What is Apache Cassandra?
Apache Cassandra is a distributed NoSQL database for handling large amounts of data across commodity servers without a single point of failure. It offers high availability and is optimized for write-heavy workloads. Developed initially by Facebook and open-sourced in 2008, it has since grown into an ecosystem used by companies like Netflix, Apple, and Twitter. Its scalability allows it to handle petabytes of data effortlessly, making it a preferred choice for modern applications that require fast data access and reliability.
Cassandra uses a masterless architecture where all nodes are equal and participate in a peer-to-peer protocol. This setup ensures that no single server acts as a bottleneck. It supports dynamic scaling; new nodes can be added or removed with minimal service disruption. Its data model combines key-value pairs with tables, enabling flexible schema designs. The main features include tunable consistency levels, efficient writes, and decentralized control, making it a suitable database solution for large-scale, distributed systems.
This is part of a series of articles about Apache Cassandra-IR
How Apache Cassandra works?
Architecture
Cassandra architecture is based on a decentralized, masterless design, where all nodes play equal roles in the cluster. This peer-to-peer structure enables horizontal scalability and eliminates single points of failure. Data in Cassandra is partitioned and distributed across multiple nodes using a consistent hashing mechanism.
Each node is responsible for a portion of the data, and new nodes can be added without significant disruption. Data replication ensures fault tolerance, with configurable replication factors allowing multiple copies of the same data to exist on different nodes. This architecture supports linear scalability and ensures high availability even in the event of node failures.
Data model
Cassandra’s data model is centered around tables that store rows and columns, similar to traditional relational databases, but with significant differences. In Cassandra, data modeling is query-driven, which means that the schema is designed to optimize specific queries.
Unlike relational databases that use joins across tables, Cassandra denormalizes data by duplicating it across multiple tables, enabling high-performance reads. This approach relies on a primary key structure where the partition key distributes data across nodes and clustering keys determine the sort order within a partition. Denormalization ensures efficient data retrieval by minimizing the need to reference multiple tables.
Consistency and availability
Cassandra also offers tunable consistency, allowing users to choose between eventual and strong consistency based on their requirements. For example, clients can adjust how many nodes need to acknowledge a read or write operation before it is considered successful, offering a balance between performance and data accuracy.
To maintain read efficiency and manage disk space, Cassandra performs compaction, merging SSTables and discarding deleted data. Nodes communicate using a gossip protocol, sharing state information to detect and handle node failures dynamically. This decentralized communication lets the system adapt to changes.
Usage
cqlsh is the command-line shell for interacting with Apache Cassandra using the Cassandra Query Language (CQL). It allows users to execute queries, manage the database schema, and perform administrative tasks like inspecting table structures or modifying keyspaces. cqlsh is essential for operations like querying data, creating or altering tables, and managing clusters in a flexible and interactive environment.
Cassandra is optimized for high write throughput through its unique write path. When a write request is received, it is first recorded in the commit log to ensure durability. The data is then written to an in-memory structure called a memtable. Once the memtable reaches a threshold, it is flushed to disk into immutable files called SSTables (sorted string tables).
Related content: Learn more in our detailed guide to Apache Cassandra on AWS
Apache Cassandra commands cheat sheet
cqlsh shell commands
| Command | Description |
HELP |
Displays help topics for cqlsh commands. |
CAPTURE |
Captures output and writes it to a file. |
CONSISTENCY |
Displays or sets the consistency level. |
COPY |
Copies data to or from Cassandra. |
DESCRIBE |
Provides information about the cluster and objects. |
EXPAND |
Expands query results vertically. |
EXIT |
Exits the cqlsh shell. |
PAGING |
Enables or disables paging of query results. |
SHOW |
Displays details of the current cqlsh session. |
SOURCE |
Executes a file containing CQL statements. |
TRACING |
Enables or disables request tracing. |
Data definition commands (DDL)
| Command | Description |
CREATE KEYSPACE |
Creates a new keyspace. |
USE |
Switches to the specified keyspace. |
ALTER KEYSPACE |
Modifies the properties of a keyspace. |
DROP KEYSPACE |
Deletes a keyspace. |
CREATE TABLE |
Creates a new table in the keyspace. |
ALTER TABLE |
Modifies a table’s schema. |
DROP TABLE |
Deletes a table. |
TRUNCATE |
Removes all data from a table. |
CREATE INDEX |
Creates an index on a column. |
DROP INDEX |
Deletes an index. |
Data Manipulation Commands (DML)
| Command | Description |
INSERT |
Adds a new row or updates a row in a table. |
UPDATE |
Updates specific columns in a row. |
DELETE |
Removes data from a table. |
BATCH |
Executes multiple DML statements in a single operation. |
CQL clauses
| Clause | Description |
SELECT |
Retrieves data from a table. |
WHERE |
Filters the results of a SELECT query. |
ORDER BY |
Sorts query results in a specified order. |
Tips from the expert

Ritam Das
Solution Architect
Ritam Das is a trusted advisor with a proven track record in translating complex business problems into practical technology solutions, specializing in cloud computing and big data analytics.
In my experience, here are tips that can help you better adapt to using Apache Cassandra:
- Optimize partition key design: Design your partition keys to avoid hotspots. Ensure even data distribution by considering access patterns and query frequency. A well-thought-out partition key can significantly reduce read and write latencies.
- Use materialized views cautiously: Materialized views can simplify query logic but may introduce performance overhead. Always monitor the performance impact and consider alternatives like secondary indexes or denormalization for complex queries.
- Monitor compaction strategies: Choose the right compaction strategy based on your workload (e.g., Leveled Compaction for read-heavy and SizeTiered Compaction for write-heavy scenarios). Regularly monitor compaction metrics to prevent disk space issues and optimize performance. The right strategy is key in disk space reclamation.
- Pre-split keyspaces for large datasets: Pre-splitting keyspaces can help avoid write amplification issues as the dataset grows. By anticipating future growth, you reduce the need for heavy compactions and rebalancing operations later on.
- Optimize read paths with caching: Leverage the row cache or key cache depending on your access patterns. For frequently read small datasets, row cache can dramatically reduce read latency, while key cache improves index lookups for larger datasets.
Getting started with Apache Cassandra
Setting up Apache Cassandra using Docker is straightforward and helps you quickly spin up a development environment. These instructions are adapted from the official quick start guide.
Step 1: Get Cassandra using Docker
First, ensure you have Docker Desktop installed on your machine. You can pull the latest Cassandra image from Docker Hub using the following command:
|
1 |
docker pull cassandra:latest |
Step 2: Start Cassandra
Create a Docker network to allow access to the container’s ports without exposing them on the host:
|
1 |
docker network create cassandra |
Then, start a Cassandra container:
|
1 |
docker run --rm -d --name cassandra --hostname cassandra --network cassandra cassandra |
Step 3: Create a CQL script
Next, create a CQL script file named data.cql. The Cassandra Query Language (CQL) is similar to SQL but optimized for Cassandra’s distributed architecture. The following script creates a keyspace, a table, and inserts some data:
|
1 2 |
-- Create a keyspace CREATE KEYSPACE IF NOT EXISTS store WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' }; |
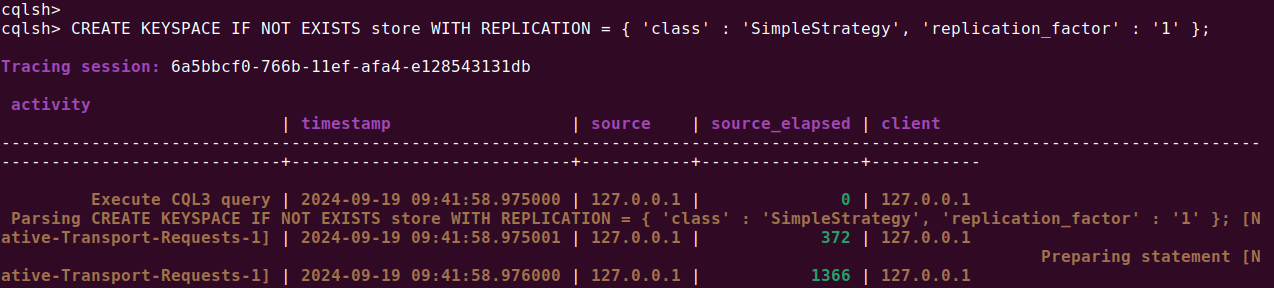
Note: Tracing is set to ON for the above request. Hence you see additional information
|
1 2 3 4 5 6 |
-- Create a table CREATE TABLE IF NOT EXISTS store.user_activity ( userid text PRIMARY KEY, item_count int, last_update_timestamp timestamp ); |

Note: Tracing is set to OFF for the above request. Hence you don’t see additional information
|
1 2 3 4 5 6 7 |
-- Insert some data INSERT INTO store.user_activity (userid, item_count, last_update_timestamp) VALUES ('776', 2, toTimeStamp(now())); INSERT INTO store.user_activity (userid, item_count, last_update_timestamp) VALUES ('365', 5, toTimeStamp(now())); |

Save this script in the data.cql file.
Alternatively, you can use cqlsh interactively to run CQL commands. Launch the interactive shell with:
|
1 |
docker run --rm -it --network cassandra nuvo/docker-cqlsh cqlsh cassandra 9042 --cqlversion='3.4.5' OR |
Note: If you have installed Cassandra directly on your server, you can directly run this from the command line using the following command. This will give you a prompt where you can execute CQL commands directly.
|
1 |
<Cassandara-installation-folder>/bin/csqlsh |
Step 4: Load data with CQLSH
Use the CQL shell (cqlsh) to load the data into Cassandra. Run the following command to load the script:
|
1 |
docker run --rm --network cassandra -v "$(pwd)/data.cql:/scripts/data.cql" -e CQLSH_HOST=cassandra -e CQLSH_PORT=9042 -e CQLVERSION=3.4.6 nuvo/docker-cqlsh OR |
Note: If you have installed Cassandra directly on your server, you can directly run from command line using the following command: (assuming data.cql exists in the same folder):
|
1 |
SOURCE ‘data.cql’; |
Step 5: Read some data
To read data from the table, execute the following query in the cqlsh shell:
|
1 |
SELECT * FROM store.user_activity; |

Step 6: Write more data
Insert additional data into the table using:
|
1 |
INSERT INTO store.user_activity (userid, activity_count) VALUES ('842', 20); |

Step 8: Clean up
After you are done, clean up by stopping the Cassandra container and removing the Docker network:
|
1 2 |
docker kill cassandra docker network rm cassandra |
Tutorial: Apache Cassandra and vector search
Now let’s take a look at a more advanced case study. Vector search in Apache Cassandra allows for efficient similarity queries on high-dimensional data, often used in machine learning and recommendation systems. This tutorial will guide you through setting up vector search using CQL (Cassandra Query Language).
Step 1: Create Vector Keyspace
First, create a keyspace to store your vector data. The following CQL command sets up a keyspace named ai_tweets:
|
1 2 |
CREATE KEYSPACE IF NOT EXISTS ai_tweets WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' }; |

Step 2: Use vector keyspace
Select the ai_tweets keyspace for the subsequent operations:
|
1 |
USE ai_tweets; |

Step 3: Create vector table
Next, create a table to store vector data. The table includes a tweet_vector column, which holds the vector values:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE IF NOT EXISTS ai_tweets.tweets_vs ( record_id timeuuid, id uuid, user_handle text, tweet text, tweet_vector VECTOR <FLOAT, 5>, created_at timestamp, PRIMARY KEY (id, created_at) ) WITH CLUSTERING ORDER BY (created_at DESC); |

You can use describe tables command to list all current tables in key store:

Alternatively, you can add a vector column to an existing table:
|
1 2 |
ALTER TABLE ai_tweets.tweets_vs ADD tweet_vector VECTOR <FLOAT, 5>; |
Step 4: Create vector index
Create an index on the tweet_vector column using storage attached indexing (SAI):
|
1 2 |
CREATE INDEX IF NOT EXISTS ann_index ON ai_tweets.tweets_vs(tweet_vector) USING 'sai'; |
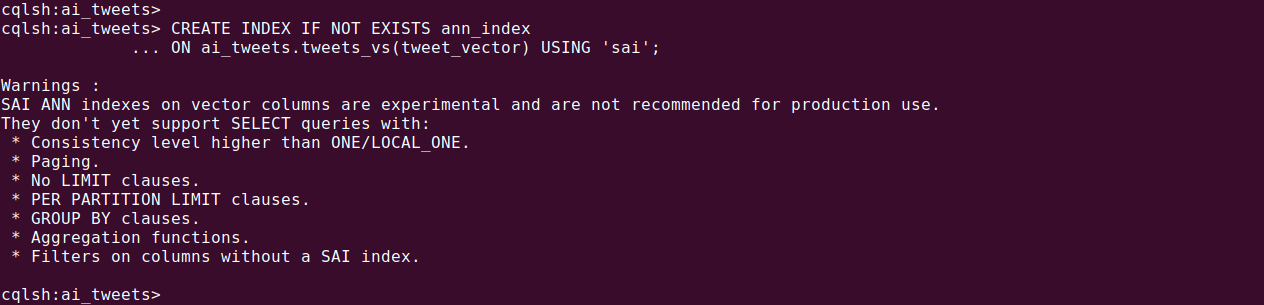
You can specify the similarity function in the index options:
|
1 2 3 |
CREATE INDEX IF NOT EXISTS ann_index ON ai_tweets.tweets_vs(tweet_vector) USING 'sai' WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' }; |
The valid values for similarity_function are DOT_PRODUCT, COSINE, and EUCLIDEAN.
Step 5: Load vector data
Insert sample data into the tweets_vs table. Each vector consists of five float values:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), e7ae5cf3-d358-4d99-b900-85902fda9bb0, '2023-08-14 12:43:20-0800', 'AI is transforming industries at an unprecedented rate.', 'tech_guru', [0.45, 0.09, 0.01, 0.2, 0.11]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), e7ae5cf3-d358-4d99-b900-85902fda9bb0, '2023-08-15 13:11:09.999-0800', 'The future of AI is in decentralized systems.', 'tech_guru', [0.99, 0.5, 0.99, 0.1, 0.34]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), e7ae5cf3-d358-4d99-b900-85902fda9bb0, '2023-08-16 06:33:02.16-0800', 'Generative AI models are the next big leap.', 'tech_guru', [0.9, 0.54, 0.12, 0.1, 0.95]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), c7fceba0-c141-4207-9494-a29f9809de6f, totimestamp(now()), 'AI ethics should be a top priority.', 'ai_advocate', [0.13, 0.8, 0.35, 0.17, 0.03]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), c7fceba0-c141-4207-9494-a29f9809de6f, '2023-08-17 12:43:20.234+0400', 'Excited about the advancements in AI healthcare.', 'ai_advocate', [0.3, 0.34, 0.2, 0.78, 0.25]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), c7fceba0-c141-4207-9494-a29f9809de6f, '2023-08-18 5:16:59.001+0400', 'AI in finance is revolutionizing trading.', 'ai_advocate', [0.1, 0.4, 0.1, 0.52, 0.09]); INSERT INTO ai_tweets.tweets_vs (record_id, id, created_at, tweet, user_handle, tweet_vector) VALUES (now(), c7fceba0-c141-4207-9494-a29f9809de6f, '2023-08-19 17:43:08.030+0400', 'AI-generated content is becoming indistinguishable from human-created content.', 'ai_advocate', [0.3, 0.75, 0.2, 0.2, 0.5]); |
You can execute the following query to check if data is inserted correctly:
|
1 |
SELECT * FROM ai_tweets.tweets_vs |
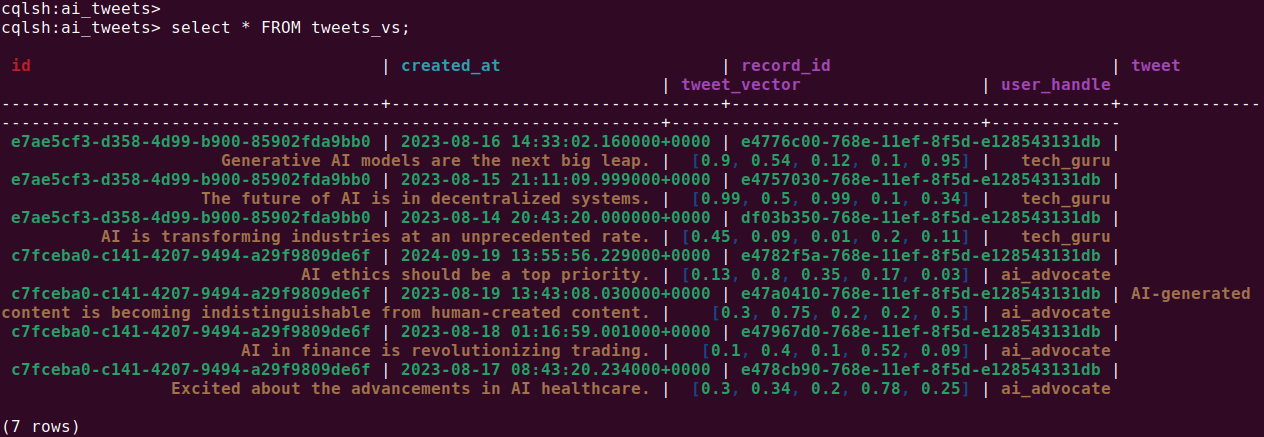
Step 6: Query vector data
Query the vector data using a similarity function, such as ANN (Approximate Nearest Neighbors):
|
1 2 3 |
SELECT * FROM ai_tweets.tweets_vs ORDER BY tweet_vector ANN OF [0.15, 0.1, 0.1, 0.35, 0.55] LIMIT 3; |
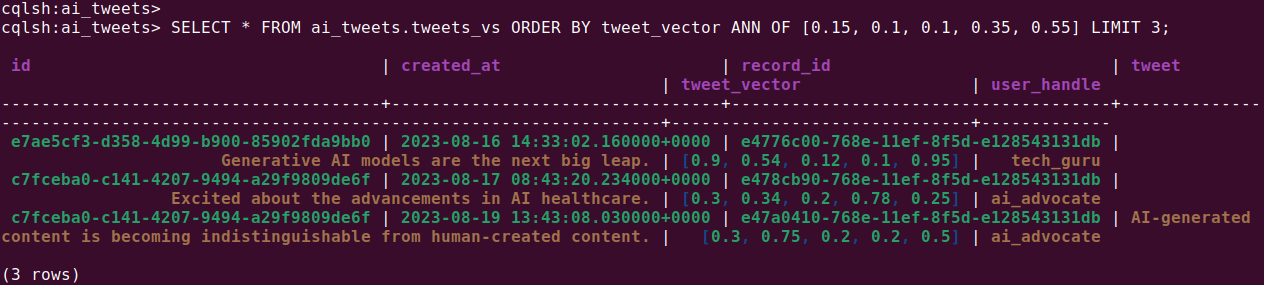
To include the similarity calculation in the results:
|
1 2 3 4 |
SELECT tweet, similarity_cosine(tweet_vector, [0.2, 0.15, 0.3, 0.2, 0.05]) FROM ai_tweets.tweets_vs ORDER BY tweet_vector ANN OF [0.1, 0.15, 0.3, 0.12, 0.05] LIMIT 1; |

