What Is a NoSQL database?
NoSQL databases are a category of database management systems that handle various forms of data more flexibly than traditional SQL databases. Unlike SQL databases, which organize data in structured tables, NoSQL systems provide schema-less, distributed data storage solutions suitable for a range of applications.
These databases manage large datasets, allowing for swift scalability and performance without the constraints of predefined schemas. NoSQL databases emerged as a response to the increasing complexity and volume of digital data, which traditional databases could not efficiently support.
NoSQL databases follow various models—key-value, document, wide-column, and graph—to suit different use cases. The shift from rigid SQL structures to NoSQL’s flexibility is useful for addressing challenges such as managing dynamic web applications and leveraging real-time analytics.
SQL vs NoSQL: What is the difference?
SQL databases use a fixed schema, organizing data into well-defined tables, and are suitable for maintaining consistent and transactional data integrity. They rely on structured query language (SQL) for data manipulation, providing ACID compliance to ensure data reliability.
NoSQL databases prioritize flexibility and scalability over rigid data structures. They support various data models and can handle semi-structured or unstructured data, often sacrificing strict ACID compliance in favor of speed and distribution. This adaptability makes NoSQL better suited for applications requiring high-speed data access and horizontal scaling across distributed systems or cloud infrastructure.
Learn more in our detailed guide to NoSQL vs SQL
Relational databases vs NoSQL databases
Relational databases, characterized by their structured format and table-based organization, are suitable for workloads needing transactional integrity and a clear, consistent data schema. They are deeply rooted in SQL’s structured query language, making them reliable for applications like finance and inventory management, with precise data relationships.
NoSQL databases are more appropriate in environments demanding rapid scaling and agile data handling. They offer a more dynamic approach, accommodating complex or irregular datasets that do not fit neatly into tables. This makes them suitable for big data applications, real-time web applications, and scenarios with varying data structures.
Tips from the expert

Justin George
Solution Architect
Justin George is a seasoned tech leader who delivers high-impact technical strategies to help optimize data pipelines and data architectures.
In my experience, here are tips that can help you better utilize and optimize NoSQL databases:
- Design with eventual consistency in mind: NoSQL databases often prioritize availability and partition tolerance over consistency (CAP theorem). Ensure your application can tolerate eventual consistency by designing mechanisms to handle temporary inconsistencies or conflicts in distributed environments.
- Leverage polyglot persistence: Don’t be afraid to use multiple NoSQL databases in conjunction with traditional SQL databases. Combining key-value stores for caching with document stores for unstructured data and relational databases for transactions can optimize performance across different parts of your application.
- Optimize data models based on access patterns: Unlike SQL, where normalization is a standard practice, NoSQL favors denormalization to reduce query complexity. Design your data model based on how data will be accessed, allowing you to minimize costly joins and improve retrieval performance.
- Use sharding and replication smartly: While NoSQL databases offer automatic sharding and replication, excessive sharding or poorly planned replication can introduce overhead and latency. Plan shard keys carefully, ensuring they evenly distribute the load while minimizing cross-shard communication.
- Monitor and tune compaction processes: Many NoSQL databases, such as Cassandra, rely on background compaction processes to manage data storage. These operations can affect performance, so monitoring and tuning compaction strategies (frequency, threshold) is essential to avoid performance degradation.
How do NoSQL databases work?
NoSQL databases handle large volumes of unstructured data by distributing it across multiple servers. This distribution aids in scalability, allowing the system to grow by adding more nodes as data volumes increase. Unlike relational databases, which follow a fixed schema, NoSQL databases are typically schema-less, meaning they can store various types of data without any formatting constraints.
Data retrieval in NoSQL databases is optimized for speed, often utilizing key-based systems for quick access. Queries are executed without the overhead of complex joins, common in SQL systems, since NoSQL databases store data in a way that is inherently optimized for retrieval. This model improves performance and provides faster response times.
Learn more in our detailed guide to NoSQL architecture (coming soon)
Types of NoSQL databases
NoSQL databases can store data in several formats. Here are some of the main ones:
- Key-value databases: Each piece of data is stored as a pair consisting of a unique key and its corresponding value. This enables rapid access and retrieval in scenarios requiring high-speed transactions, such as caching, user session storage, and real-time recommendations. Due to their simplicity, key-value databases sacrifice complex querying for performance, providing only basic data interaction capabilities through key-based lookups.
- Document-oriented databases: Store data in a format akin to JSON or XML documents, enabling them to handle complex, nested data structures. Suitable for managing semi-structured data or objects with varying attributes, offering flexibility in how data can be stored and retrieved. They support complex queries on individual documents, allowing developers to quickly iterate and evolve their applications without worrying about schema changes, since each document can store different fields.
- Wide-column stores: Handle large datasets across distributed environments. By organizing data in columns rather than rows, they enable efficient data storage and retrieval, especially for analytical processing. One example is Apache Cassandra. These are suitable for high-performance queries, with optimized data storage supporting horizontal scalability, where additional nodes can join the cluster.
- Graph databases: Specialize in managing data connections rather than individual data points, making them suitable for applications where relationships are central, such as social networks, fraud detection, and recommendation systems. They represent data as nodes, edges, and properties, allowing complex relationship queries and analyses to be executed efficiently.
- Multi-model databases: Integrate multiple NoSQL database types into a single system to handle diverse data models and queries. This enables developers to use the same database to manage different types of data and workloads, from key-value pairs to graph structures, within unified management and operational contexts.
Learn more in our detailed guide to NoSQL DB examples (coming soon)
Key NoSQL use cases
Here are some of the main reasons to use a NoSQL database:
- Real-time data management: NoSQL databases can handle rapid, continuous data updates and queries without performance degradation. Their distributed nature allows them to ingest and process high-velocity streams of data, useful for applications in fields like telecommunications, finance, and online gaming.
- Managing data relationships: Graph databases can handle and analyze complex data relationships, offering node-edge property representation. This is useful in scenarios where connections between data points are equally or more important than the data itself. This is seen in social media platforms, recommendation engines, and fraud detection systems.
- Scaling and large data volumes: Unlike traditional databases, which may struggle with vertical scaling and performance bottlenecks, NoSQL databases support horizontal scaling, allowing them to handle increasing data volumes by distributing storage and processing across numerous servers. They can partition and replicate data across clusters, ensuring load balancing and eliminating single points of failure. This is useful for applications like eCommerce platforms and IoT systems.
- High-availability applications: Online retail, banking systems, and streaming services rely on databases that offer maximum uptime and data redundancy to ensure uninterrupted service. NoSQL databases provide this through strategies like data replication and automated failover mechanisms, helping minimize downtime and prevent data loss during system failures. Their decentralized, distributed architecture ensures reliability by providing multiple data copies across different locations.
Learn more in our detailed guide to NoSQL use cases (coming soon)
Advantages of NoSQL databases
These databases offer the following useful characteristics:
- Flexibility: Can adapt to various business requirements and data formats, including semi-structured and unstructured data, without extensive reconfiguration. While traditional SQL systems require fixed schemas, NoSQL supports dynamic data handling, making it easier to incorporate new fields or data types as applications evolve.
- Replication: Ensure data availability and reliability by duplicating data across multiple nodes or servers. This redundancy mitigates the risk of data loss due to hardware failures, providing a layer of data protection for maintaining high availability. In distributed systems, replication supports load balancing and disaster recovery, ensuring continuous operation when individual components fail.
- Performance: Provide low-latency data retrieval and high throughput, which are essential in applications requiring real-time data processing. This performance efficiency supports use cases like social media analytics and online transaction processing. Their schema-less nature reduces the overhead associated with complex joins and transactions typical of traditional SQL systems.
- Cost-effectiveness: Support horizontal scaling, allowing organizations to use lower-cost hardware for scaling out rather than investing in expensive, high-end servers required for vertical scaling in SQL databases. This reduces capital expenditure and offers a more predictable cost structure as data needs grow.
