What are open source LLMs?
Large Language Models (LLMs) are machine learning models that can understand and generate human language based on large-scale datasets. Unlike proprietary models developed by companies like OpenAI and Google, open source LLMs are licensed to be freely used, modified, and distributed by anyone. They offer transparency and flexibility, which can be particularly useful for research, development, and customization in various applications.
Researchers and developers can access the underlying code, training mechanisms, and datasets, enabling them to deeply understand and improve these models. This openness fosters a community-driven approach to innovation, which can lead to rapid advancements not possible with closed source models.
This is part of a series of articles about open source AI.
Open source vs closed source LLMs
Open source LLMs are fully accessible for anyone to use, modify, and distribute (although some models require prior approval to use, and some might restrict commercial use of the model). This transparency allows for extensive customization and examination, enabling users to adapt the models to their needs. Open source models offer more freedom, often requiring less financial investment and enabling users to mitigate vendor lock-in risks.
Closed source LLMs are proprietary, with restricted access to the code, training methods, and datasets, limiting user control and customization. Closed source LLMs often provide improved performance and capabilities due to significant resources invested by their creators. However, this comes at a cost—both literally and figuratively. Commercial models are typically priced per token, which can be significant for large-scale usage, and users are dependent on the vendor for updates and support.
Benefits of using open source LLMs
Open source large language models offer several advantages:
- Enhanced data security and privacy: Users have full control over the data processed by these models, eliminating concerns of third-party access or data mishandling. Organizations can deploy open source LLMs on their private infrastructure, ensuring sensitive information remains in-house and complies with data protection requirements.
- Cost savings and reduced vendor dependency: Since the code and models are freely available, organizations save on pay-per-use and licensing fees and can allocate resources toward customizing and optimizing the models to meet their needs. They can also avoid vendor lock-in scenarios where they are tied to a specific provider for updates, support, and future developments.
- Code transparency: Users have full visibility into the model’s architecture, training data, and algorithms. This transparency fosters trust and enables detailed audits to ensure the model’s integrity and performance. Developers can modify the code to fix bugs or improve features.
- Language model customization: Organizations can tweak the models to better suit their requirements, from adjusting the training processes to incorporating domain-specific knowledge. With closed source models, customization is often limited and might require special permissions and additional costs.
Tips from the expert

Sharath Punreddy
Solution Architect
Sharath Punreddy is a Solutions Engineer with extensive experience in cloud engineering and a proven track record in optimizing infrastructure for enterprise clients
In my experience, here are tips that can help you better leverage open source large language models (LLMs):
- Optimize for hardware compatibility: While deploying LLMs, ensure you tailor model configurations to leverage the specific capabilities of your hardware, such as GPUs or TPUs, to achieve maximum efficiency.
- Utilize model quantization: Implement quantization techniques to reduce model size and computational requirements without significantly compromising performance, making deployment on edge devices feasible.
- Fine-tune with domain-specific data: Enhance the relevance and accuracy of LLMs by fine-tuning them with data specific to your industry or application domain, improving their contextual understanding and performance.
- Integrate with complementary tools: Combine LLMs with other AI tools such as vector databases for improved search capabilities or knowledge graphs for enhanced reasoning and contextualization.
- Implement differential privacy: Apply differential privacy techniques to ensure that the model does not inadvertently expose sensitive information from the training data, enhancing data security.
Top open source LLMs in 2024
1. LLaMA 3
![]()
Meta developed the LLaMA 3 family of large language models, which includes a collection of pretrained and instruction-tuned generative text models available in 8 billion (8B) and 70 billion (70B) parameter sizes. These models are optimized for dialogue use cases, such as in conversational AI applications.
Project information:
- License: Meta Llama 3 community license
- GitHub stars: 23.3K
- Contributors: Joseph Spisak et. al.
- Main corporate sponsor: META
- Official repo link: https://github.com/meta-llama/llama3
Features:
- Model sizes: Available in two sizes: 8 billion (8B) and 70 billion (70B) parameters.
- Context window: Earlier version of Meta LLaMA had a context window of 8K tokens. Version 3.2 upgraded this to 128K tokens.
- Input and output: These models accept text input and are capable of generating both text and code, making them versatile for various applications such as content creation, code generation, and interactive dialogue.
- Architecture: Uses an optimized transformer architecture, which enhances the model’s ability to understand and generate human-like text.
- Tokenizer: Uses a tokenizer with a vocabulary of 128,000 tokens, which helps in efficiently processing and understanding diverse text inputs.
- Training procedure: Trained on sequences of 8,192 tokens, utilizing Grouped-Query Attention (GQA) for improved inference efficiency, allowing the models to handle longer contexts.
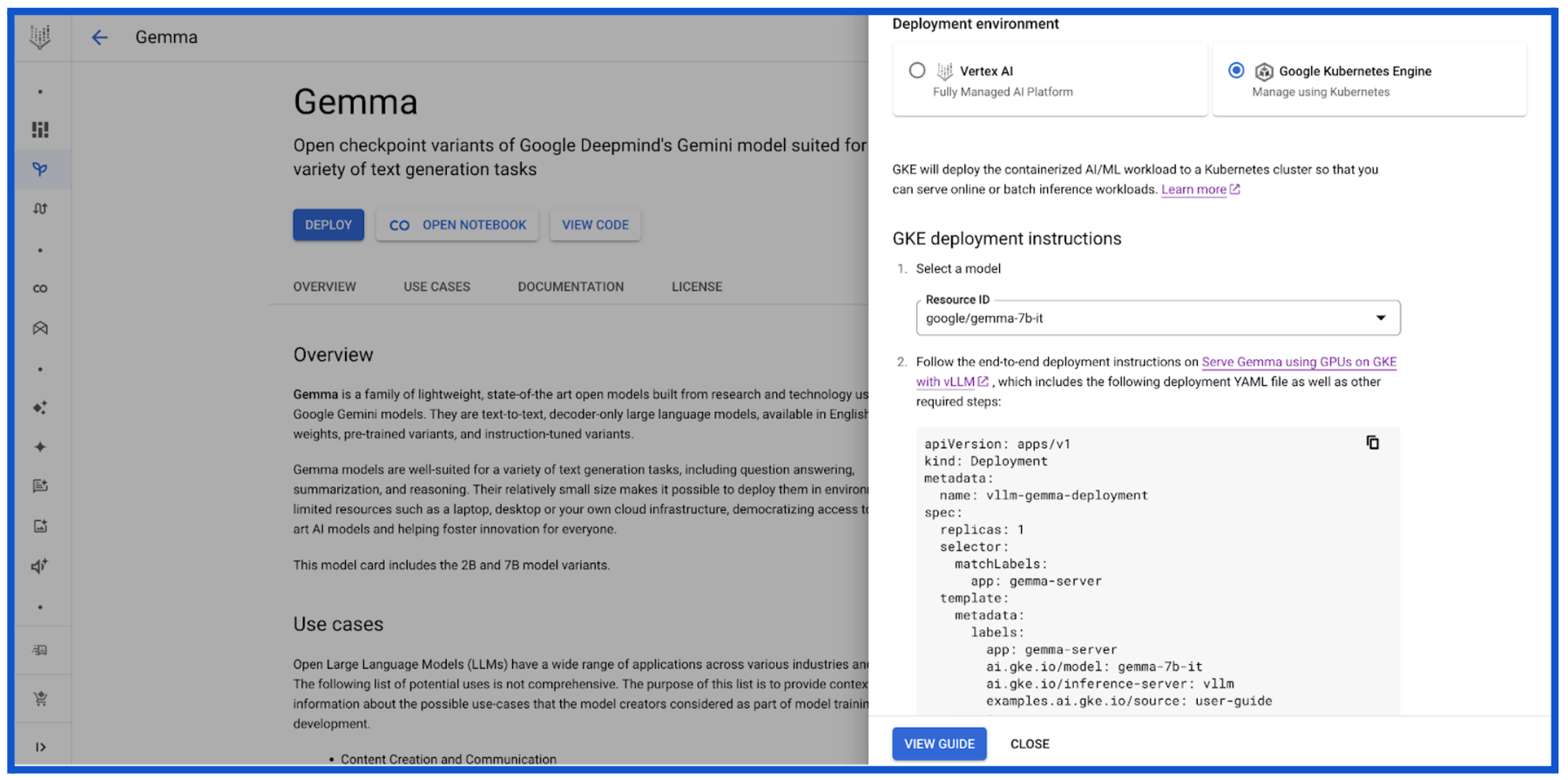
2. Google Gemma 2
![]()
Google DeepMind released Gemma 2, the latest addition to their family of open models designed for researchers and developers. Available in 9 billion (9B) and 27 billion (27B) parameter sizes, Gemma 2 models run at high speeds across different hardware platforms and integrate with popular AI tools.
Project information:
- License: Apache 2.0
- GitHub stars: 5.2K (PyTorch implementation)
- Main corporate sponsor: Google
- Official repo link: https://huggingface.co/google/gemma-2b
Features:
- Model sizes: Available in 9B and 27B parameters, providing options for various computational needs and performance requirements.
- Context window: Gemma 2 has a context window of 8K tokens.
- Performance: According to benchmarks, the 27B model delivers performance similar to models more than twice its size.
- Efficiency: Designed for efficient inference, the 27B model runs on single TPU hosts, NVIDIA A100 80GB Tensor Core GPUs, or NVIDIA H100 Tensor Core GPUs, reducing costs while maintaining high performance.
- Hardware compatibility: Optimized for fast inference across a range of hardware, from gaming laptops to cloud-based setups. Users can access the models in Google AI Studio or use the quantized version with Gemma.cpp on CPUs.
- Integration: Compatible with major AI frameworks like Hugging Face Transformers, JAX, PyTorch, and TensorFlow via Keras 3.0, vLLM, Gemma.cpp, Llama.cpp, and Ollama. It also integrates with NVIDIA TensorRT-LLM and is optimized for NVIDIA NeMo.
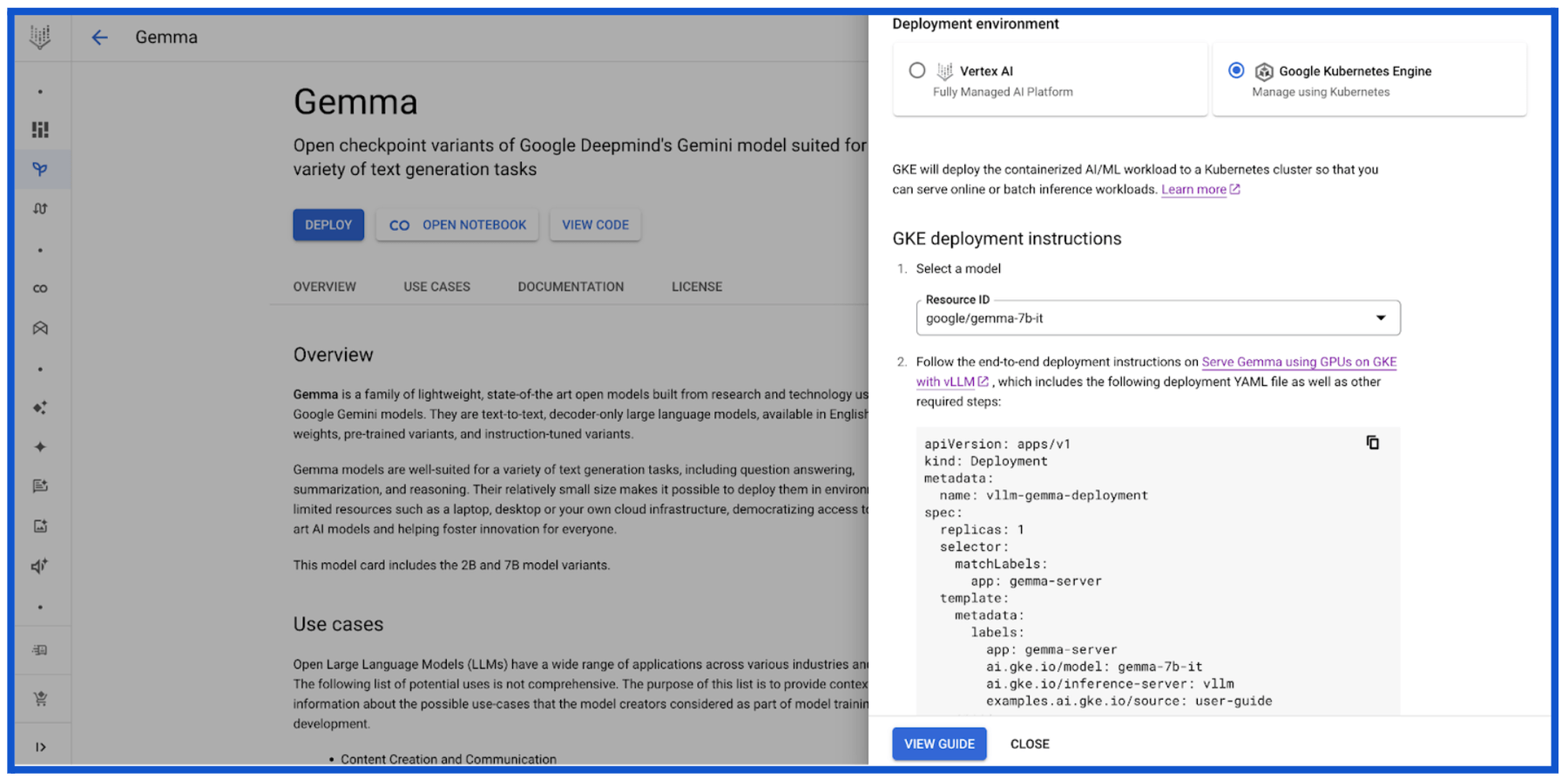
Source: Google
{kind=link}
3. Command R+
![]()
Cohere’s Command R+ is built for enterprise use cases and optimized for conversational interactions and long-context tasks. It is recommended for workflows that rely on sophisticated Retrieval Augmented Generation (RAG) functionality and multi-step tool use (agents).
Project information:
Command R+ is part of the proprietary Cohere platform. However, Cohere has released an open research version of the model on Hugging Face, which is available for non-commercial use. You can get the open version here.
Features:
- Model capabilities: Follows instructions and performs language tasks with high quality and reliability.
- Context window: Supports a context length of 128k tokens and can generate up to 4k output tokens, making it suitable for complex RAG workflows and multi-step tool use.
- Multilingual support: The model is optimized for English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic. It also includes pre-training data for 13 additional languages.
- Retrieval augmented generation: Can ground its English-language generations by generating responses based on supplied document snippets and including citations to indicate the source of the information.
- Multi-step tool use: Can connect to external tools like search engines, APIs, functions, and databases. The model can call more than one tool in a sequence of steps, reason dynamically, and adapt based on external information.
4. Mistral-8x22b
![]()
Mixtral-8x22B is a sparse Mixture-of-Experts (SMoE) model that leverages 39 billion active parameters out of a total 141 billion. It can handle NLP tasks in multiple languages and has strong capabilities in mathematics and coding.
Project information:
- License: Apache 2.0
- GitHub stars: 9.2K (Mistral AI)
- Main corporate sponsor: Mistral AI
- Official repo link: https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1
Features:
- Language proficiency: Fluent in English, French, Italian, German, and Spanish, enabling effective communication and understanding across these major languages.
- Context window: 64K tokens.
- Mathematics and coding: Supports complex problem-solving and software development tasks.
- Function calling: Natively capable of function calling, enhanced by a constrained output mode implemented on la Plateforme, enabling large-scale application development and tech stack modernization.
Source: Mistral
{kind=link}
5. Falcon 2
![]()
Falcon 2 is an AI model providing multilingual and multimodal capabilities, including unique vision-to-language functionality. Available in two versions, Falcon 2 11B and Falcon 2 11B VLM, it is independently verified by the Hugging Face Leaderboard.
Project information:
- License: Apache 2.0
- Main corporate sponsor: Technology Innovation Institute
- Official repo link: https://github.com/falconpl/Falcon2
Features:
- Model versions: Falcon 2 11B is a language model trained on 5.5 trillion tokens with 11 billion parameters. Falcon 2 11B VLM is a vision-to-language model, enabling the conversion of visual inputs into textual outputs.
- Context window: 8K tokens.
- Multilingual: Supports multiple languages, including English, French, Spanish, German, and Portuguese.
- Multimodal capabilities: The VLM version can interpret images and convert them to text, supporting applications across healthcare, finance, eCommerce, education, and legal sectors. It is suitable for document management, digital archiving, and context indexing.
- Efficiency: Operates on a single GPU, supporting scalability and deployment on lighter infrastructure like laptops and other devices.
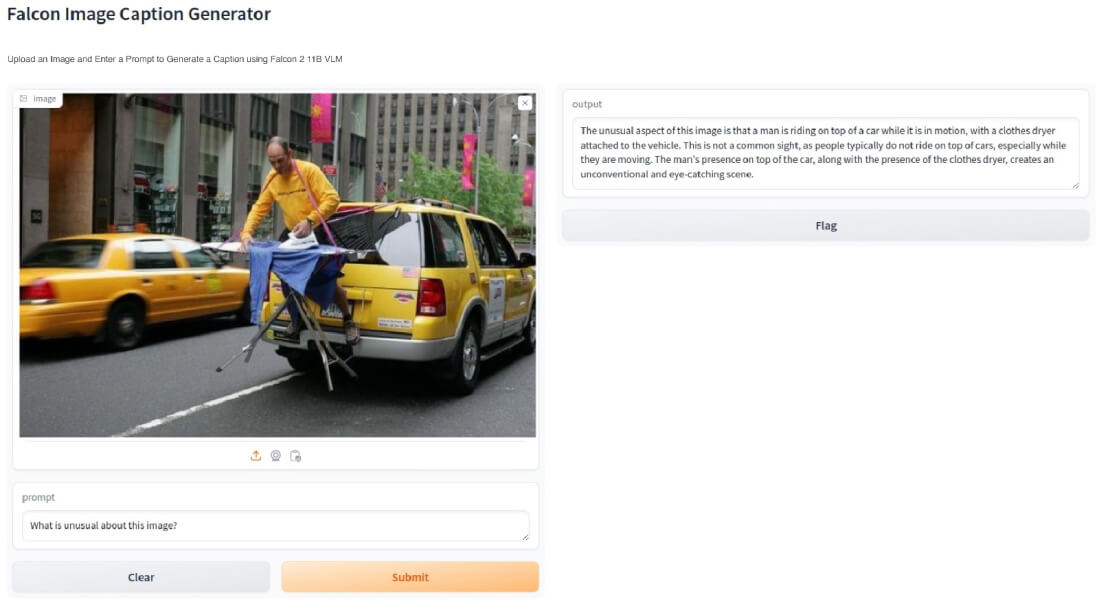
Source: Falcon
{kind=link}
6. Grok 1.5
![]()
Grok-1.5, developed by Elon Musk’s xAI, builds on the foundation of Grok-1. Grok-1.5V expands traditional text-based LLM capabilities to include visual understanding. This multimodal model can interpret various image types and perform complex reasoning tasks by combining linguistic skills with visual analysis.
Features:
- Context window: 128K tokens.
- Multimodal capabilities: Processes and understands a range of visual information, including documents, diagrams, and photographs. It can analyze documents, interpret user interface elements, understand photographs, and handle dynamic visual content such as videos and animations.
- Multi-disciplinary reasoning: Can combine visual and textual information to perform complex reasoning tasks. It can answer questions about scientific diagrams, follow instructions involving text and images, and provide diagnostic insights in medical imaging by analyzing scans and patient records.
- Real-world spatial understanding: Performs strongly on the RealWorldQA benchmark, which measures an AI model’s ability to understand and interact with real-world environments.
Source: X.ai
7. Qwen1.5
![]()
Qwen1.5, developed by Chinese cloud service provider Alibaba Cloud, is the latest update in the Qwen series, offering base and chat models in a range of sizes: 0.5B, 1.8B, 4B, 7B, 14B, 32B, 72B, and 110B. It also includes a Mixture of Experts (MoE) model. All versions are open-sourced and available in various quantized formats to improve usability.
Project information:
- License: Tongyi Qianwen research license
- GitHub stars: 6.3K
- Contributors: Qwen team
- Main corporate sponsor: Alibaba China
- Official repo link: https://github.com/QwenLM/Qwen2
Features:
- Model versions: Available in sizes from 0.5B to 110B parameters, including a Mixture of Experts (MoE) model. Quantized versions include Int4, Int8, GPTQ, AWQ, and GGUF models.
- Context window: Supports contexts up to 32K tokens, performing well on the L-Eval benchmark, which measures long-context generation capabilities.
- Integration: Qwen1.5’s code is integrated with Hugging Face Transformers (version 4.37.0 and above). The models are also supported by frameworks like vLLM, SGLang, AutoAWQ, AutoGPTQ, Axolotl, and LLaMA-Factory for fine-tuning, and llama.cpp for local inference.
- Platform support: Available on platforms such as Ollama, LMStudio, and API services via DashScope and together.ai.
- Multilingual capabilities: Evaluated across 12 languages, demonstrating strong performance in exams, understanding, translation, and math tasks.
8. BLOOM
![]()
BLOOM, developed through a large collaboration of AI researchers, aims to democratize access to LLMs, making it possible for academia, nonprofits, and smaller research labs to create, study, and use these models. It is the first model of its size for many languages, including Spanish, French, and Arabic.
Project information:
- License: BigScience RAIL license
- GitHub stars: 129K
- Contributors: Margaret Mitchell et. al.
- Main corporate sponsor: HuggingFace, BigScience
- Official repo link: Click here
Features:
- Multilingual capabilities: Supports 46 natural languages and 13 programming languages.
- Parameter size: Includes 176 billion parameters.
- Accessibility: Available under the Responsible AI License, allowing individuals and institutions to use and build upon the model. It can be easily integrated into applications via the Hugging Face ecosystem using transformers and accelerators.
- Inference API: An inference API is being finalized to enable large-scale use without dedicated hardware.
9. GPT-NeoX
![]()
GPT-NeoX is a 20 billion parameter autoregressive language model developed by EleutherAI. Trained on the Pile dataset, GPT-NeoX-20B is a dense autoregressive model with publicly available weights. This model, made freely accessible under a permissive license, offers advanced capabilities in language understanding, mathematics, and knowledge-based tasks.
Project information:
- License: Apache 2.0
- GitHub stars: 6.8K
- Main corporate sponsor: EleutherAI
- Official repo link: https://github.com/EleutherAI/gpt-neox
Features:
- Model size: GPT-NeoX-20B has 20 billion parameters, making it one of the largest open-source models available.
- Training setup: It uses Megatron and DeepSpeed libraries for training across multiple GPUs, optimized for distributed computing. It supports parallelism techniques like tensor and pipeline parallelism to enhance efficiency.
- Performance: The model performs particularly well on natural language understanding and few-shot tasks, surpassing similarly sized models like GPT-3 Curie in some benchmarks.
- Dataset: The model was trained exclusively on English data from the Pile, and is not intended for multilingual tasks.
- Usage: While versatile, GPT-NeoX-20B is not fine-tuned for consumer-facing tasks like chatbots and may require supervision when used in such settings.
10. Vicuna-13B
![]()
Vicuna-13B is an open source chatbot model developed by fine-tuning the LLaMA model with user-shared conversations from ShareGPT. It has achieved over 90% of the quality of OpenAI’s ChatGPT, based on preliminary evaluations using GPT-4 as a judge. The development cost of Vicuna-13B was approximately $300, and both the code and weights are publicly available for non-commercial use.
Project information:
- License: Non-commercial license
- GitHub stars: 35.8K
- Contributors: Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, Ion Stoica
- Main corporate sponsor: LMSYS
- Official repo link: https://github.com/lm-sys/FastChat
Features:
- Performance: Preliminary evaluations using GPT-4 indicate that Vicuna-13B achieves over 90% of the quality of ChatGPT and early versions of Google Gemini. It also outperforms other models like LLaMA and Stanford Alpaca.
- Training: The model was trained using PyTorch FSDP on 8 A100 GPUs in one day, with a focus on multi-turn conversations and long sequence handling. It was trained on approximately 70,000 user-shared conversations from ShareGPT.
- Serving: A lightweight distributed serving system was implemented to serve multiple models with flexible GPU worker integration, using SkyPilot managed spot instances to reduce serving costs.
NetApp Instaclustr: Empowering open source large language models
Open source large language models have revolutionized natural language processing (NLP) and artificial intelligence (AI) applications by enabling advanced text generation, sentiment analysis, language translation, and more. However, training and deploying these models can be resource-intensive and complex. NetApp Instaclustr steps in to support open source large language models, providing a robust infrastructure and managed services that simplify the process. In this article, we will explore how NetApp Instaclustr empowers organizations to leverage the full potential of open source large language models.
Training large language models requires substantial computational resources and storage capacity. NetApp Instaclustr offers a scalable and high-performance infrastructure that can handle the demanding requirements of model training. By leveraging the distributed computing capabilities and storage capacity provided by NetApp Instaclustr, organizations can efficiently train large language models, reducing the time and resources required for the training process.
Once trained, deploying large language models can present challenges due to their size and resource requirements. NetApp Instaclustr simplifies the deployment process by offering managed services that handle the infrastructure and operational aspects. It takes care of provisioning the necessary compute resources, managing storage, and ensuring high availability and fault tolerance. This allows organizations to focus on utilizing the models for their specific NLP and AI applications without the burden of managing the underlying infrastructure.
NetApp Instaclustr leverages its scalable infrastructure to support the deployment of open source large language models. As the demand for processing power and storage increases, organizations can easily scale their infrastructure up or down to accommodate the workload. This scalability ensures optimal performance, enabling efficient and fast processing of text data using large language models.
Open source large language models often deal with sensitive data, and ensuring data security is crucial. NetApp Instaclustr prioritizes data security by providing robust security measures, including encryption at rest and in transit, role-based access control, and integration with identity providers. These security features help organizations protect their data and comply with industry regulations and privacy standards.
NetApp Instaclustr offers comprehensive monitoring and support services for open source large language models. It provides real-time monitoring capabilities, allowing organizations to track the performance and health of their models. In case of any issues or concerns, NetApp Instaclustr’s support team is readily available to provide assistance and ensure minimal downtime, enabling organizations to maintain the reliability and availability of their language models.
Managing the infrastructure for open source large language models can be costly. NetApp Instaclustr helps organizations optimize costs by offering flexible pricing models. With pay-as-you-go options, organizations can scale their resources based on demand and pay only for what they use. This eliminates the need for upfront investments and provides cost predictability, making it more accessible for organizations of all sizes to leverage open source large language models.
For more information:
- Use Your Data in LLMs With the Vector Database You Already Have: The New Stack
- How To Improve Your LLM Accuracy and Performance With PGVector and PostgreSQL®: Introduction to Embeddings and the Role of PGVector
- Powering AI Workloads with Intelligent Data Infrastructure and Open Source
- Vector Search in Apache Cassandra® 5.0