Introduction
In the previous blog we tried a simple Kafka Streams application for Cluedo. It relied on a KTable to count the number of people in each room. In this blog, we’ll extend this idea and develop a more complex streams application to keep track of the weight of goods in trucks for our Kongo IoT application. Here’s the latest complete Kongo code with the new streams application (OverloadStreams.java).
1. Overload!
 (Source: Illustration 51591027 © Mariayunira | Dreamstime.com)
(Source: Illustration 51591027 © Mariayunira | Dreamstime.com)
Noah has a transportation problem. He has lots of animals of various weights, and only a small boat to transport them from the shore to the Ark. The boat can only transport 8000kg (8.8 US tons) at a time and is initially empty (we’ll ignore Noah’s weight).
| Animal | Weight (kg) |
|---|---|
| elephant | 8000 |
| rhino | 5000 |
| hippo | 4000 |
| giraffe | 2000 |
| bull | 1000 |
| bear | 1000 |
| croc | 1000 |
| lion | 200 |
We’ll use this transport scenario to demonstrate the new Kongo truck overload streams application. In terms of the development and test process, it makes sense to write and test a standalone self-contained Kafka Streams application before eventual integration with other Kafka and non-Kafka components. Here’s a sample of the trace messages you can easily get with Kafka streams print() statements.
Animal weight and boat maximum payload events populate KTables:
[KTABLE-SOURCE-0000000006]: elephant, (8000<-null)
[KTABLE-SOURCE-0000000006]: rhino, (5000<-null)
[KTABLE-SOURCE-0000000006]: hippo, (4000<-null)
[KTABLE-SOURCE-0000000006]: giraffe, (2000<-null)
[KTABLE-SOURCE-0000000006]: bull, (1000<-null)
[KTABLE-SOURCE-0000000006]: bear, (1000<-null)
[KTABLE-SOURCE-0000000006]: croc, (1000<-null)
[KTABLE-SOURCE-0000000006]: lion, (200<-null)
Boat maximum payload:
[KTABLE-SOURCE-0000000014]: boat, (8000<-null)
As animals are loaded and unloaded the total weight of animals on the boat is tracked and overload warnings produced:
Noah enthusiastically loads both the elephant and the rhino onto the boat:
[KSTREAM-SOURCE-0000000000]: elephant, boat
[KSTREAM-LEFTJOIN-0000000020]: boat, 8000
The elephant weighs 8000kg so the boat has an 8000kg load:
[KTABLE-SOURCE-0000000010]: boat, (8000<-null)
[KSTREAM-SOURCE-0000000000]: rhino, boat
The rhino weighs 5000kg plus the 8000kg elephant results in a 13000kg load:
[KSTREAM-LEFTJOIN-0000000020]: boat, 13000
[KTABLE-SOURCE-0000000010]: boat, (13000<-null)
This is too heavy!
[KSTREAM-FILTER-0000000023]: boat, overloaded! 13000 > 8000
Noah unloads the rhino, the elephant remains on the boat:
[KSTREAM-SOURCE-0000000001]: rhino, boat
[KSTREAM-LEFTJOIN-0000000030]: boat, 8000
[KTABLE-SOURCE-0000000010]: boat, (8000<-null)
The boat is no longer overloaded, so Noah can transport the elephant over to the Ark, then make further trips with the giraffe, bull and rhino, and then the hippo, bear, croc, and lion.
For testing, I used the Kafka console producer to generate the input records but discovered that the default String Serializer can’t be overridden with a Long Serializer, so a workaround is to use String types for values (with conversion to Longs in the streams code).
2. Kongo Truck Overload Streams Application
 (Source: Shutterstock)
(Source: Shutterstock)
The goal for this blog was to build a Kafka streams application that I could easily integrate with the existing Kongo code, and which would add some relevant functionality. Inspired by the Cluedo example, I picked truck overloading to implement. In order to keep track of the weight of goods on each truck and produce a warning message if the weight goes over the limit, we need to know (1) the weight of each good, (2) the maximum allowed payload for each truck, (3) the current weight of goods on each truck, and (4) when goods are loaded or unloaded from/to each truck.
We use KTables to keep track of 1-3, and a combination of DSL operations including join and leftjoin (for Ktable lookups to find the weight of incoming goods, current weight of goods on a truck, and maximum payload for a truck), and map and filter etc. to juggle and change keys/values (which is the tricky bit in practice).
The existing combined rfid event topic is used as input, but because we previously combined load and unload events on the one topic to ensure event order, for simplicity of streams processing we immediately split it into separate load and unload event streams (I’m also currently unsure if there is an elegant way of keeping track of event “types” for later content-based decisions in a streams processor). Here’s the essence of the streams code (complete code in OverloadStreams.java):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 |
Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "kongo-stream-" + version); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Note: As default Serdes are <String, String> need to specify if different in DSL operations. config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); // Disable record cache for debugging if (!cacheOn) config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); // Create Streams SerDes from existing Serializer. final Serializer <RFIDEvent> rfidStreamSerializer = new RFIDEventSerializer(); final Deserializer <RFIDEvent> rfidStreamDeserializer = new RFIDEventSerializer(); final Serde <RFIDEvent> rfidStreamSerde = Serdes.serdeFrom(rfidStreamSerializer, rfidStreamDeserializer); StreamsBuilder builder = new StreamsBuilder(); // Unified RFID event stream <String, RFIDEvent> // Must specify the Serdes here as different to defaults. // This will be split into separate load/unload streams KStream<String, RFIDEvent> rfidStream = builder .stream(rfidTopic, Consumed.with( Serdes.String(), /* key serde */ rfidStreamSerde /* value serde * ) ); // goodsWeightTable: <goods, weight> <String, Long> // actual weight of each Goods in Kg // must be initialized initially from goodsWeightTopic KTable<String, Long> goodsWeightTable = builder.table(goodsWeightTopic, Consumed.with(Serdes.String(), Serdes.Long())); // trucksMaxWeightTable: <truck, maxWeight> <String, Long> // maximum payload in Kg that each truck can carry // must be initialized initially from trucksMaxWeightTopic KTable<String, Long> trucksMaxWeightTable = builder.table(trucksMaxWeightTopic, Consumed.with(Serdes.String(), Serdes.Long())); // trucksWeightTable: <truck, weight> <String, Long> // actual weight of goods loaded on each truck // changes as goods loaded and unloaded // If truck entry doesn't exist it's created automatically. KTable<String, Long> trucksWeightTable = builder.table(trucksWeightTopic, Consumed.with(Serdes.String(), Serdes.Long())); // (A) rfidLoadStream: <goods, truck> load events // Split RFID event stream into load and unload events // Two cases, one for load, one for unload KStream<String, String> rfidLoadStream = // <key, rfidEvent> rfidStream // if rfidEvent.load is true then a load event .filter((key, rfidEvent) -> (rfidEvent.load)) // change key/value to <goodsId, truckId> .map((key, rfidEvent) -> KeyValue.pair(rfidEvent.goodsKey, rfidEvent.truckKey)); // (B) rfidUnLoadStream: <goods, truck> unload events KStream<String, String> rfidUnLoadStream = // <key, rfidEvent> rfidStream // if rfidEvent.load is false then unload event .filter((key, rfidEvent) -> (!rfidEvent.load)) // change key/value to <goodsId, truckId> .map((key, rfidEvent) -> KeyValue.pair(rfidEvent.goodsKey, rfidEvent.truckKey)); // trucksWeightStream: <truck, weight> // stream with updated (increased) truck weight // resulting from load events KStream<String, Long> trucksWeightStream = // <goods, truck> rfidLoadStream // <goods, truck> join <goods, weight> -> <goods, (truck, weight)> .join(goodsWeightTable, (truck, weight) -> new ReturnObjectSL(truck, weight), Joined.with( Serdes.String(), // key Serdes.String(), // left value Serdes.Long()) // right value ) // rekey/value // <goods, (truck, weight) -> <truck, weight> .map((goods, returnObject) -> KeyValue.pair(returnObject.s, returnObject.v)) // <truck, weight> leftJoin <truck, oldWeight> -> <truck, weight+oldWeight> // compute new weight for truck, if no existing truck // weight assume new weight is just weight of goods .leftJoin(trucksWeightTable, (goodsWeight, oldWeight) -> oldWeight == null ? goodsWeight : goodsWeight + oldWeight, Joined.with( Serdes.String(), // key Serdes.Long(), // left value Serdes.Long()) // right value ); // update state of trucks weight KTable (via trucksWeightTopic) trucksWeightStream.to(trucksWeightTopic, Produced.with(Serdes.String(), Serdes.Long())); // check new truck weight against truck maxweight // if overloaded produce violation warning KStream<String, String> overloadWarningStream = // <truck, weight> trucksWeightStream // <truck, weight> join <truck, maxWeight> .join(trucksMaxWeightTable, (weight, max) -> weight > max ? "overloaded! " + weight + " > " + max : "", Joined.with( Serdes.String(), // key Serdes.Long(), // left value Serdes.Long()) // right value ) .filter((key, value) -> (value.length() >= 1)); // send to warnings topic overloadWarningStream.to("kongo-overload-warnings"); // stream with updated (decreased) truck weight // resulting from unload events KStream<String, Long> trucksWeightStream2 = // <goods, truck> rfidUnLoadStream // <goods, truck> + <goods, weight> -> <goods, (truck, weight)> .join(goodsWeightTable, (truck, weight) -> new ReturnObjectSL(truck, weight), Joined.with( Serdes.String(), // key Serdes.String(), // left value Serdes.Long()) // right value ) // rekey/value // <goods, (truck, weight) -> <truck, weight> .map((goods, returnObject) -> KeyValue.pair(returnObject.s, returnObject.v)) // <truck, weight> leftJoin <truck, oldWeight> -> <truck, oldWeight-weight> // compute new weight for truck .leftJoin(trucksWeightTable, (goodsWeight, oldWeight) -> oldWeight == null ? 0 : oldWeight - goodsWeight, Joined.with( Serdes.String(), // key Serdes.Long(), // left value Serdes.Long()) // right value ); // update state of trucks weight KTable (via trucksWeightTopic) trucksWeightStream2.to(trucksWeightTopic, Produced.with(Serdes.String(), Serdes.Long())); // build topology and start processing final Topology top = builder.build(); KafkaStreams streams = new KafkaStreams(builder.build(), config); System.out.println(top.describe()); // cleanUp() recreates the state from the topic streams.cleanUp(); streams.start(); // run the Kongo application streams.close(); |
Note the use of a “dummy” java object ReturnObjectSL (with String and Long arguments) to keep track of the values from a join for use in the next DSL operator.
Because Lambda expressions are used in the DSLs, the argument variable names can be anything meaningful that you like (argument types are inferred from the context).
I managed to use the built-in SerDes for String and Long types for most of the code. However, the Kongo code has a custom class that we need to use, RFIDEvent. I wondered if we needed to write a SerDes for this? The documentation says that there are three options for creating SerDes:
- Write a serializer for your data type T by implementing org.apache.kafka.common.serialization.Serializer.
- Write a deserializer for T by implementing org.apache.kafka.common.serialization.Deserializer.
- Write a serde for T by implementing
- org.apache.kafka.common.serialization.Serde, which you either do manually (see existing SerDes in the previous section) or
- by leveraging helper functions in Serdes such as Serdes.serdeFrom(Serializer<T>, Deserializer<T>).
3b. meant that it was trivial to reuse the existing Kafka (De-)Serializers for RFIDEvent (RFIDEventSerializer which implemented both Serializer and Deserializer) to create a SerDes like this :
|
1 2 3 4 |
final Serializer <RFIDEvent> rfidStreamSerializer = new RFIDEventSerializer(); final Deserializer <RFIDEvent> rfidStreamDeserializer = new RFIDEventSerializer(); final Serde <RFIDEvent> rfidStreamSerde = Serdes.serdeFrom(rfidStreamSerializer, rfidStreamDeserializer); |
For completeness I’ve updated our previous Kafka data conversion diagram to show this creation path for Streams SerDes: SerDes can be created from existing Kafka (De-)serializers.
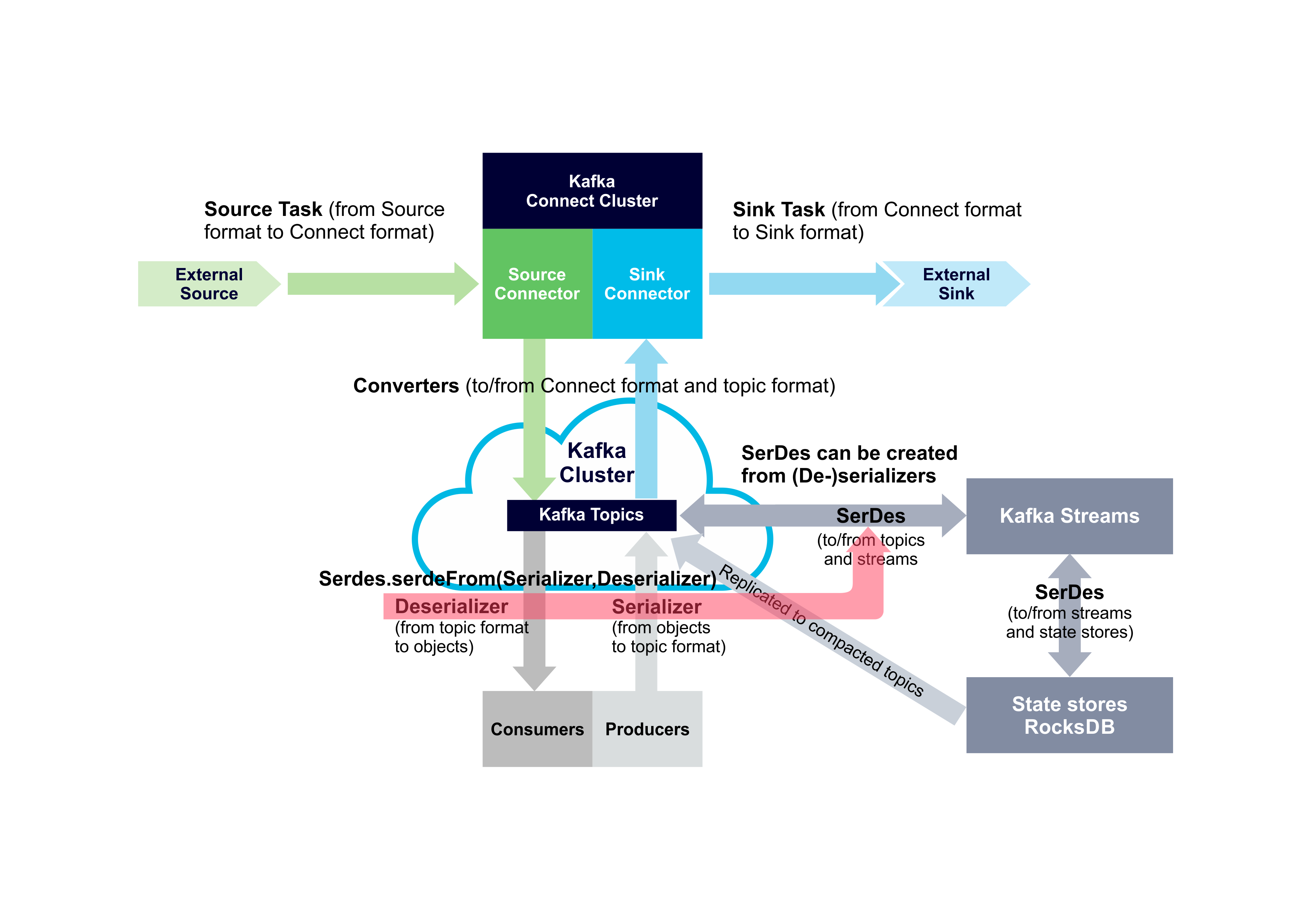 SerDes can be created from existing Kafka (De-)serializers.
SerDes can be created from existing Kafka (De-)serializers.
Here’s some alternative code (replacing (A) and (B) above) using branch (split) to produce the rfidLoadStream and rfidUnLoadStream. Branch works like a case/switch statement and produces as many output streams as there are cases, as an array of streams with the same key/values as the input stream.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// Alternative using a branch. // Note that we can't do a map at end of this as branch is terminal // so have to return RFIDEvent and rekey/value later // Note that branch returns an array of streams: // [0] has load events, [1] has unload events. KStream<String, RFIDEvent>[] rfidbranches = // <String, RFIDEvent> rfidStream .branch( (key, rfidEvent) -> rfidEvent.load, (key, rfidEvent) -> !rfidEvent.load ); // Produce <goods, truck> load and unload streams KStream<String, String> rfidLoadStream = rfidbranches[0] .map((key, rfidEvent) -> KeyValue.pair(rfidEvent.goodsKey, rfidEvent.truckKey) ); KStream<String, String> rfidUnLoadStream = rfidbranches[1] .map((key, rfidEvent) -> KeyValue.pair(rfidEvent.goodsKey, rfidEvent.truckKey) ); |
To integrate the new Streams code with the existing Kongo code the following minor changes were made:
- Three new topics were created:
- Kongo-goods-weight
- <goods, weight>, the weight of each Goods in the system
- output from Kongo, input to streams for KTable
- Kongo-trucks-maxweight
- <truck, maxWeight>, the maximum payload that a truck can transport
- output from Kongo, input to streams for KTable
- Kongo-trucks-weight
- <trucks, weight>, the dynamically changing weight of Goods on each truck
- input and output from streams
- Kongo-goods-weight
- During the simulation world creation phase:
- After Goods are created <goods, weight> records are sent to the new topic Kongo-goods-weight using a new producer.
- After creating Trucks a random maximum (up to 150 tonnes) payload weight for each truck is computed and a stream of <truck, maxWeight> records are sent to the new topic kongo-trucks-maxweight using a new producer.
The new version of Kongo including the complete streams code is available here.
3. Topology Exceptions!
 M.C. Escher’s impossible waterfall, maybe not so impossible in this video?!
M.C. Escher’s impossible waterfall, maybe not so impossible in this video?!
What can go wrong with Topologies? Are some topologies impossible? Can you have a cycle in a DAG During development of the streams code I came across (1) an example of a Topology Exception, and (2) a case which perhaps should have been (but wasn’t). To help understand what’s going on (the inputs, outputs, and processing steps) for a Kafka streams application, you can print out the Topology using just the few lines of code:
final Topology top = builder.build(); System.out.println(top.describe());
The Topology for our streams application is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 |
Sub-topologies: Sub-topology: 0 Source: KSTREAM-SOURCE-0000000000 (topics: [kongo-rfid-8]) --> KSTREAM-FILTER-0000000010, KSTREAM-FILTER-0000000012 Processor: KSTREAM-FILTER-0000000010 (stores: []) --> KSTREAM-MAP-0000000011 <-- KSTREAM-SOURCE-0000000000 Processor: KSTREAM-FILTER-0000000012 (stores: []) --> KSTREAM-MAP-0000000013 <-- KSTREAM-SOURCE-0000000000 Processor: KSTREAM-MAP-0000000011 (stores: []) --> KSTREAM-FILTER-0000000015 <-- KSTREAM-FILTER-0000000010 Processor: KSTREAM-MAP-0000000013 (stores: []) --> KSTREAM-FILTER-0000000028 <-- KSTREAM-FILTER-0000000012 Processor: KSTREAM-FILTER-0000000015 (stores: []) --> KSTREAM-SINK-0000000014 <-- KSTREAM-MAP-0000000011 Processor: KSTREAM-FILTER-0000000028 (stores: []) --> KSTREAM-SINK-0000000027 <-- KSTREAM-MAP-0000000013 Sink: KSTREAM-SINK-0000000014 (topic: KSTREAM-MAP-0000000011-repartition) <-- KSTREAM-FILTER-0000000015 Sink: KSTREAM-SINK-0000000027 (topic: KSTREAM-MAP-0000000013-repartition) <-- KSTREAM-FILTER-0000000028 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000016 (topics: [KSTREAM-MAP-0000000011-repartition]) --> KSTREAM-JOIN-0000000017 Source: KSTREAM-SOURCE-0000000029 (topics: [KSTREAM-MAP-0000000013-repartition]) --> KSTREAM-JOIN-0000000030 Processor: KSTREAM-JOIN-0000000017 (stores: [kongo-goods-weight-8STATE-STORE-0000000001]) --> KSTREAM-MAP-0000000018 <-- KSTREAM-SOURCE-0000000016 Processor: KSTREAM-JOIN-0000000030 (stores: [kongo-goods-weight-8STATE-STORE-0000000001]) --> KSTREAM-MAP-0000000031 <-- KSTREAM-SOURCE-0000000029 Processor: KSTREAM-MAP-0000000018 (stores: []) --> KSTREAM-FILTER-0000000020 <-- KSTREAM-JOIN-0000000017 Processor: KSTREAM-MAP-0000000031 (stores: []) --> KSTREAM-FILTER-0000000033 <-- KSTREAM-JOIN-0000000030 Processor: KSTREAM-FILTER-0000000020 (stores: []) --> KSTREAM-SINK-0000000019 <-- KSTREAM-MAP-0000000018 Processor: KSTREAM-FILTER-0000000033 (stores: []) --> KSTREAM-SINK-0000000032 <-- KSTREAM-MAP-0000000031 Source: KSTREAM-SOURCE-0000000002 (topics: [kongo-goods-weight-8]) --> KTABLE-SOURCE-0000000003 Sink: KSTREAM-SINK-0000000019 (topic: KSTREAM-MAP-0000000018-repartition) <-- KSTREAM-FILTER-0000000020 Sink: KSTREAM-SINK-0000000032 (topic: KSTREAM-MAP-0000000031-repartition) <-- KSTREAM-FILTER-0000000033 Processor: KTABLE-SOURCE-0000000003 (stores: [kongo-goods-weight-8STATE-STORE-0000000001]) --> none <-- KSTREAM-SOURCE-0000000002 Sub-topology: 2 Source: KSTREAM-SOURCE-0000000021 (topics: [KSTREAM-MAP-0000000018-repartition]) --> KSTREAM-LEFTJOIN-0000000022 Processor: KSTREAM-LEFTJOIN-0000000022 (stores: [kongo-trucks-weight-8STATE-STORE-0000000007]) --> KSTREAM-JOIN-0000000024, KSTREAM-SINK-0000000023 <-- KSTREAM-SOURCE-0000000021 Processor: KSTREAM-JOIN-0000000024 (stores: [kongo-trucks-maxweight-8STATE-STORE-0000000004]) --> KSTREAM-FILTER-0000000025 <-- KSTREAM-LEFTJOIN-0000000022 Source: KSTREAM-SOURCE-0000000034 (topics: [KSTREAM-MAP-0000000031-repartition]) --> KSTREAM-LEFTJOIN-0000000035 Processor: KSTREAM-FILTER-0000000025 (stores: []) --> KSTREAM-SINK-0000000026 <-- KSTREAM-JOIN-0000000024 Processor: KSTREAM-LEFTJOIN-0000000035 (stores: [kongo-trucks-weight-8STATE-STORE-0000000007]) --> KSTREAM-SINK-0000000036 <-- KSTREAM-SOURCE-0000000034 Source: KSTREAM-SOURCE-0000000005 (topics: [kongo-trucks-maxweight-8]) --> KTABLE-SOURCE-0000000006 Source: KSTREAM-SOURCE-0000000008 (topics: [kongo-trucks-weight-8]) --> KTABLE-SOURCE-0000000009 Sink: KSTREAM-SINK-0000000023 (topic: kongo-trucks-weight-8) <-- KSTREAM-LEFTJOIN-0000000022 Sink: KSTREAM-SINK-0000000026 (topic: kongo-overload-warnings) <-- KSTREAM-FILTER-0000000025 Sink: KSTREAM-SINK-0000000036 (topic: kongo-trucks-weight-8) <-- KSTREAM-LEFTJOIN-0000000035 Processor: KTABLE-SOURCE-0000000006 (stores: [kongo-trucks-maxweight-8STATE-STORE-0000000004]) --> none <-- KSTREAM-SOURCE-0000000005 Processor: KTABLE-SOURCE-0000000009 (stores: [kongo-trucks-weight-8STATE-STORE-0000000007]) --> none <-- KSTREAM-SOURCE-0000000008 |
Note that the sub-topologies result from key repartitioning making it slightly tricky to work out the exact correspondence to the code (i.e. some of the processors are split by repartitioning into different sub-topologies). A nicer visualization is available using this handy online Kafka Streams Topology Visualizer. Just copy the above ascii topology into the tool and you get this:
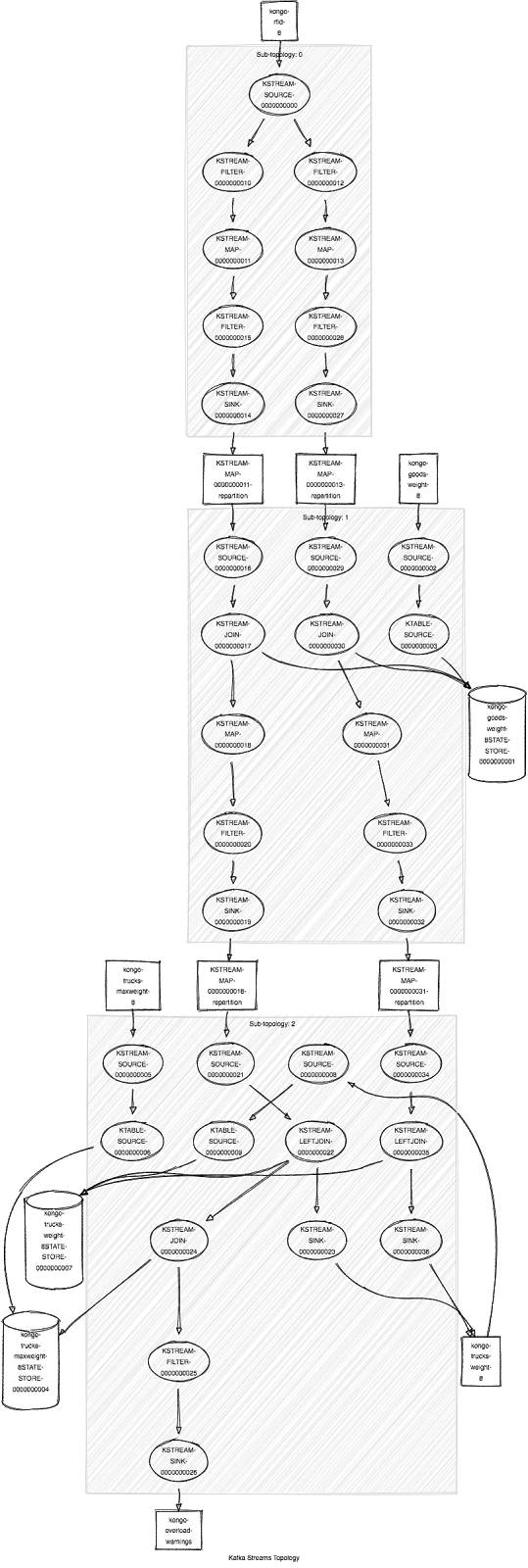
This Topology worked. However, during debugging and testing I produced a “TopologyException: Invalid topology!” error:
Exception in thread "main" org.apache.kafka.streams.errors.TopologyException: Invalid topology: Topic KSTREAM-MAP-0000000011-repartition has already been registered by another source.
After a few moments of existential panic worrying that I had been turned into a Klein bottle or some other impossible topological oddity (at least in our limited 3d world), I found that it was just a simple copy/paste error and it was trying to read from the same stream as another processor. See the red arrow:
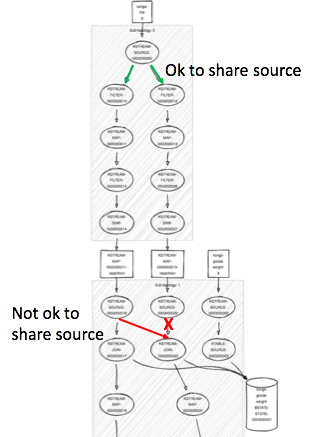
However, I noticed that source was also shared earlier in the code (green arrows above), so I wondered why it complains here? One theory is that it’s ok to share a source that comes directly from a topic, otherwise not. Another is that it’s not ok to share a source that is the result of a repartition. Some further experiments may be in order to come up with some “Kafka streams topology rules”, and maybe even a unified theory of Kafka streams topologies.
The Kafka Streams documentation says that the topology is a DAG, so in theory it’s not supposed to have cycles (A=acyclic). But looking closely at this topology there’s something that looks suspiciously like a cycle (orange arrows):
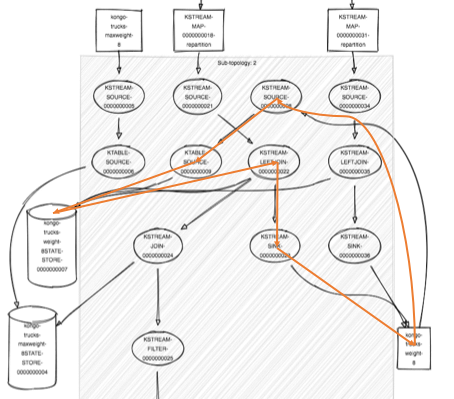
However, there’s no topology exception and it works. The loop results from transforming the trucks weight topic to a KStream and then a KTable. The goods weight and trucks weight is then combined to produce the new truck weight value which is sent to the trucks weight topic (where we started from). A cycle! Why does this work? I suspect that because it’s not a “simple” loop, with the same event consumed as produced, that it’s ok, i.e. there are transformations and a state store in between the input the output. Cycles in streams are discussed in the context of other streaming technologies, and could be useful to clarify for Kafka streams as well.
4. Does It Work? Transactional Magic Pixie Dust
The new trucks overload streams application worked with the real Kongo simulation data. However, I did notice that (as I had suspected) the truck weights sometimes went negative. I had intentionally not enforced a minimum weight of zero in the streams code to see if this happened. There are potentially four things happening here.
- Maybe the order of events within streams applications isn’t guaranteed. I.e. it’s possible for say multiple unload events to be processed in a row resulting in a truck weight going negative, before the load events are processed taking the weight back up to positive again.
- Kafka event order is only guaranteed within partitions. How does this work out in practice for streams where multiple topics (with potentially different keys and therefore partitions) are inputs, and where repartitioning happens within the streams application? Related to this is how does Topology scaling work? This is briefly covered in the book: Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale, “Scaling the Topology” page 312ff.
- KTable is cached for 30s by default (the default commit_interval), this could result in stale values being read.
- Kafka Streams aren’t transactional by default. Ideally from when the current value of a truck weight is read from the KTable in one thread, until when the same thread updates the value, we don’t want another thread to be able to change the value (or using optimistic concurrency, if it is changed we want to throw an exception).
Since Kafka 0.11 there is support for transactions using a new Transactional API, and this link explains the motivation from a streams perspective:
The transactional producer allows an application to send messages to multiple partitions (and topics!) atomically.
The best explanation I’ve found of Kafka transactions so far is in this book (ebook available, Chapter 12: Transactions, but Not as We Know Them), which says that if you enable transactions in Kafka Streams then you get atomic operations for free.
How do you turn transactions on for a streams application? There’s a single configuration parameter for delivery semantics and transactions. If the property processing.guarantee is set to “exactly_once” you get transactions (default is at_least_once). In the streams code you set the StreamsConfig processing guarantee like this:
Properties config = new Properties();
config.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, "exactly_once");
This change successfully prevented truck weights from going negative (although it also changes the commit_interval to 100ms making it less likely to get stale data from the KTable cache). There may also be a small performance hit.
Further Resources
The web tool for visualizing Kafka Streams topologies is here. Note that the direction of the arrows is ambiguous for state stores. It would also be nice to have type information for keys/value on the diagram, and the ability to have a simplified or detailed view.