The supported similarity functions are similarity_dot_product, similarity_cosine, and similarity_euclidean.
By following these steps, you can set up and utilize vector search in Apache Cassandra, enabling efficient and scalable similarity searches within your database.
NetApp Instaclustr: Simplifying Apache Cassandra deployment and management
Apache Cassandra has emerged as a popular choice for managing large-scale, distributed databases due to its scalability, fault tolerance, and high performance. However, deploying and managing Cassandra clusters can be complex and time-consuming. That’s where NetApp Instaclustr comes in. NetApp Instaclustr simplifies Apache Cassandra deployment and management, empowering organizations to leverage the full potential of this powerful NoSQL database.
NetApp Instaclustr takes the hassle out of deploying Apache Cassandra clusters by providing a streamlined and automated process. With just a few clicks, organizations can create and configure Cassandra clusters in the cloud, eliminating the need for manual setup and reducing deployment time significantly. This allows developers to focus on their applications rather than spending valuable time on infrastructure management.
NetApp Instaclustr handles the underlying infrastructure for Apache Cassandra, ensuring high availability, fault tolerance, and data replication. It takes care of tasks such as cluster provisioning, software updates, and security patches, relieving organizations of the operational burden. This managed infrastructure approach allows businesses to scale their Cassandra clusters seamlessly and focus on building robust and scalable applications.
One of the key advantages of Apache Cassandra is its ability to scale horizontally to handle massive workloads. NetApp Instaclustr fully leverages this capability by providing seamless scalability for Cassandra clusters. As data volumes grow, organizations can easily add or remove nodes to meet their changing needs, ensuring optimal performance and responsiveness. This scalability empowers businesses to handle increasing data demands without sacrificing performance.
NetApp Instaclustr places a strong emphasis on data security and compliance. It offers robust security features, including encryption at rest and in transit, role-based access control, and integration with various identity providers. This ensures that sensitive data stored in Apache Cassandra remains protected from unauthorized access. Additionally, NetApp Instaclustr helps organizations meet regulatory compliance requirements by providing audit logs and facilitating data governance.
NetApp Instaclustr provides comprehensive monitoring and support services for Apache Cassandra clusters. It offers real-time monitoring capabilities, allowing organizations to gain insights into cluster performance, resource utilization, and potential bottlenecks. In case of any issues or failures, NetApp Instaclustr’s support team is readily available to provide assistance and ensure minimal downtime.
Managing and maintaining Apache Cassandra clusters can be costly, especially when it comes to infrastructure and operational expenses. NetApp Instaclustr helps optimize costs by offering flexible pricing models. Organizations can choose from pay-as-you-go options, allowing them to scale resources based on demand and pay only for what they use. This eliminates the need for upfront investments in infrastructure and provides cost predictability.
For more information: