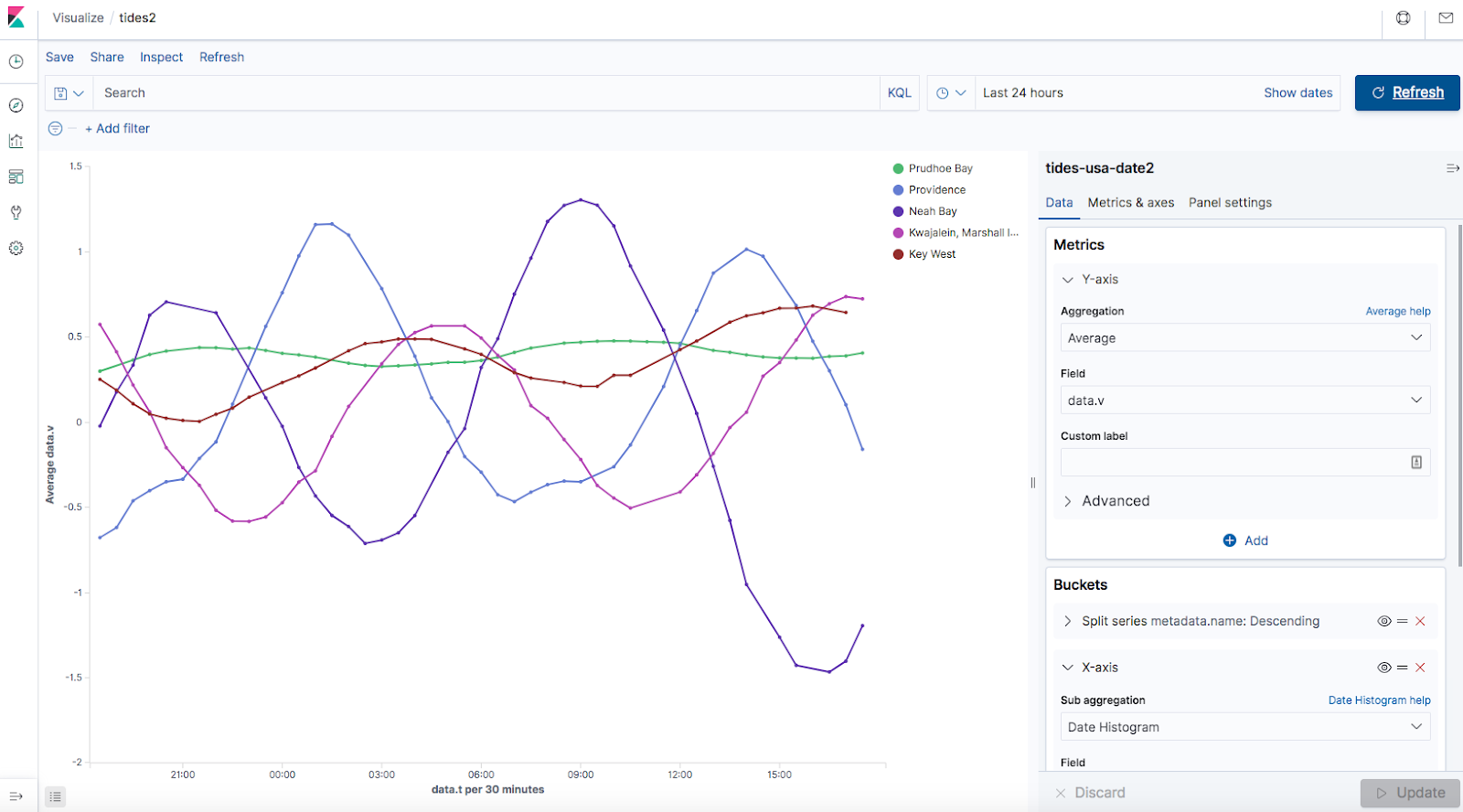
How do we know that the new Camel Kafka connector is actually working? We can again easily see our familiar tidal data (high and low tides, and 24 hour minute 50 day “lunar day” periods) flowing into Kibana as this screenshot shows:
3. Camel Kafka Connector (CKC) Elasticsearch Sink Error Handling
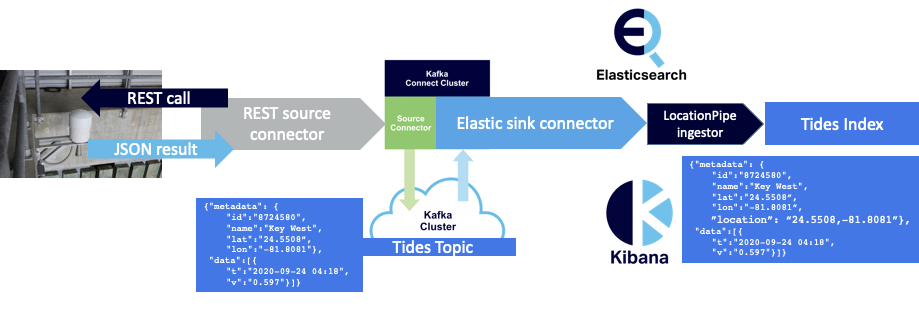
One of the reasons I wanted to try out the CKC Elasticsearch sink connector was to check if it does error handling better than the alternatives I had tried previously. After configuring and starting the connector, it appeared to be working reliably and was sending events to the Elasticsearch index. But was it actually more robust? To recap, the REST API I’m getting the data from (via a REST source connector) can return three different payloads as follows:
(1) JSON with metadata and data:
|
1 2 3 4 5 6 7 8 9 |
{"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} |
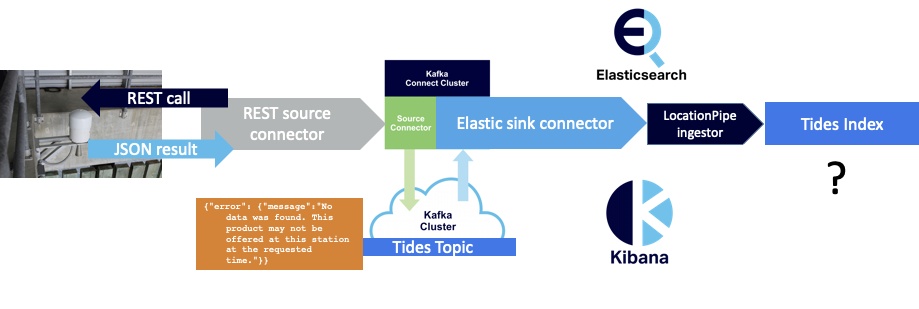
(2) JSON with an error message:
|
1 |
{"error": {"message":"No data was found. This product may not be offered at this station at the requested time."}} |
(3) Or an HTTP 502 Bad Gateway (HTML) error message:
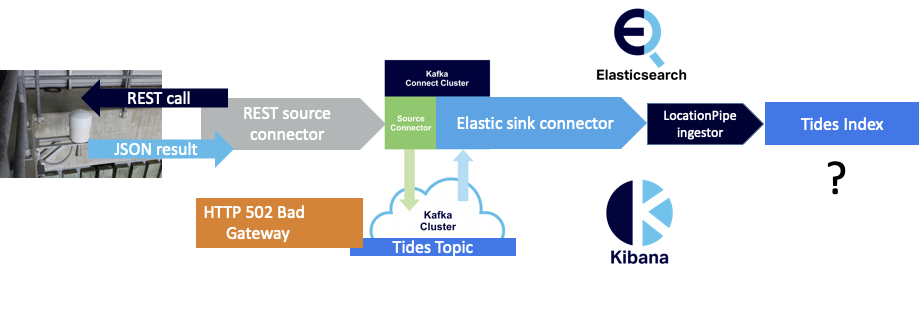
The open source Elasticsearch connector I previously tried FAILED whenever it encountered an HTTP error message (3), which wasn’t very robust behavior. This time around, the CKC Elasticsearch sink connector continued to work, sent the HTTP error message to the dead letter queue, and skipped to the next record as follows:
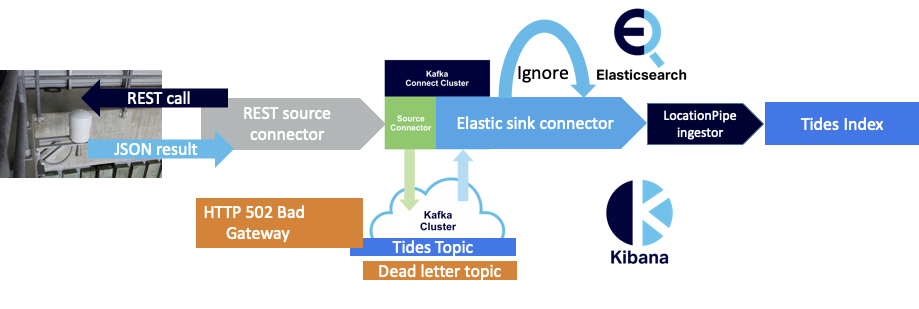
However, on closer examination, it appeared that there was still a problem with the way that JSON error messages (2) are handled by the pipeline. Even though they don’t cause an exception, they are just processed as “normal” JSON and sent to Elasticsearch for indexing, which it does without complaint. This means we end up with error messages in our index:
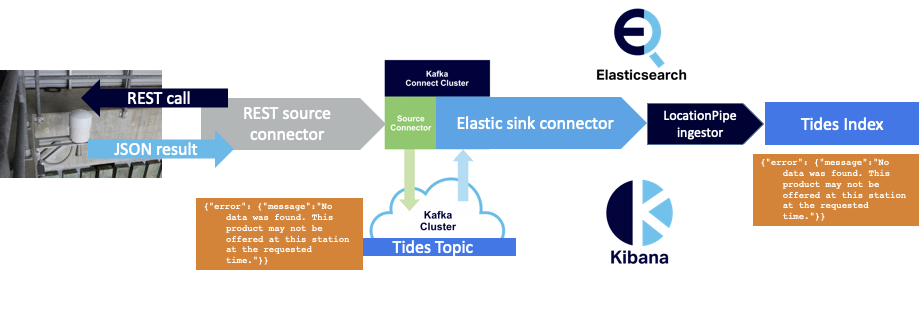
How could this be avoided?
It turns out that Elasticsearch has the ability to (sort of) do schema validation on incoming documents and throw an error if they don’t conform to an explicit index mapping (actually all it does is refuse to add new fields). The dynamic setting controls whether new fields can be added dynamically to an index or not, and the setting we want is “strict” (never).
So the final Elasticsearch index mapping we end up with for our tidal data index is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
curl -u elasticName:elasticPassword ”elasticURL:9201/tides-index" -X PUT -H 'Content-Type: application/json' -d' { "mappings" : { "dynamic" : "strict", "properties" : { "data" : { "properties" : { "t" : { "type" : "date", "format" : "yyyy-MM-dd HH:mm" }, "v" : { "type" : "double" }, "f" : { "type" : "text" }, "q" : { "type" : "text" }, "s" : { "type" : "text" } } }, "metadata" : { "properties" : { "id" : { "type" : "text" }, "lat" : { "type" : "text" }, "long" : { "type" : "text" }, "location" : { "type" : "geo_point" }, "name" : { "type" : ”keyword" } }}}} }' |
Does this work? Yes and no. On the Elasticsearch side of things, as the index mapping doesn’t contain an “error” field, an exception is thrown and the defective record is not indexed.
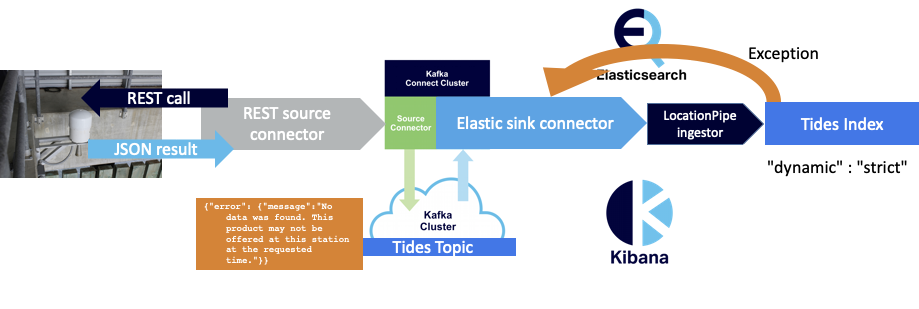
Unfortunately, the connector then goes to a FAILED state:
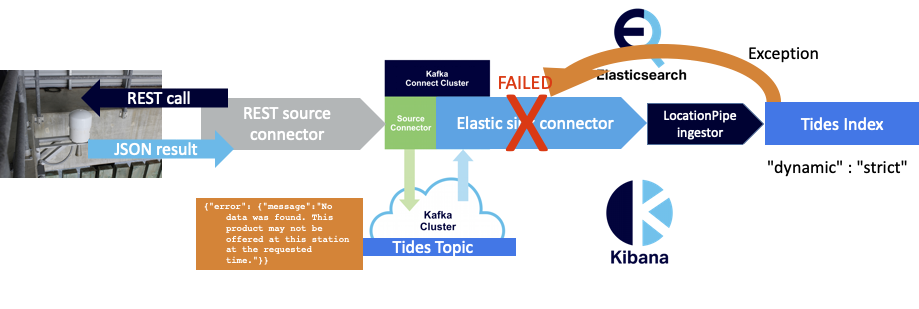
So either the default Kafka Connect error handling doesn’t cover sink errors, I haven’t correctly configured the Camel Kafka Elasticsearch sink connector to handle sink errors, or the current implementation doesn’t handle sink errors.
Talking with the Camel Kafka Connect team, it turns out that they are working on incorporating native Camel error handling capabilities into CKC, so future versions are likely to be even more robust. They are also working on more complete documentation and examples which will help with understanding how to configure connectors in the future. In the meantime I had to revert to the previous Elasticsearch mapping (without the dynamic strict property).
This doesn’t significantly impact the robustness of the pipeline, as the error documents can be filtered out in Elasticsearch. But we’ll stick with using the Apache Camel Kafka Connector for our pipeline, as it’s more robust than other open source sink connectors, particularly for handling input errors.
4. Conclusions
In this blog, we eventually made it across the desert/Outback by Camel, processed tidal data with a CKC Elasticsearch Sink Connector, and reached the sea!

Given the vast number of CKC connectors available, it’s likely that you can find one that meets your Kafka Connect integration needs. And you don’t need an extra run-time, as they happily run in a Kafka Connect cluster. From my limited experience so far (a sample of one from 346!), the Camel Kafka connectors are well-documented (if you look in all the right places) and are more robust than some other open source connectors (and least for handling input record format errors), and at least as robust as some commercial connectors. In theory, you can also customize them to include even more Camel functionality.
However, before you make a final choice of connectors and run them in production, I recommend that you test them out and ensure they have the exact functionality and error handling required for your specific use case, as connectors (even for the same sink technology) from different developers are not identical.
Next, in Part 4 and Part 5 of this pipeline blog series, we race some Camels! We see how to monitor the Kafka Connect pipeline end-to-end, increase the data arrival rate, and scale-up the number of connector tasks.
5. Further Resources
- Apache Camel
- Apache Camel Kafka Connect (CKC)
- Connectors List
- ApacheCon @Home 2020 Camel Track videos
- Instaclustr Managed Kafka Connect
Follow the Pipeline Series
- Part 1: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 2: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 3: Getting to Know Apache Camel Kafka Connectors
- Part 4: Monitoring Kafka Connect Pipeline Metrics with Prometheus
- Part 5: Scaling Kafka Connect Streaming Data Processing
- Part 6: Streaming JSON Data Into PostgreSQL Using Open Source Kafka Sink Connectors
- Part 7: Using Apache Superset to Visualize PostgreSQL JSON Data
- Part 8: Kafka Connect Elasticsearch vs. PostgreSQL Pipelines: Initial Performance Results
- Part 9: Kafka Connect and Elasticsearch vs. PostgreSQL Pipelines: Final Performance Results
- Part 10: Comparison of Apache Kafka Connect, Plus Elasticsearch/Kibana vs. PostgreSQL/Apache Superset Pipelines