When not to choose a NoSQL database
NoSQL databases are not suitable for all applications. They typically do not provide the strict ACID compliance found in SQL systems, which can be a disadvantage for applications where transactional integrity is critical. Use cases relying on complex queries and consistent data schemas might suffer performance issues or data anomalies when adapting to NoSQL systems.
For applications with structured data requiring high relational integrity, traditional SQL databases often provide more reliable solutions. Scenarios like financial transactions and inventory management, where data accuracy and consistency are the priority , benefit from the strong ACID transactions and established industry practices that SQL databases offer.
Another factor to consider is the existing expertise and infrastructure within an organization. Transitioning to NoSQL may involve significant retraining and resource allocation. If an organization is heavily dependent on SQL systems and lacks the infrastructure for distributed database management, maintaining current relational database systems might be more practical.
Notable NoSQL databases
1. Apache Cassandra
![]()
Apache Cassandra is a distributed NoSQL database for handling large amounts of data across many commodity servers. Its architecture offers high availability and no single point of failure, and can handle massive volumes of real-time data. Its peer-to-peer design enables data to be distributed across nodes, supporting horizontal scaling for demanding big data applications.
Cassandra’s model is optimized for write-heavy workloads and provides eventual consistency, making it suitable for tasks requiring distributed data storage without sacrificing speed. Its ability to manage multiple data centers improves data redundancy and ensures uninterrupted access. These features make it particularly useful for applications like user activity tracking, online retail, and IoT data management.
License: Apache-2.0
Repo: https://github.com/apache/cassandra
GitHub stars: 8k+
Contributors: 400+
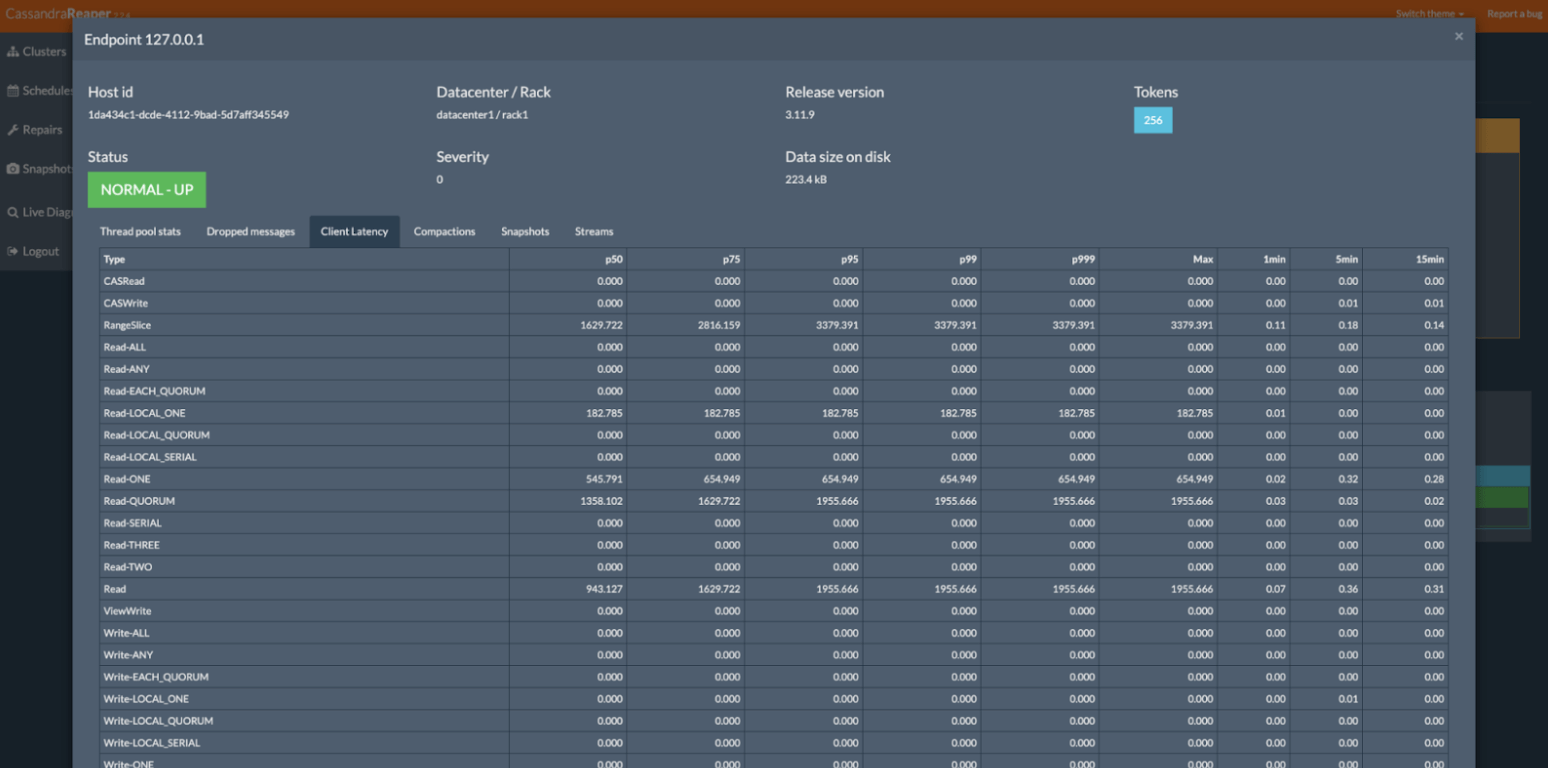
Source: Apache
{kind=link}
2. Redis

Redis is an in-memory data store offering a set of data structures, including strings, lists, sets, and sorted sets, making it suitable for applications requiring fast data operations like caching, real-time analytics, and messaging queues. Redis’ simplicity enables fast data access.
The persistence capabilities of Redis complement its in-memory performance, ensuring data durability across power cycles. Redis supports replication with failover, improving its reliability for high-availability applications. Cluster mode allows horizontal scaling across multiple nodes, accommodating dataset growth while maintaining consistent performance.
License: Redis Source Available License v2, Server Side Public License v1
Repo: https://github.com/redis/redis
GitHub stars: 66k+
Contributors: 700+
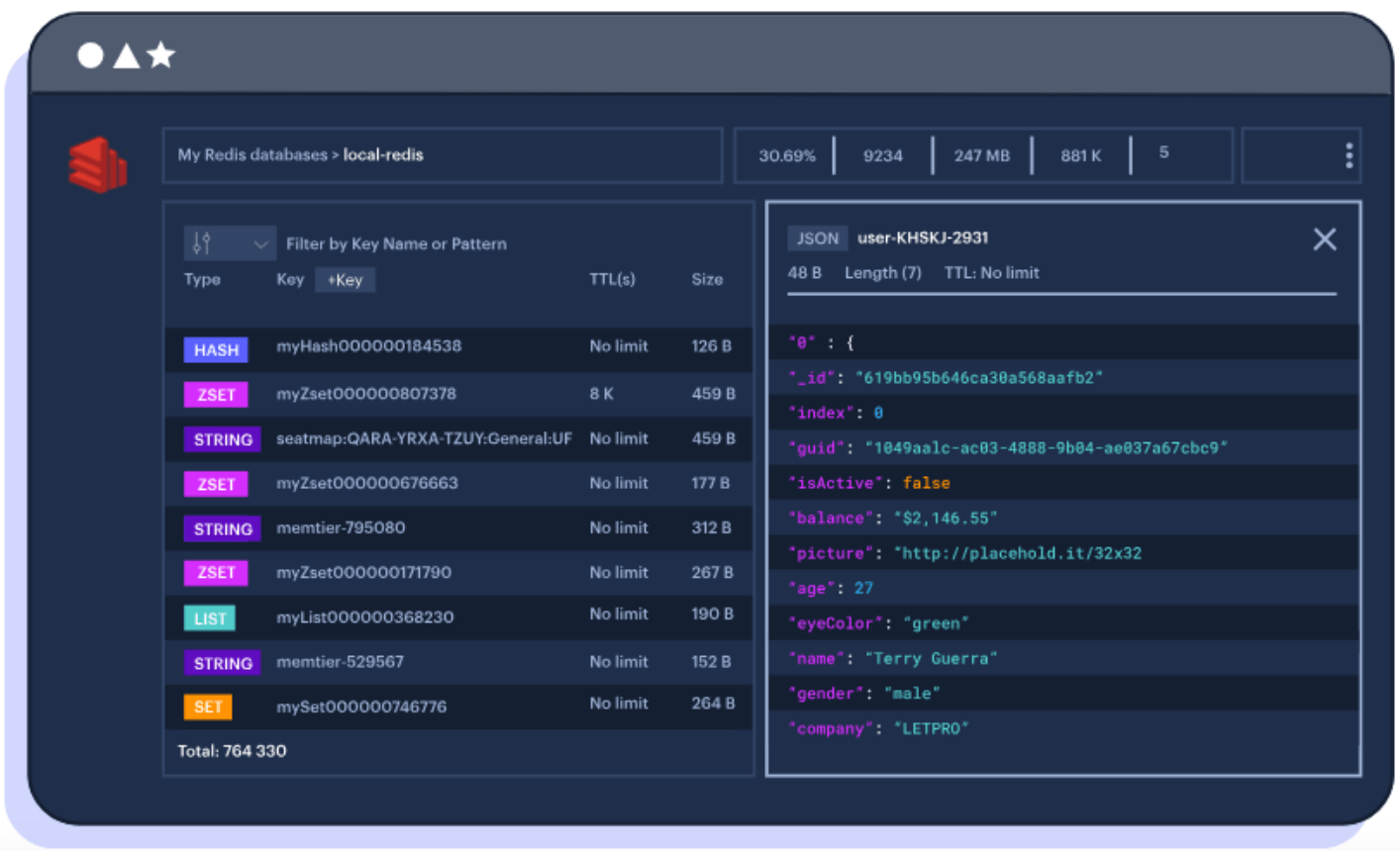
Source: Redis
{kind=link}
Learn more in our detailed guide to NoSQL Redis (coming soon)
3. OpenSearch
![]()
OpenSearch is an open-source, distributed search and analytics engine for large-scale data indexing, logging, and real-time analytics. Originally forked from Elasticsearch, OpenSearch provides a search engine with capabilities like full-text search, structured data querying, and extensive log analysis.
OpenSearch supports a plugin-based architecture, allowing users to extend its functionality. Its distributed nature enables horizontal scaling. Common in observability and data analysis workflows, OpenSearch is particularly useful for organizations that require both high-speed search and analytical capabilities.
License: Apache 2.0
Repo: https://github.com/opensearch-project/OpenSearch
GitHub stars: 9k+
Contributors: 300+

Source: OpenSearch
{kind=link}
4. MongoDB
![]()
MongoDB is a NoSQL database offering document-oriented storage. It uses a schema-less data model, enabling developers to store data in dynamic, JSON-like BSON formats, which adapt easily to changing application needs. MongoDB supports complex queries and indexing, enabling data retrieval across complex datasets.
With features like auto-sharding and replication, it ensures high availability and scalability. Its ecosystem includes integration tools and compatibility with multiple programming languages, fostering easy deployment and management in various development and production settings.
License: Server Side Public License
Repo: https://github.com/mongodb/mongo
GitHub stars: 26k+
Contributors: 30+
Source: MongoDB
{kind=link}
5. Couchbase
![]()
Couchbase is a NoSQL database that merges key-value and document-oriented models. It offers strong replication and sync capabilities, making it suitable for mobile and cloud applications that require instant data availability and consistency even when offline.
Couchbase’s architectural emphasis on distributed cloud-native deployments ensures scalability and reliability. Its query engine supports SQL-like querying, simplifying development and administration. The database also provides in-memory data caching, reducing latency and improving performance for read-heavy applications.
