






















1. Introduction
 (Source: Shutterstock)
(Source: Shutterstock)
Viewing online cat media is linked with procrastination (Emotion regulation, procrastination, and watching cat videos online: Who watches Internet cats, why, and to what effect?)—this blog almost ended here!
Recently I came across 2 use cases of real-time Kafka Machine Learning (ML). Have you ever wondered why TikTok is so addictive for millions of users? (No, me neither, although I assumed it was something to do with cat videos?) Apparently, it’s actually due to their real-time Kafka ML which enables the recommendation model to interactively adapt according to user’s preferences in real-time, to ensure they are hooked on a customized stream of engaging content. It’s a combination of batch and online/incremental training according to their paper “Monolith: Real Time Recommendation System With Collisionless Embedding Table”.
The second use case I came across was from Uber in this blog, “How Uber Optimizes the Timing of Push Notification using ML and Linear Programming”. They use ML to (1) predict the optimal time slots to send push notifications to customers, (2) schedule by sending customer-specific notifications/timeslots to Kafka topics (1 per hour), and finally (3) high throughput delivery using Cadence® (a workflow engine) to turn the Kafka topics “on” at the correct time—basically by turning Kafka consumers on and off for specific topics. This is an unusual (but logical, as it has long-running scheduling) use of Cadence, but pretty clever!

A slightly confused robot
(Source: Paul Brebner, MSc Thesis, 1985)
These 2 use cases are obviously sophisticated applications of ML, so I decided to revisit what I already know about ML. Once upon a time, my research area was ML—actually the hardest sort—autonomous, unsupervised, active incremental learning in robot worlds with simulated gravity and physics (Paradigm-directed Computer Learning, 1985, a more recent blog).
The task of the robot was to learn how to interact with the world, and what the “rules” of the world were. It started out with no knowledge, and had to come up with “theories”, plan and conduct experiments, and revise theories based on the outcomes. Like TikTok, I also used a combination of incremental and batch learning (but started out with incremental learning until there were sufficient observations to use batch learning).

“C” is for Cat!
(Source: Flickr — The Mark 1 Perceptron circa 1960 (Public Domain))
Machine learning with neural networks was also around in those days (the 1980s) but was considered to be merely a historical curiosity by then. Dating from the 1940s, they didn’t work with first-order data, they needed enormous numbers of observations to train, they couldn’t learn complex non-linear models, and the resulting models were incomprehensible to humans.
However, by the 1990’s some of these deficiencies had been overcome (e.g., backpropagation for efficient training of multi-layered neural networks, combined with Markov models, and use of GPUs for training, etc.) and they are now very much back in fashion. They can also be trained incrementally—each observation slightly modifies the neural network weights, and the same observations can be used for training more than once (this is called “epochs”).
Fast forwarding to 2017, my first foray into blogging for Instaclustr was the 10-episode 2001 “Space Odyssey” themed introduction to Cassandra, Spark, and MLLib (Parts 1, 2, 3, 4, 5, 6, 7, 8, 9, 10). I used the 2001 theme as I was learning Cassandra and Spark from scratch during the series, which was like trying to understand the impenetrable Monoliths in the movie, with eventual enlightenment.
The goal in the series was to apply Machine Learning (using Spark MLLib) to enormous amounts of machine data (100s of hours of monitoring and 1000s of metrics) from our managed Cassandra clusters, to predict future performance. Some of the sub-topics included how to model time-series data in Cassandra (buckets are your friend), regression analysis, getting and using features, training and testing different types of decision tree models (which also date from the 1980’s), building pipelines, data cleaning, exploring data with Apache Zeppelin™, and using Spark Dataframes and streaming data.
Another blog series (Parts 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) is also related to ML (It was presented at ApacheCon USA 2019 and ApacheCon EU 2019 in the Machine Learning track). “Anomalia Machina” is Latin for “Anomaly Machine”. This series was designed to build a demonstration application that could use both Cassandra and Kafka (and Kubernetes to run the Kafka consumers and the Cassandra clients) and get some “big” performance numbers. Because we wanted the application to test out the data layers in particular, we picked a simple “CUSUM” anomaly detection algorithm that processes an incoming data stream and compares each event with a fixed window of previous values for the same key—basically, the anomaly detection model is rebuilt for each incoming event—extreme incremental learning!
It’s designed to work with billions of keys and billions of anomaly checks a day. Potential applications are numerous including infrastructure and applications, financial services and fraud, IoT, web click-stream analytics, etc. At least parts of this architecture are likely to be common for many streaming machine learning use cases, as it includes an incoming event stream, persisting events for use in model training, a model that must be kept up to date and available, and the ability to apply the model to the event stream to make new predictions—with low latency and at scale. Here’s the architecture we used for Anomalia Machina:
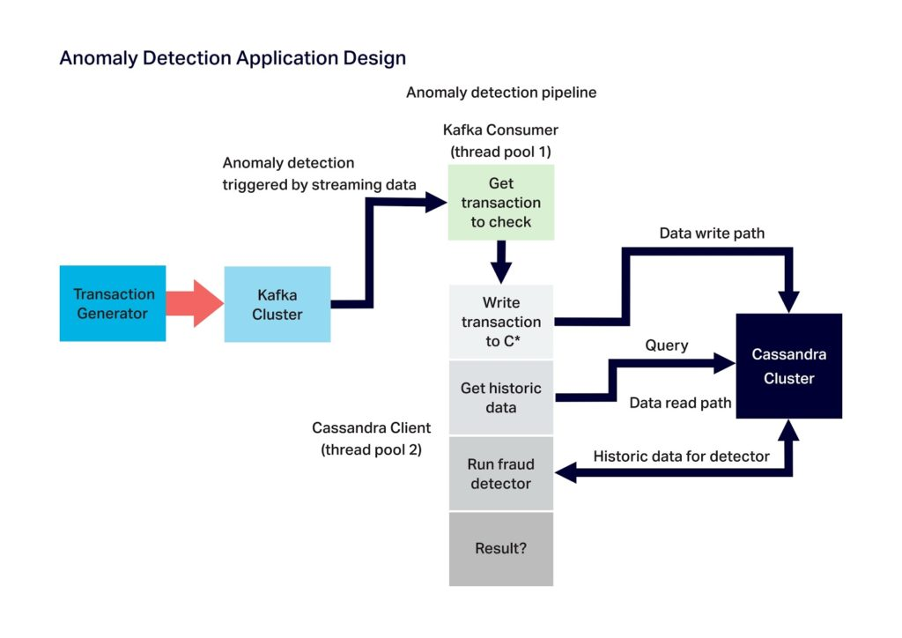
We also extended this experiment for Geospatial Anomaly Detection in a 4-part series (Part 1, 2, 3, 4). Anomaly Detection/ML over spatial data is more demanding, and we explored a variety of solutions including: bounded boxes, Cassandra clustering columns, secondary indexes, SASIs, Geohashes, denormalized tables, and the Cassandra Lucene Index Plugin—some performed better than others.
2. The Incremental Learning Problem

Car drifting is fast (and potentially dangerous),
this stunt is performed by a professional driver on a racing track.
(Source: Shutterstock)
So, in general, what’s special about incremental or online learning from streaming data? Here are the main characteristics that I can think of—basically big, fast, and changing:
- Big Data: ML requires enormous amounts of data. What happens if it can’t all fit into memory at once to train a model? I eventually ran out of RAM during my encounter with the “Monolith” in my Spark ML experiments. Now, streaming data is by definition “infinite”, so there’s no point in even trying to fit it all into RAM, so incremental learning is really the only possible approach.
- Fast Data: Streaming data arrives continuously—it’s fast. One of the obvious challenges with learning from streaming data is to ensure that the model is up to date so that predictions using new observations are accurate. You, therefore, need to be able to train in real-time and make predictions in real-time too.
- Changing Data: The world doesn’t stay the same, and this is often reflected in streaming data—it changes over time. This is called Concept Drift—which can be slow (continental drift) or fast (car drifting!). How training adapts to concept drift is therefore a major challenge for streaming ML.
3. The Drone Delivery Application ML Use Case

The Sky is Full of Drones
(Source: Shutterstock)
Recently I’ve developed a demonstration real-time Drone delivery application using Uber’s Cadence and Apache Kafka (Parts 1-6). I wondered if I could use this as a test bed for another round of ML experiments, this time focusing on Kafka streaming ML. It seemed like a good use case, as it generates massive amounts of streaming data in real-time related to drone flights and order workflows, and includes spatial data such as the drone location over time, and the starting, shop, and customer locations etc.
I also thought it would be interesting to introduce “anomalies” into the deliveries easily enough (e.g., geofenced areas introducing delays, drone collisions, birds attacking drones, etc.), but eventually settled on another learning problem focusing on the stores themselves. This was inspired by a talk I heard at ApacheCon 2019 from Uber about how they use ML to predict “busy” locations so that Uber drives can be prepared for surges in demand (“GeoSpatial and Temporal Forecasting in Uber Marketplace—Chong Sun, Brian Tang”, summarized here). The idea is to categorize each store as either busy or not busy for each hour of the drone delivery day (we assume that drones are only allowed to fly in daylight hours) based on the number of orders they receive each hour.
To start with I’m only using this hourly summary data, rather than all the individual orders. We also assume that there is a vector of features for each store for each hour including the class label (busy/not busy), and features including the store ID, the day (1-7), the hour of day, the store type, the store location (an integer representing a suburb), and a few other pieces of data to make it more interesting including the average delivery time and distance, the average customer feedback rating, etc. For simplicity, these are all integers.
We generated data for several weeks of drone deliveries and orders, using some simple rules to determine if a particular store is busy or not for each hour (basically a combination of shop type, day and hour). To keep things simple (and repeatable) initially I just used an Excel spreadsheet to do this and generated a CSV file of observations—there were about 6000 observations and 200KB of data per week.
4. Choosing a Kafka ML Framework
The next obvious question was what Kafka ML frameworks should I try out? A Google search found some obvious candidates including:
- Kafka-ML: An open source framework for Kafka ML with TensorFlow or PyTorch, with deployment on Kubernetes. This looked interesting and mentioned that it supports incremental learning with TensorFlow.
- TensorFlow and Kafka: There is basic support for both batch and online learning in TensorFlow with Kafka itself, so that’s worth a look. TensorFlow is an open source neural network ML framework that learns from tensors (matrices of numbers)—lucky that’s what I have as observations.
- Spark Kafka integration: It’s been a while since I’ve looked at Apache Spark™ ML (but I have kept up with recent developments, including some good talks at ApacheCon NA 2022 in the inaugural Performance Engineering track), and apparently, it has support for Kafka integration. So that could be worth exploring too, particularly as I have some new colleagues who are experts in running Spark on Spot instances—Ocean for Apache Spark.
We’ve obviously picked a hot topic to blog about given the abundance of supporting frameworks. I picked one of the potential frameworks to investigate further: Option 1, Kafka-ML, using Kubernetes, TensorFlow and Kafka at the same time.
However, I quickly realized I had “bitten off more than I could chew” because I was trying to understand and test 3 ML problems at once: TensorFlow; Kafka-ML; and learning from Kafka streaming data! So, I decided to backtrack (drift perhaps) to something more basic and easier to understand, control and evaluate: Option 2, using TensorFlow with CSV data. Being human we need to approach the problem “incrementally” as well.
So that’s where I’m headed next. In Part 2 of this series, we’ll look at TensorFlow in more detail, understand some of the TensorFlow results metrics (so we can see if it’s working properly), and try it out in simple batch mode using drone data from the Spinning Your Drones series.