






















PostgreSQL® stands out as a powerful enterprise-grade, open source relational database management system, steadily evolving and gaining popularity for over 30 years. Renowned for its robustness, extensibility, and high concurrency, PostgreSQL has become the go-to database solution for numerous organizations across the globe.
This blog will explore the fundamentals of PostgreSQL architecture, providing an overview of its various components and their interactions. By better understanding these elements, you will be equipped to optimize your database performance, troubleshoot issues, and make informed decisions when designing and scaling your applications.
What Is PostgreSQL?
PostgreSQL is an open source object relational database management system used for transactional and analytical workloads. It incorporates and expands upon the SQL programming language, offering an array of features designed to securely store and efficiently scale even the most complex data workloads. Tracing its roots back to 1986 as part of the POSTGRES project at UC Berkeley, it has over 35 years of constant development.
Why Should You Use PostgreSQL?
PostgreSQL has quickly become a popular choice among database solutions largely due to its comprehensive features that address various aspects such as performance, security, programming extensions, and configuration options.
It supports writing database functions in multiple languages, including SQL, Perl, Python, Java, Lua, shell, and JavaScript. PostgreSQL offers a diverse range of data types, from common database primitives to network addresses, geometric types, monetary types, ranges, JSONB, hstore, and multidimensional arrays, as well as the ability to define custom complex types.
The database system offers full-text search capabilities, robust authentication, access control, and privilege management suitable for organizations of all sizes. Furthermore, PostgreSQL provides foreign data wrappers for accessing remote server data, views, and materialized views for simplified data access, and allows comments on database objects to document decisions and implementation details. With JSONB document storage and hstore key-value pairs, users can not only store semi-structured data side-by-side with relational data but also can access it over SQL statements.
Basic Architecture of PostgreSQL System
Like other solutions, PostgreSQL architecture adheres to the client-server model. Its primary program operates as a service responsible for defining data structures, storing data, and processing queries.
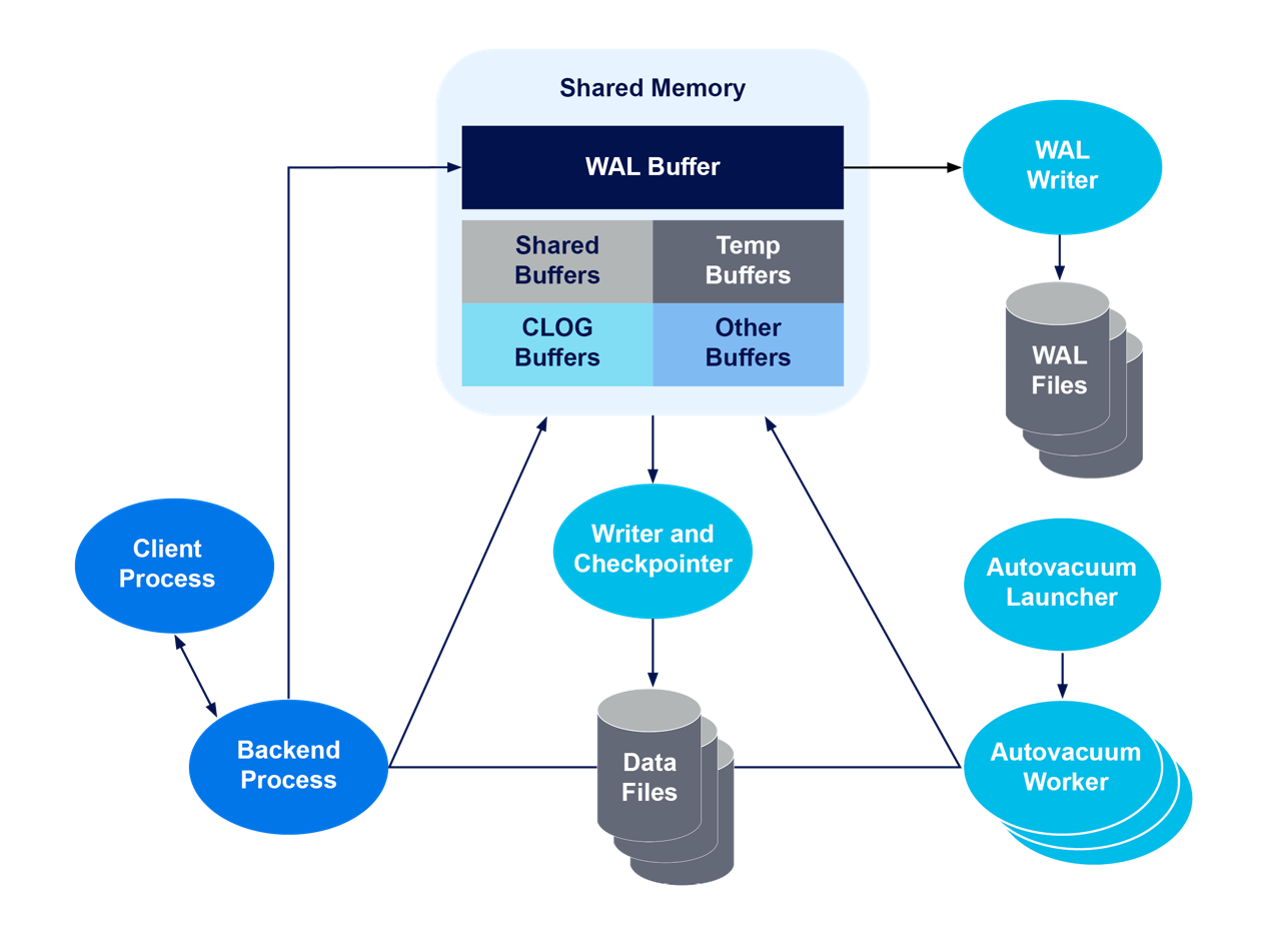
This architecture enables a PostgreSQL system to cater to multiple clients, connecting either locally or through network. When the master process receives a client connection, it forks (ie, the creation of an independent process that will consume CPU and RAM and executes on its own) a new process dedicated to that specific connection. If multiple clients are connecting, each client gets a forked process.
Since each forked process consumes CPU cores and RAM, the number of clients connecting to the server simultaneously are limited by the available cores and RAM. Any new client requests after the server resources are exhausted will be declined. In such cases, clients have to retry.
A mechanism called Connection Pooling will address this issue. Connection poolers initiate several connections to the server during the connection pooler startup and serve them to the client as the requests come in. If all the available connections are served, the new requests will be queued and will be served as soon as one becomes available. Connection poolers not only address the connection issues, but also improve the performance of the database by avoiding the connection creation times for each new client request.
PostgreSQL Process Types
PostgreSQL encompasses a variety of processes, each with its unique role in ensuring smooth database operations. Broadly these processes are classified into following 3 categories:
- PostgreSQL Server Process
- Backend Process
- Background Worker Process
PostgreSQL Server Process (previously known as Postmaster)
This process is the main supervisor, responsible for managing client connections and starting new backend processes. It listens for incoming client connection requests and orchestrates seamless communication between clients and the database.
Backend Process
A backend process is initiated for each client connection. It takes care of executing queries and handling database transactions on behalf of the client. Backend processes communicate directly with the client, ensuring efficient database operations.
Background Worker Process
Unlike PostgreSQL server and backend process, background worker process has several sub-types of process each doing a specific task. These processes perform essential background tasks that do database maintenance and system-wide administration and are not associated with a specific user connection. By working behind the scenes, background processes help maintain database health and optimize performance.
PostgreSQL Memory Management
Memory plays a vital role in the inter-process communication and performance of the PostgreSQL database. Memory in PostgreSQL can be broadly classified into 2 based on how they are used:
- Local Memory: Used by individual backend processes for running the queries
- Shared Memory: Used by the PostgreSQL Server process.
Shared Memory
As Postmaster forks a new process for every client connection, it becomes important to have communication between these processes to exchange individual process information and other data. While there are several ways to perform inter-process communication, PostgreSQL leverages shared memory for exchanging the data between the process. Besides storing process data, shared memory also stores table data.
Shared Memory comprises 2 key components: the Shared Buffers and WAL (Write-Ahead Logging) Buffers. Both elements work together to enhance database operations and maintain overall efficiency.
-
Shared Buffers
The shared buffer serves as a cache for all IO operations. The process reads and writes from and to shared buffers. When a process requires to read a tuple (a record), it goes to the shared buffer to fetch it. Typically, frequently accessed data is stored in share buffers and by reading from memory the process significantly reduces the time consumed by disk reads (disk reads happen only when the data is not present in shared buffers) and thus improving overall performance and response times.
-
WAL Buffers
WAL (Write-Ahead Log), is a log of all the transactions performed on the database. WAL is the Postgres method for resiliency, in the event of a system crash or failure, WAL is used to recover the uncommitted transactions, safeguarding the integrity of the database. WAL is written to disk and to improve the performance of the WAL, WAL buffers are leveraged. Background process writes to the WAL buffers, and these buffers are written to the disk either synchronously on every commit or asynchronously at regular intervals.
PostgreSQL Database Structure
Logical Structure
A cluster in PostgreSQL is a collection of databases, hosted and managed by a single server. A database is a collection of schemas. A schema contains database objects such as tables, views, and indexes into logical groups. This organization makes it easier to manage and maintain related objects.
PostgreSQL uses a set of tables called Catalog Tables to store the information about these database objects. Some catalog tables are global and shared across all the databases, and some are specific to the database and are copied over from template during the database creation time.
Tables form the backbone of any database. In PostgreSQL, they consist of rows and columns, where each row represents a record, and each column signifies a field of data. Tables store the data and are defined according to a specific structure or schema. Indexes are indispensable for optimizing database performance, enabling faster data retrieval.
An index references specific rows in a table based on one or more columns, allowing PostgreSQL to quickly locate relevant data without scanning the entire table. On the other hand, views are virtual tables derived from one or more underlying tables or other views. They don’t store data themselves but represent a subset of data from the original source, which is useful for encapsulating complex queries and simplifying data access for end-users.
Finally, constraints are rules applied to columns or tables that help maintain data integrity and consistency within the database. They enforce specific conditions, such as ensuring uniqueness, validating data formats, or establishing relationships between tables.
Physical Structure
PostgreSQL provides architecture that enables efficient storage of logical objects in physical files. Each database will have its own directory and each table in the database will be a file within the directory. Besides some system tables, PostgreSQL writes the data into heap files, a type of file organization used to store and manage data in a database.
In a heap file, data is organized as a collection of records, each of which has a fixed length and occupies a fixed amount of space on disk. The records in a heap file are not stored in any particular order but are simply appended to the end of the file as they are inserted. The heap file of 1 GB size (default size but can be modified) is organized as a collection of pages of 8KB size (default size but can be modified), each of which can hold multiple rows of data. PostgreSQL writes into a new file when the file fills up and thus a table can span across multiple files.
PostgreSQL Roles and Privileges
The combination of roles and privileges in PostgreSQL ensures that database resources are accessed securely and responsibly. Administrators can fine-tune access levels for various users, ensuring they have the necessary permissions to perform their tasks without compromising the integrity of the data or the database system.
Roles can be assigned to individuals, allowing them to perform specific tasks, such as creating tables or executing queries. They can also be grouped to form more extensive roles, making managing permissions for multiple users at once easier. Roles help maintain a secure and organized database environment by granting the right level of access to different users based on their responsibilities.
Privileges define the actions that a role can perform within the database. For example, privileges can dictate whether a role can read, insert, update, or delete data in a particular table or column. They can also control access to other database objects like views, indexes, and schemas. In PostgreSQL, privileges are assigned to roles, which are then granted to users or other roles.
PostgreSQL Object Hierarchies
PostgreSQL employs an object hierarchy for effective data organization and management. The hierarchy comprises clusters, databases, schemas, tables, columns, indexes, views, functions, triggers, and sequences.
Clusters are collections of PostgreSQL databases managed by a single server instance, with databases as primary containers for data storage. As mentioned, schemas serve as namespaces for organizing database objects, while tables store data records with columns representing individual attributes. Indexes offer quick data retrieval; views are virtual tables based on stored queries.
Functions are user-defined code routines, triggers are functions executing automatically in response to specific events, and sequences generate unique incremental numeric values. This hierarchical structure streamlines data organization and manipulation in PostgreSQL databases.
Replication, Load Balancing, and High Availability
Replication is a technique that maintains multiple copies of the database across different nodes, which helps improve data availability, fault tolerance, and read performance. PostgreSQL supports 2 types of replication: physical and logical.
Physical or streaming replication involves replicating the entire database cluster, including the data and the WAL files. Logical replication, on the other hand, focuses on replicating specific tables or databases by interpreting and applying the changes recorded in the WAL. With these built-in replications, PostgreSQL can be designed for High-Availability (HA), and Disaster Recovery (DR) with desired RPO (Recovery Point Objective) and RTO (Recovery Time Objective).
Load balancing refers to distributing database queries and workloads across multiple servers or nodes, which can enhance performance and ensure optimal resource utilization. In PostgreSQL, load balancing can be achieved using connection poolers like PgBouncer or Pgpool-II, efficiently managing client connections and distributing read queries among the available replicas.
High-availability is a key requirement for mission-critical applications, and PostgreSQL provides several options to ensure continuous operation, even in the event of hardware failures or network issues. A common approach involves setting up a primary-replica architecture, where a standby or replica server takes over the primary server’s role in case of a failure. Patroni is one of the popular cluster managers used for HA in PostgreSQL.
Final Words
Understanding PostgreSQL architecture is fundamental to unlocking the true potential of this powerful open source database system. By comprehending its inner workings, from its storage and indexing mechanisms to its query processing and optimization strategies, you’re better equipped to tackle database challenges, optimize performance, and ensure data reliability in your projects.
While PostgreSQL is a low maintenance database, there are few things that should be taken care of frequently such as vacuum, reindexing, log file management, etc. for efficient and steady operation of PostgreSQL. Setting up for HA, scaling for workloads, and fine-tuning processes for performance and accuracy of the queries requires deeper expertise in the inner workings of PostgreSQL. Instaclustr Managed Service for PostgreSQL is a fully hosted and managed service, allowing you to focus on building and scaling applications knowing that our experts are managing the complexities of your PostgreSQL database.