Welcome back! This series–Learning OpenSearch from Scratch–explores my learning process for OpenSearch®. My aim of this series is more conceptual; if you’re looking for a hands-on tutorial using OpenSearch, check out my OpenSearch 101 post and video.
In the first post I covered the basics of OpenSearch. Now, at this point in the learning journey, I had two thoughts moving forward:
- Learning the inner workings of OpenSearch: Now that I see how it works as a single tool and interfaced with the API, how does OpenSearch handle indexing and searches? What does a running OpenSearch cluster look like? I wanted to take it apart a bit and see the parts interacting; this is how I usually learn more about things. Which one of us never took apart a toy, an appliance, a computer, to see what was going on inside to learn more?
- What is Apache Lucene™? How does OpenSearch use it? What does OpenSearch add to Lucene?: I felt like knowing more about the library which OpenSearch is based on would teach me a few things about OpenSearch as a framework. This, after all, looks to be at the core of OpenSearch.
I’ll elaborate in this post on what I learned going down these two paths.
Looking under the hood of OpenSearch
I set out for information about the different parts and components of OpenSearch so I could see what a running OpenSearch cluster actually looks like.
What are the parts of OpenSearch?
At the core of the search engine component is Apache Lucene (which I’ll cover shortly). There are also several other components that make up the OpenSearch architecture: OpenSearch Dashboards, Data Prepper and Client libraries.
Search (Apache Lucene): this component is central to OpenSearch, comprised of Lucene augmented with various functionalities that allow OpenSearch to be a comprehensive search framework. This includes its own data store which creates a performant system to read, update, and search Lucene indexes.
OpenSearch Dashboards: this component is a web application that allows you to query, manipulate, and visualize your OpenSearch data into dashboards and other useful formats in a web UI.
Data Prepper: Data Prepper is an application that helps OpenSearch users pre-process and ingest existing data lakes into your OpenSearch cluster. It facilitates creating pipelines that pre-process and transform your data before indexing it in OpenSearch.
Client libraries: These are libraries that are written in various programming languages that allow users to easily connect to and use their OpenSearch cluster. Examples include the Node.js package, Rust crates, and the Python library.
These components make up what we see as OpenSearch. They all work together to create a scalable, flexible search platform.
What does a running OpenSearch cluster look like?
An OpenSearch cluster is made up of at least 3 types of nodes, or node “roles”:
- A cluster manager node: This node manages and keeps track of the state of the overarching cluster. It also creates and deletes indexes from clusters and allocates shards to other nodes.
- The key purpose of the coordinating node is watching over the nodes in the OpenSearch cluster and performing actions that require multiple cluster nodes. In production clusters, it is recommended you have multiple dedicated manager nodes in different availability zones. OpenSearch also has the functionality for consensus-based manager elections, in which nodes that are “manager eligible” can be promoted. You can label nodes as manager eligible in configuration.
- A coordinator node: This node delegates data requests to the data nodes and aggregates the results to send back to the requester. It is vital for search functionality as searches need to be coordinated, and the results from the different nodes compounded into a single result.
- On search-heavy workloads, you may have a bottleneck if you have too few coordinator nodes. Note that any node can be a coordinator node; you can have a data node act as a coordinator, for example.
- One or more data nodes: These nodes contain your OpenSearch indexes and documents in the form of Lucene indexes and segments. They also perform all data tasks on local shards (indexing, searching, aggregating, deleting). These tasks come from the coordinator nodes.
- Because these are the nodes that store the data, they require the most disk space. Data nodes can also be configured to be “cluster manager eligible”, meaning it can through the election process be “promoted” to a cluster manager node.
There are other types of nodes that can be used in an OpenSearch cluster (there’s a complete list in the docs). A few notable types include:
Dashboard: a dashboard node runs the OpenSearch dashboards server, which allows you to query and visualize your data in dashboards and other formats using a web UI.
Ingest: These are nodes dedicated to taking in and transforming data to be stored in the OpenSearch cluster. They run what are called ingest pipelines that pre-process your OpenSearch data. These are useful for complex ingestion processes and indexing-heavy clusters. You can also optionally delegate indexing to ingest nodes, freeing up your other nodes for search and aggregation.
Dynamic: These are nodes that perform custom work; one common use case is Machine Learning (ML) tasks. These nodes allow you to offload tasks that OpenSearch does not perform, without using OpenSearch node resources. These mean you can run complex tasks inside your OpenSearch cluster without affecting OpenSearch’s performance.
All of these nodes communicate with each other using a discovery system and unicast (one-to-one) messaging system and join a configured cluster. Visually, it looks a little like this:
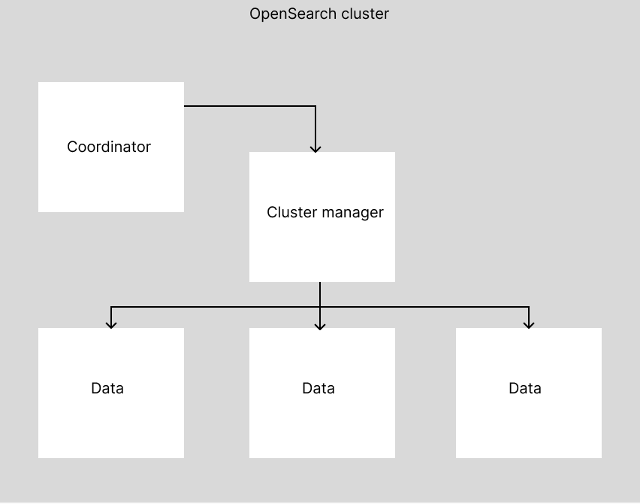
As you can see here, the coordinator node interacts with the cluster manager node(s), which interacts with the data node(s).
Now that I’ve covered what an OpenSearch cluster looks like, I’ll go into how data is indexed and searched in OpenSearch, and some terminology related to OpenSearch’s inner workings.
How does OpenSearch handle data when it is indexed and searched?
One of the things that makes the internals of OpenSearch interesting is that it stores data in multiple places: a transaction log, or translog, and in Lucene indexes. To understand why it’s done this way, I’ll dive into what happens when you index and search data in OpenSearch.
The translog
The translog is a key component of OpenSearch infrastructure; it stores transactional data operations that are meant to be made to the cluster. When a transaction is in the translog, it cannot be searched yet and is not durable. That’s because there are a few steps in the process to get a change from the shard’s translog into a durable and searchable state.
At the core of this process is fsync, a process that syncs a file’s in-core state with its storage device. This makes the data durable, as once this is done the data is written on-disk in the shard.
The Update process
When an OpenSearch cluster receives an update or search request, the coordinator node for the cluster takes the request, breaks it up, and delegates the file changes to the data nodes with the primary shards needed through the cluster manager node.
Once the primary shard has the request, it then places it in its translog, which is a file stored in-memory. The updated translog is then eventually “flushed” to disk, meaning that the data from the file in-memory is updated to match the new request. An fsync is then run on the translog, meaning the request is now durable (written to disk). However, data in the translog is not searchable yet; first a refresh is run.
A refresh is run periodically on the cluster; this writes documents from the in-memory Lucene index to Lucene storage (however, an fsync is NOT run). Each buffer is written in its own Lucene segment. At this point, the updates are searchable, but there is no guarantee to durability, as an fsync is not performed. That is done in the next step: flush.
Flushing is done periodically by OpenSearch to ensure translogs do not grow too large. A flush persists the Lucene indexes to disk using fsync; this ensures durability in the updated data. At this point, the translog records are no longer needed and are purged.
So, in summary, when a cluster receives an update:
- The coordinator node delegates that update to a primary shard on a data node
- The shard then adds this update to its translog, which will periodically flush its content to disk with fsync.
- Eventually, a refresh will occur, which allows the updated data to be searched by writing the update to the Lucene index.
- Finally, a flush operation will occur that fsyncs the updated indexes to disk, making them durable.
- The updates that have been flushed are purged from the translog
There are other processes that occur because of these events; for instance, if an update is made to a primary shard, its secondary shards need to be updated as well.
I’ve mentioned Apache Lucene a few times in discussing OpenSearch. Now is a good time to go into what Lucene is, how it works, and what OpenSearch adds to Lucene.
What is Apache Lucene?
Apache Lucene is a search engine library written in Java and a project of the Apache Foundation, under the Apache 2.0 software license.
Immediately, you can draw a few more conclusions: it is open source by nature of its licenses, and running on the JVM means it supports many different platforms and operating systems. From the website, Lucene presents itself as a performant, efficient search library that can run on many platforms.
Now that you know what Lucene does, you’ll learn a little about how Lucene works.
How does Apache Lucene work?
Lucene takes in data, analyzes it, and indexes it in a reverse index.
When it takes in data, it is usually in the form of blocks of text. Lucene analyzes this text, “tokenizing” it (splitting it into words), removing stop words and common words, formatting the text case, etc. It then stores the tokens that come out of the analyzer in a reverse index. This means that it builds an index that is accessed by a token value and is assigned the locations of that token in your documents; think of the index in the back of a reference book.
When you go to search Lucene data, it uses this index. Instead of reading full text blocks to ascertain where certain tokens are, Lucene just pulls that information from its reverse index. This makes Lucene extremely performant.
Lucene is a powerful search engine library; next I’ll go into what OpenSearch does to augment Lucene and be a full search platform.
What does OpenSearch add to Lucene?
There are a lot of things that could be mentioned here, but I will stick to the major points that OpenSearch adds:
Scalability: Lucene does not have scaling or cluster capabilities; OpenSearch creates this with its clustering capabilities. OpenSearch clusters can scale quickly and easily due to the way the nodes communicate and manage themselves.
Platform: Lucene does search well, but it is a search engine at core; OpenSearch provides a full platform to interact with and monitor your data across your clusters.
Features: Things like visualization capabilities, OpenSearch dashboards, and the querying languages made available by OpenSearch make your Lucene data much easier to manage and see as a whole.
Summary and next steps
For the next step in my learning process, I took a look at the components of OpenSearch: Search, with Apache Lucene at its core; Dashboards, which allows data visualization and querying; and Data Prepper, which takes in and transforms existing data to be indexed in OpenSearch.
Then I covered what a running OpenSearch cluster looks like; the three roles that make up a base cluster: the coordinator, the cluster manager, and the data node. I also covered a few other types of nodes that can show up in an OpenSearch cluster.
Next in my research was how OpenSearch handles new and updated data: I covered the translog and flush/update processes that make your updates durable and/or searchable. Updates go to the data node, which puts the update in the translog. OpenSearch then eventually performs a refresh, which syncs the updates to Lucene memory, and a flush, which fsyncs the changes to disk.
Finally, I took a look at the core of OpenSearch’s search functionality, Apache Lucene, and covered some of the things that OpenSearch adds to it, such as scalability and platform features.
In the next part of this series, I’ll wrap up with a look at the state of OpenSearch: what can I, as a community member, contribute to OpenSearch? Where is OpenSearch going, and what could it really use help with?
Ready to play with OpenSearch right away? Start today with your free trial on the NetApp Instaclustr platform!