License: Apache-2.0
Repo: https://github.com/couchbase/couchbase-lite-ios
GitHub stars: 1k+
Contributors: <50
Source: Couchbase
{kind=link}
6. Neo4j
![]()
Neo4j is a graph database to optimize data modeling and querying based on relationships. It uses a graph structure, consisting of nodes, edges, and properties, enabling efficient data traversal and deep analysis of interconnected data. This setup is particularly suitable for applications like fraud detection, social networks, and recommendation engines.
The native graph processing capabilities of Neo4j allow complex, multi-level relationship queries to be executed with minimal overhead compared to traditional databases. Its Cypher query language enables intuitive graph manipulation and data insight extraction. It supports large datasets and high availability through replication and clustering.
License: Server Side Public License
Repo: https://github.com/neo4j/neo4j
GitHub stars: 13k+
Contributors: 30+
Source: Neo4j
{kind=link}
7. Amazon DynamoDB
![]()
Amazon DynamoDB is a fully-managed, serverless NoSQL database service provided by AWS. It can handle large volumes of data with millions of requests per second, providing consistent low-latency responses. This service is suitable for applications that require high throughput and need to scale in response to variable data demands, such as mobile backends, gaming applications, and IoT.
DynamoDB’s automatic scaling dynamically adjusts capacity to match workload requirements, ensuring optimal cost management. It supports event-driven computing via AWS Lambda and advanced security through AWS IAM.
License: Commercial

Source: Amazon
{kind=link}
8. ArangoDB
![]()
ArangoDB offers a multi-model approach, supporting graph, document, and key-value data in one database. It lets developers manage diverse data workloads without switching between multiple systems.
The database’s native support for schema-free JSON supports rapid development cycles and data integration with existing systems. ArangoDB’s built-in query language, AQL, enables data manipulation and retrieval, while its distributed architecture enables performance scalability and data consistency.
License: Apache 2.0, BSL 1.1
Repo: https://github.com/arangodb/arangodb
GitHub stars: 13k+
Contributors: 100+
Source: ArangoDB
{kind=link}
Streamlining NoSQL database management with Instaclustr: Benefits and advantages
Instaclustr is a managed service provider that offers a range of benefits for NoSQL databases, such as Apache Cassandra and OpenSearch, which have become increasingly popular due to their ability to handle large volumes of unstructured and semi-structured data. However, managing and scaling these databases can be complex and time-consuming. This is where Instaclustr comes in, providing a comprehensive platform that simplifies the deployment, management, and scaling of NoSQL databases.
One of the key benefits of Instaclustr is its managed service approach. Instaclustr takes care of the infrastructure and operational tasks associated with running NoSQL databases, allowing developers and businesses to focus on their core applications and data. This includes tasks such as provisioning, configuration, monitoring, backups, and security. By offloading these responsibilities to Instaclustr, organizations can save valuable time and resources that can be better utilized for developing their applications and delivering value to their customers.
Scalability is another area where Instaclustr shines. NoSQL databases are designed to scale horizontally, meaning they can handle increasing workloads by adding more servers to the cluster. Instaclustr provides automated scaling capabilities, allowing databases to seamlessly grow or shrink based on demand. This ensures that applications running on NoSQL databases can handle spikes in traffic and accommodate future growth without the need for manual intervention. Instaclustr’s scaling features also help optimize costs by dynamically adjusting the resources allocated to the database, ensuring efficient resource utilization.
Instaclustr also offers high availability and fault tolerance for NoSQL databases. It employs replication and data distribution techniques to ensure that data is stored redundantly across multiple nodes in the cluster. This provides resilience against hardware failures and enables continuous availability of data, even in the event of node failures. Instaclustr’s platform actively monitors the health of the database cluster and automatically handles failover and recovery processes, minimizing downtime and maximizing data availability.
In addition to these core benefits, Instaclustr provides comprehensive support and expertise for NoSQL databases. Their team of experts has deep knowledge and experience in managing and optimizing NoSQL deployments, and they offer 24/7 support to assist customers with any issues or challenges they may encounter. Instaclustr also keeps up with the latest advancements in NoSQL technologies and ensures that their platform is updated and compatible with the latest versions, providing customers with access to the latest features and improvements.
For more information see: