What is the Apache Kafka API?
Apache Kafka is an open source distributed streaming platform, known for handling real-time data feeds. Its APIs enable the creation, transmission, and management of data streams, supporting various operations programmatically. It allows for data integration and movement across systems by offering APIs for producers, consumers, stream processing, and management.
Kafka APIs are suited for applications requiring reliable, scalable data streaming. They support multiple data streaming use cases, like event sourcing and log aggregation. Kafka provides a mechanism to ensure high throughput and low latency, making it suitable for applications with demanding data requirements.
Overview of Kafka APIs
Here’s a look at the different types of APIs provided by Kafka.
Producer API
The producer API in Kafka allows applications to publish records to a Kafka topic. It is suitable for real-time data streaming scenarios. Producers handle automatic load balancing, ensuring even message distribution across partitions. Configurable settings help manage acknowledgments, retries, and batching according to application needs. Proper use of the producer API guarantees efficient data ingress into Kafka.
The API integrates with custom serialization setups, enabling data format flexibility. By providing customizable partitioning strategies, it helps achieve the required data distribution logic. Kafka ensures message delivery reliability through configurable delivery semantics, including at-least-once and exactly-once guarantees. The producer API’s performance settings, such as batch size and compression, further optimize data publishing operations.
Consumer API
The consumer API in Kafka is for fetching and processing records from Kafka topics. It supports building efficient data processing systems through features such as consumer groups, which allow for distributed processing. Consumers use topic-partition subscriptions for fine-grained control over data consumption, ensuring each message is processed, potentially in parallel across different consumer instances.
The API provides offset management, allowing consumers to track processed record positions. This ensures data is not reprocessed accidentally, avoiding duplicates. Kafka’s ability to integrate with various data processing frameworks via consumer API extends its utility for real-time data processing applications, including analytics and monitoring systems.
Streams API
The streams API is for building continuous data processing applications directly within Kafka. It offers a high-level abstraction for developing scalable, stream-processing applications involving data transformation and aggregation. Streams API uses a set of operators for processing event streams, simplifying operations on the incoming data.
This API provides stateful processing capabilities, leveraging the Kafka ecosystem for data storage and fault tolerance. Developers benefit from an integrated, end-to-end stream processing approach, reducing the need for external processing mechanisms. The streams API is suitable for real-time alerting, intelligent event routing, and on-the-fly data analytics.
Connect API
The connect API enables data integration by allowing scalable data movement between Kafka and other data systems. This API simplifies the task of managing and deploying connectors, eliminating the need for custom code in many scenarios. Pre-built connectors help simplify data import/export operations with various database systems and cloud providers.
Kafka Connect ensures data replication and transformation by providing configurable converters and transformations within the pipeline. This feature supports various data formats, improving interoperability. Kafka Connect’s distributed architecture makes it suitable for enterprise-level data environments that require reliable data synchronization across platforms.
Admin client API
The admin client API is for managing and inspecting Kafka topics, configurations, and other administrative operations. This API simplifies tasks like topic creation, deletion, and configuration alteration dynamically without a need for system restarts. Admin client APIs support easier maintenance and management of Kafka clusters.
Through its APIs, administrators can manage user quotas, view consumer group details, and perform health checks on cluster components. This centralized management simplifies administrative workflows, improving Kafka’s usability in complex environments. Admin client provides an interface for interacting with Kafka’s underlying infrastructure.
Related content: Read our guide to Kafka architecture
Tutorial: Using Kafka APIs
This tutorial shows the steps involved when working with different Kafka APIs. These instructions are adapted from the Confluent documentation.
Producer API: Creating a Kafka producer
The producer API is used to write data streams to Kafka topics. Below is an example implementation demonstrating the steps to configure and use a Kafka producer:
- Add dependencies: Add the following Maven dependency to include the Kafka producer library in the project:
12345<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
- Configure producer properties: Define the producer’s configuration properties to specify the Kafka cluster, serializers, and other settings:
1234Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, ":9092");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
- Send messages to Kafka: Use the
KafkaProducerclass to create a producer and publish a message to a Kafka topic asynchronously:12345678910try (Producer<String, String> producer = new KafkaProducer<>(props)) {producer.send(new ProducerRecord<>("example-topic", "example-message"), (metadata, exception) -> {if (exception != null) {System.err.println("Error producing message: " + exception.getMessage());} else {System.out.printf("Message sent to topic %s, partition %d, offset %d%n",metadata.topic(), metadata.partition(), metadata.offset());}});}
This code sends a message "example-message" to the topic "example-topic" and logs the metadata upon successful delivery.
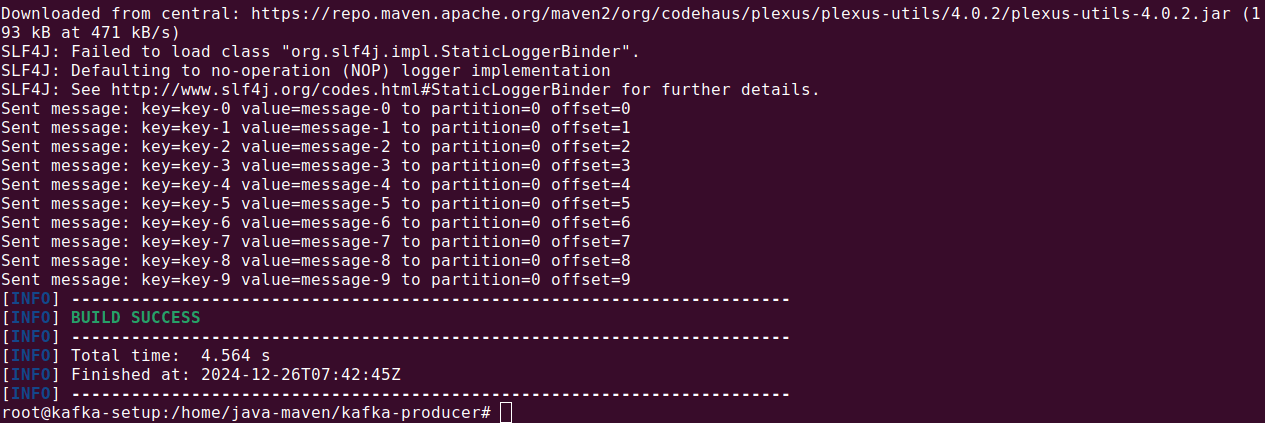
For example, if you have a Java-based component set up with Maven, you can create a Kafka producer with this command:
|
1 |
mvn exec:java -Dexec.mainClass="com.example.App" |
You can run a Kafka consumer using the following command:
|
1 |
./kafka-console-consume –bootstrap-server localhost:90292 –topic test-topic |

Consumer API: Reading data from Kafka
The consumer API fetches records from Kafka topics. Below is a step-by-step implementation of a simple consumer:
- Add dependencies: Include the Kafka consumer library:
12345<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
- Configure consumer properties: Define the consumer’s settings, including Kafka cluster, group ID, and deserializers:
12345Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "<HOST>:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "example-group-id");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- Consume messages from a topic: Use the
KafkaConsumerclass to subscribe to a topic and process incoming messages:1234567891011try (Consumer<String, String> consumer = new KafkaConsumer<>(props)) {consumer.subscribe(Collections.singletonList("example-topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {System.out.printf("Consumed message: key=%s, value=%s, topic=%s, partition=%d, offset=%d%n",record.key(), record.value(), record.topic(), record.partition(), record.offset());}}}
You can start a kafka producer using the following command:
|
1 |
kafka-console-producer –topic test-topic –bootstrape-server localhost:9092 |

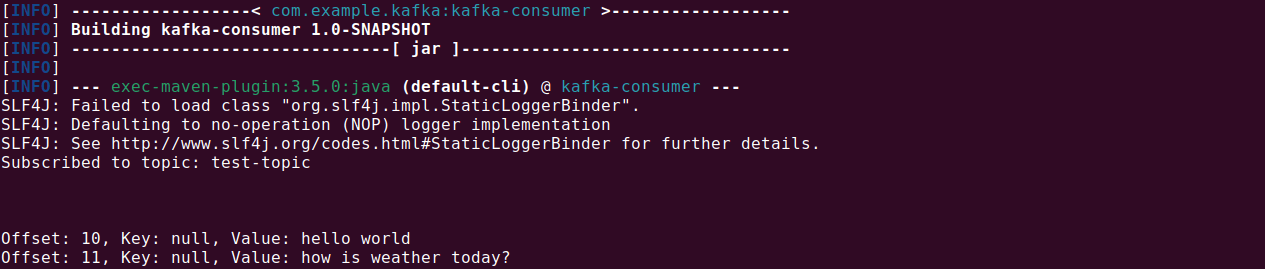
A Java-based consumer can be started using the following command (assuming you set up the component with Maven):
|
1 |
mvn exec:java -Dexec.mainClass="com.example.App" |
This code continuously polls the topic "example-topic" and processes the received records.
Admin Client API: Managing Kafka Resources
The admin client API allows programmatic management of Kafka clusters. Here’s how to create a topic using this API:
- Add dependencies: Include the Kafka admin library:
12345<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
- Create a Kafka topic: Use the
AdminClientclass to programmatically create a topic with a specified number of partitions and replication factor:12345678910111213Properties config = new Properties();config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "<HOST>:9092");try (AdminClient adminClient = AdminClient.create(config)) {NewTopic newTopic = new NewTopic("example-topic", 3, (short) 1); // 3 partitions, replication factor 1adminClient.createTopics(Collections.singletonList(newTopic));System.out.println("Topic 'example-topic' created successfully.");} catch (Exception e) {System.err.println("Error creating topic: " + e.getMessage());}
This script creates a topic named "example-topic" with 3 partitions and a replication factor of 1. Again, assuming you set up an application with Maven, you can use the following command:
|
1 |
mvn exec:java -Dexec.mainClass="com.example.App" |

You can list the kafka topics using the following command on Docker:
|
1 |
docker exec -it kafka kafka-topics –list –bootstrape-server localhost:9092 |

Connect API: Integrating external systems with Kafka
The connect API is for easy integration of external systems with Kafka. Here’s an example of how to set up and use Kafka Connect.
- Add dependencies: Add the required Maven dependency for Kafka Connect:
12345<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
- Using pre-built connectors: Kafka Connect simplifies data integration by offering pre-built connectors. For example, a JDBC connector for databases like PostgreSQL can capture every change to a table and send it to a Kafka topic. A file connector can read data from a file and write it to a topic or vice versa.
Example configuration for file source connector
The configuration below reads lines from a file and sends them as messages to a Kafka topic:
|
1 2 3 4 5 |
name=local-file-source connector.class=FileStreamSource tasks.max=1 file=/path/to/input/file.txt topic=connect-topic |
file: Path to the file to read.topic: The Kafka topic where messages are written.
Running the connector: Save the configuration in a file (e.g., file-source.properties) and run it using the Kafka Connect standalone mode:
|
1 |
connect-standalone.sh connect-standalone.properties file-source.properties |

This will start a connector that continuously monitors the specified file and streams its content to the topic connect-topic.
Kafka Streams API: Building Stream Processing Applications
The Kafka streams API is used to process real-time data streams within Kafka. Here’s an example of creating a stream processing application:
- Add dependencies: Add the Kafka Streams dependencies to the project:
12345<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>3.4.0</version></dependency>
- Configure the streams application: Define the configuration for the streams application:
12345Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-example");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "<HOST>:9092");props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
- Define the stream topology: Use the Kafka Streams DSL to define a simple word count application:
1234567StreamsBuilder builder = new StreamsBuilder();KStream<String, String> sourceStream = builder.stream("input-topic");KTable<String, Long> wordCounts = sourceStream.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count(Materialized.as("word-counts"));wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
- The input stream reads from
input-topic. - Words are extracted, grouped, and counted.
- Results are written to
output-topic.
For Docker based Kafka setup you can execute producer using the following command:
|
1 |
kafka-console-producer --topic input-topic --bootstrap-server localhost:9092 |

If you created a Java application using Maven, you can start it using the following command:
|
1 |
mvn exec:java -Dexec.mainClass="com.example.App" |

Tips from the expert

Jacob Huang
Graduate Software Engineer
Justin Huang works in the Instaclustr R&D department and is actively involved in software development and research initiatives for open source technologies.
In my experience, here are tips that can help you better leverage Apache Kafka APIs:
- Prioritize schema management with Schema Registry: Use Schema Registry like Karapace or Confluent’s Schema Registry to manage message schemas. This ensures data consistency across producers and consumers and reduces the risk of deserialization errors, especially in large-scale systems with multiple clients.
- Enable idempotent producers for exactly-once semantics: Configure the producer with
enable.idempotence=trueto guarantee exactly-once delivery. Combine this with transactional APIs for end-to-end exactly-once guarantees in stream processing applications. - Implement custom partitioning for optimal load distribution: Use a custom partitioner to control how messages are distributed across partitions. This can help balance load effectively or ensure message affinity for scenarios like session-based processing.
- Design for scalability with consumer group strategies: When scaling consumers, distribute processing by assigning each consumer in a group to unique topic partitions. Use sticky partition assignment strategies for better partition ownership stability during rebalances.
- Leverage Kafka Streams state stores for enriched analytics: Use Kafka Streams’ state stores for persistent, fault-tolerant storage during stream processing. Integrate with RocksDB for efficient state management, enabling complex analytics like windowed aggregations or join operations.
4 Best practices for using Kafka APIs
When working with Apache Kafka APIs, using the following practices will help ensure the most effective application performance.
1. Fault tolerance and error handling
To ensure fault tolerance, configure retries for producer operations using the retries property. Set an appropriate retry backoff with retry.backoff.ms to avoid overwhelming the broker in case of temporary failures.
For consumers, handle exceptions during message processing to prevent the application from failing entirely. Use Kafka’s commit APIs to commit offsets only after successful processing. This ensures unprocessed messages can be re-consumed if a failure occurs.
Enable replication for Kafka topics to tolerate broker failures. Configure the min.insync.replicas setting to ensure a minimum number of replicas acknowledge a write before it is considered successful. This balances reliability with performance.
2. Security and authentication
Secure communication between clients and brokers using SSL encryption by enabling SSL endpoints. Use mutual TLS for additional authentication layers, ensuring only trusted clients can connect to the brokers.
For authentication, leverage SASL mechanisms like SCRAM or OAuthBearer. Configure sasl.mechanism and security.protocol properties in the client applications to use the desired authentication method.
Implement access control using Kafka’s ACL (access control list) feature. Define granular permissions for users and groups on topics, consumer groups, and cluster resources to prevent unauthorized access.
3. Performance tuning
Optimize producer throughput by using larger batch sizes (batch.size) and enabling compression (compression.type) for efficient network utilization. Experiment with different compression algorithms (e.g., gzip, lz4, or snappy) to balance compression time with bandwidth savings.
For consumers, adjust the fetch size (fetch.min.bytes and fetch.max.bytes) and poll interval (max.poll.interval.ms) to optimize data retrieval and processing rates. Set the session.timeout.ms and heartbeat.interval.ms values carefully to maintain consumer group stability without unnecessary rebalancing.
Fine-tune broker settings like log.segment.bytes and log.retention.ms to balance storage costs with performance. Monitor disk I/O and ensure adequate capacity to prevent performance bottlenecks.
4. Monitoring and metrics
Use Kafka’s built-in JMX metrics to monitor broker and client performance. Key metrics include message production and consumption rates, partition lag, and replica synchronization status.
Integrate monitoring tools like Prometheus, Grafana, or OpenSearch for visualization and alerting. Monitor critical metrics such as CPU usage, memory utilization, and network throughput to identify potential issues early.
Set up alerts for anomalies like high latency, excessive ISR shrinkage, or frequent leader elections, which may indicate underlying issues. Regularly review logs and implement log rotation to ensure efficient storage management.
Simplify API integrations with Instaclustr for Apache Kafka: A fully managed solution
Apache Kafka is a leader in distributed event streaming, enabling organizations to build real-time data pipelines and applications. But deploying and managing Kafka can be complex, especially when it comes to ensuring seamless integration with your existing APIs. That’s where Instaclustr for Kafka steps in, delivering a fully managed, production-ready Kafka environment that makes API integrations effortless.
By leveraging Instaclustr, businesses gain access to a robust Kafka infrastructure that provides the flexibility to connect to virtually any API. Whether you’re integrating with application logs, IoT devices, analytics platforms, or customer engagement tools, Instaclustr ensures your Kafka pipelines are backed by industry-best practices for reliability, scalability, and performance. This means you can focus on building great applications, confident that your behind-the-scenes data movement is efficient and secure.
What sets Instaclustr apart is its commitment to simplifying even the most complex setups. With expert support and automated management features, integrating Kafka with your APIs becomes a seamless process, freeing up your team from the stress of manual configurations. Instaclustr’s platform also supports integrations with leading API management tools, allowing you to unlock the full potential of event-driven architecture while maintaining full visibility into data flows.
Whether you’re a growing startup or an established enterprise, Instaclustr for Kafka empowers you to leverage real-time data streams without the operational headaches. From its reliable API integrations to its top-tier technical support, Instaclustr gives you all the tools you need to make the most of Kafka in your business environment. Explore new possibilities today and transform the way your data flows with confidence.
For more information: