Why Use PGVector?
We’ve all been in this position before: trying to quickly solve a technical problem just to end up spending hours browsing through endless documentation in the hope of finding a solution. With all that time going to waste, there has to be a better way to search documentation.
And now, there is.
Instaclustr has recently introduced the PGVector extension to our PostgreSQL Managed Service, enabling users to quickly and easily search text data without the need for a specialized database to store your embeddings—a major development in the realm of textual data.
Embeddings are a mathematical representation of how related or similar words are. For example, the words “tree” and “bush” would be more closely related than say, “tree” and “automobile.” Embeddings are generally stored as vectors, which are essentially a list of numbers.
PGVector is an extension that provides the ability to search for vectors that are more closely related to each other. With embeddings and vector search, you can then search for text that semantically means the same thing—an incredibly useful tool, especially when building Large Language Models (LLMs).
When PGVector comes into play, PostgreSQL turns into a highly performant vector store capable of performing distance-based search operations on embeddings. This now makes it possible to sift through vast amounts of textual data in a seamless way.
With PGVector, PostgreSQL can conduct exact nearest neighbor search and approximate nearest neighbor search using L2 (or Euclidian) distance, inner product, and cosine distance. OpenAI particularly recommends the cosine distance for its efficiency in capturing semantic similarities.
The Role of Embeddings in Retrieval Augmented Generation (RAG) and LLMs
One of the more fascinating applications of embeddings is their role in the Retrieval Augmented Generation (RAG) process.
In this technique, relevant information is retrieved from an external source, transformed in a way that makes it digestible by an LLM, and subsequently fed into the LLM for generated text output. This allows the LLM to be fine-tuned in knowledge it wasn’t originally trained on.
Take, for example, your company’s documentation as source: from here you can generate embeddings and store them in PostgreSQL. Now, when a user queries the documentation, the numerical representation of the user’s query can be computed, and the relevant pieces of the documentation are identified and retrieved from the database by performing a similarity search on the embeddings. The retrieved documentation gets passed together with the user’s query to the LLM, which provides us with an accurate answer as well as the relevant pieces of the documentation and its sources.
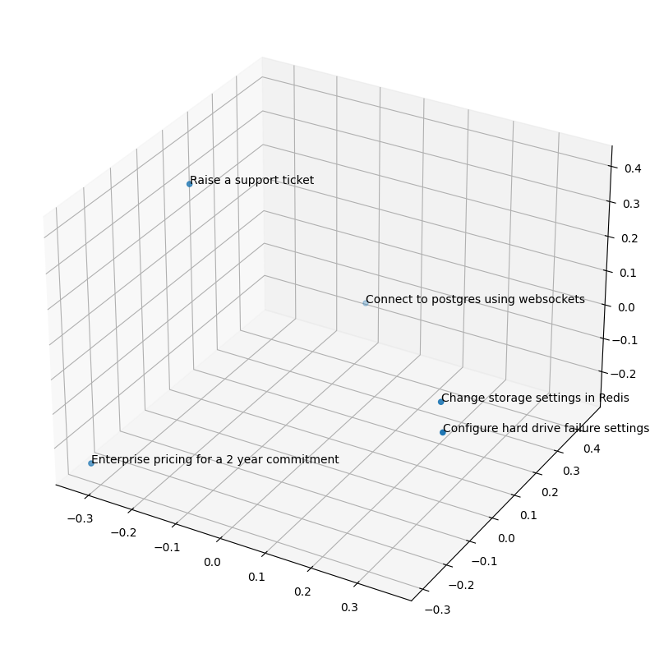
Let’s imagine that someone is searching Instaclustr documentation with a couple of phrases:
- “Configure hard drive failure setting in Apache Cassandra”
- “Change storage settings in Redis”
- “Enterprise pricing for a 2-year commitment”
- “Raise a support ticket”
- “Connect to PostgreSQL using websockets”
When you plot the embeddings of the above phrases, the first 2 are going to be closer than the rest due to the semantic meaning of each sentence (changing how these databases work with storage), despite not sharing any of the same keywords:
However, one challenge remains: the ‘context window’ of every LLM.
This window refers to the number of tokens an LLM can process at once. Models with a limited context window tend to falter with larger inputs. On the flip side, models trained with large context windows (e.g., 100,000 tokens—enough to provide an entire book as part of your prompt) will see an increase in latency of a response and require storing the entire context, weights, k/v store, etc., in memory of the GPU running the model.
This means we have an incentive to keep the context window as small as possible to generate useful answers. With embeddings, we can perform simple distance searches on our text and use this to only pull the relevant pieces of data to provide to the LLM. This ensures we harness the full potential of the LLM without overwhelming it.
But the model used for generating the embeddings (OpenAI’s text-embedding-ada-002) also has a context window. Therefore, it’s imperative to dissect our extensive documentation into more digestible ‘chunks’ before feeding it to the embedding model.
Embeddings in Action: The Magic of LangChain
So how do we do this? A Python framework called LangChain comes in handy.
Let’s look at what we would need to do to have an LLM answer questions about Instaclustr’s documentation:
Document Loading: Scrape the Instaclustr documentation pages by leveraging a Document Loader: LangChain facilitates the loading of diverse document formats from a range of locations—in our case we utilize the HTML loader.
Document Transformation: This is pivotal for fetching pertinent document sections, which involves the segmentation of large documents into smaller chunks.
Embedding Generation: In this step we calculate the embeddings on the chunked documentation using OpenAI’s embedding model.
Data storing: Store both the embeddings and the original content within PostgreSQL.
Great! We now have a semantic index of Instaclustr’s documentation. Next, let’s glance at the user query or prompt workflow:
Step 1: A user submits a question: “How do I create a Redis cluster using Terraform?”
Step 2: We calculate the embeddings of the question using OpenAI’s embeddings API.
Step 3: We query our semantic index sitting in PostgreSQL using cosine similarity asking for the original content that is closest to the embedding of the user’s question.
Step 4: We grab the original content returned in the vector search, concatenate that together, and include it in a specially crafted prompt with the user’s original question.
Simple right? Let’s do it!
Implementation Guidance and User Interaction
First, let’s enable the PGVector extension in our PostgreSQL database and set up a table for storing all our documents along with their embeddings:
|
1 2 3 4 5 |
CREATE EXTENSION vector; CREATE TABLE insta_documentation (id bigserial PRIMARY KEY, title, content, url, embedding vector(3)); |
Let’s now write some Python code to scrape the Instaclustr documentation page, extract the main text parts like title and content using Beautiful Soup and store them together with the URL in our PostgreSQL table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
urls = [...] def init_connection(): return psycopg2.connect(**st.secrets["postgres"]) def extract_info(url): hdr = {'User-Agent': 'Mozilla/5.0'} req = Request(url,headers=hdr) response = urlopen(req) soup = BeautifulSoup(response, 'html.parser') title = soup.find('title').text middle_section = soup.find('div', class_='documentation-middle').contents # middle section consists of header, content and instaclustr banner and back and forth links - we want only the first two content = str(middle_section[0]) + str(middle_section[1]) return title, content, url conn = init_connection() cursor = conn.cursor() for url in urls: page_content = extract_info(url) postgres_insert_query = """ INSERT INTO insta_documentation (title, content, url) VALUES (%s, %s, %s)""" cursor.execute(postgres_insert_query, page_content) conn.commit() if conn: cursor.close() conn.close() |
Next, it’s time to load the documentation pages from the database, split them up into chunks and create the pivotal embeddings, and then store those embeddings in the database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
def init_connection(): return psycopg2.connect(**st.secrets["postgres"]) conn = init_connection() cursor = conn.cursor() # Define and execute query to the insta_documentation table, limiting to 10 results for testing (creating embeddings through the OpenAI API can get costly when dealing with a huge amount of data) postgres_query = """ SELECT title, content, url FROM insta_documentation LIMIT 10""" cursor.execute(postgres_query) results = cursor.fetchall() conn.commit() # Load results into pandas DataFrame for easier manipulation df = pd.DataFrame(results, columns=['title', 'content', 'url']) # Break down content text which exceed max input token limit into smaller chunk documents # Define text splitter html_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.HTML, chunk_size=1000, chunk_overlap=100) # We need to initialize our embeddings model embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") docs = [] for i in range(len(df.index)): # Create document with metadata for each content chunk docs = docs + html_splitter.create_documents([df['content'][i]], metadatas=[{"title": df['title'][i], "url": df['url'][i]}]) # Create pgvector dataset db = PGVector.from_documents( embedding=embeddings, documents=docs, collection_name=COLLECTION_NAME, connection_string=CONNECTION_STRING, distance_strategy=DistanceStrategy.COSINE, ) |
And finally, watch in awe as the retriever springs into action, pinpointing the right pieces every time a query is dropped:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
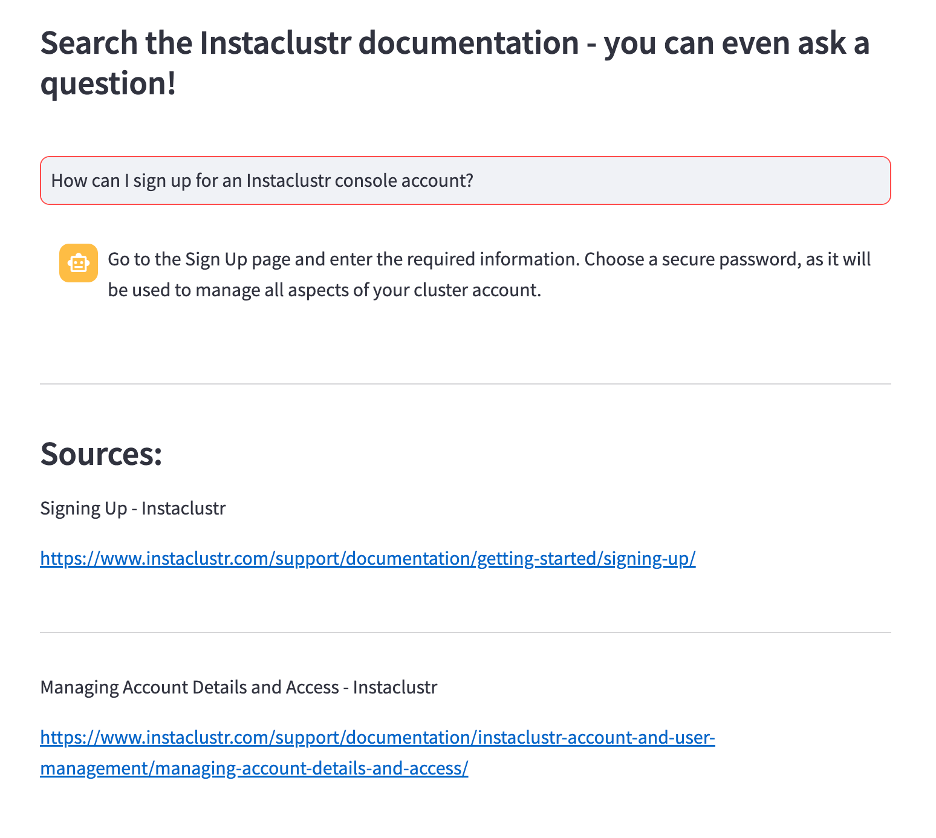
query = st.text_input('Your question', placeholder='How can I sign up for an Instaclustr console account?') retriever = store.as_retriever(search_kwargs={"k": 3}) qa = RetrievalQA.from_chain_type( llm=OpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True, verbose=True, ) result = qa({"query": query}) source_documents = result["source_documents"] document_page_content = [document.page_content for document in source_documents] document_metadata = [document.metadata for document in source_documents] |
Now, let’s test the system and view a successful query in action. To swiftly bring our concept to life, we utilized Streamlit, a powerful tool for building interactive Python interfaces.
Wrapping It Up: Super-Efficient Data Retrieval
On our tech expedition today, we ventured deep into the realms of embeddings, tapping into the combined power of PostgreSQL and PGVector.
We stored embeddings alongside the original data, allowing us to perform precise and rapid searches even through extensive datasets.
Finally, we streamlined data retrieval through LLMs, allowing users the ability to perform natural language queries while saving them the time of sifting through irrelevant data.
The combined power of PostgreSQL and PGVector is a game-changing transformation for how we can now retrieve data. Storing embeddings alongside the original data allows us to perform precise and rapid searches (even through extensive datasets), and by streamlining data retrieval through LLMs we can give users the ability to perform natural language queries while saving them the time of sifting through irrelevant data.
Here’s to a future where data retrieval is not just smart—but super-efficient!