At NetApp® Instaclustr, we help our customers make the most of open source technologies at scale. When an open source technology proves to be extremely valuable and our customers ask us to include it in our managed platform, we work hard to make it happen – and that’s exactly what we did with ClickHouse®.
ClickHouse is the latest addition to our major managed open source frameworks and databases that help our customers build their advanced data and AI workloads. We launched ClickHouse in preview a couple of weeks ago, and we are working towards a general availability release in the coming months.

Figure 1: Support for open-source technologies from a single vendor
Instaclustr is the first adopter of ClickHouse, and we heavily use our managed platform for internal and engineering purposes. So, when I was asked to learn and test ClickHouse integration within our existing architecture, I jumped at the exciting opportunity.
ClickHouse is certainly not the first solution of its kind, and there are many systems that operate in the Online analytical processing (OLAP) arena.
I have personally used Apache® Druid—time flies in tech, since it feels like ages ago! Druid was amazing for real-time insights, although a bit complex to manage and scale.
I have transitioned to other architectures and frameworks through my career, especially after the new paradigm of the Data Lakehouse emerged. So, with a bit of uncertainty and a touch of scepticism (no arrogance here but just some bias), I embarked on this learning journey. In this blog, I will share what I learned about adopting this new technology.
Disclaimer: This is not a training or how-to blog post, but rather a series of thoughts and general topics about my personal learning experience with ClickHouse. Please refer to the online resources to learn more and embark on your own journey of mastering this amazing piece of technology.
Exploring ClickHouse
ClickHouse is an open source, high-performance, columnar-oriented database management system (DBMS) designed for OLAP of large datasets. So, what makes ClickHouse so unique? Well, it stands out from other OLAP DBMS systems due to several key features:
- Compressed column-oriented storage: ClickHouse stores data in a columnar format, enabling efficient compression and faster queries on large datasets. Additionally, it supports specialized codecs for even more compact data. This makes ClickHouse ideal for real-time data processing and analysis while reducing storage costs.
- Vectorized query execution: ClickHouse stores and processes data in columns, leading to better CPU cache utilization and enabling SIMD instructions. This allows ClickHouse to perform operations on multiple data columns simultaneously, making it incredibly fast and efficient for complex analytical queries and real-time analytics.
- Scalability and distributed architecture: Designed for distribution across multiple nodes, ClickHouse can handle petabytes of data and leverage all available CPU cores and disks, both on a single server and across a cluster.
- Compatibility: ClickHouse integrates well with other systems like Apache Kafka® and Apache Spark™, making it easy to incorporate into existing data pipelines and workflows
What makes ClickHouse so popular?
Using your favorite search engine, you will quickly discover that ClickHouse has been gaining significant traction and a growing number of users over the past decade. This increasing popularity is not just a result of hype but is backed by substantial feature and performance improvements in the OLAP world.
Setting aside the “one versus another” type of articles, which are usually not objective (I think that more options are better, as each system has its intrinsic value and usage) and often lack evidence-based comparisons of usage at scale, there are benchmarks and real-world use cases that prove ClickHouse’s superiority.
Tangible benchmarks demonstrate ClickHouse’s excellence in handling real-time data analytics workloads. These benchmarks showcase its ability to handle large datasets with remarkable speed and efficiency, often outperforming other OLAP systems and Data Warehouses.
However, one aspect often missing in benchmarks and articles is how (easy or hard) to deploy, maintain, and scale ClickHouse in production settings. The quick answer comes from the large-scale adoption of ClickHouse by major companies.
Organizations across various industries have integrated ClickHouse into their data architectures. This is a testament to ClickHouse’s robustness and scalability, making it a trusted solution for complex data analytics needs.
Additionally, it offers features such as scaling horizontally, clustering, distributed query processing, fault tolerance, replication, and data sharding, making it highly relevant in the cloud.
To cite one relevant use case among many, ClickHouse excels in time-series processing and analytics. It adds significant value to monitoring and observability platforms where rapid querying of log and metric data is essential.
Many engineering teams within NetApp use ClickHouse for various similar use cases. Our team leverages ClickHouse for both customer-facing and internal data dashboards, providing near real-time insights into platform behaviour and performance. More about this in the last section.
Assumptions and curiosities for the new adopter
When starting with ClickHouse, it’s crucial not to assume that it operates in the same way as traditional DBMS.
While the SQL syntax used in ClickHouse may appear familiar, there are fundamental differences that set it apart from relational databases. These differences can significantly impact how you design and interact with ClickHouse.
Therefore, approaching ClickHouse with an open mind and a willingness to learn and adapt to its unique features and functionalities is essential.
Understand the nuances
If you are coming from a Data Warehouse background, adapting to ClickHouse involves tweaking a few bits.
However, if your experience, similar to mine, lies in the data lake and Lakehouse paradigm, where data often sits in object storage in specific file format and or a specific table format, you may find it more challenging to grasp some of ClickHouse’s concepts directly and intuitively.
Instead of going into the specifics of how, one example is symptomatic of the situation, partitioning is not “always” a good practice in ClickHouse.
I will highlight 3 points that I humorously refer to as “curiosities” that I found striking (in a good or bad way). Getting more hands-on experience helped me see the value and demystify them.
Curiosity #1: Primary key
A primary key in ClickHouse (the sort order of a table) is quite different from a primary key in traditional relational databases (the term “primary” can be misleading)—it does not define the uniqueness of a row.
Instead, ClickHouse uses a sparse index (an in-memory index) to split data into multiple parts, each grouped by a fixed portion called granules. ClickHouse considers an index for every granule (group of data) rather than every row, which is where the term “sparse index” comes from.
Understanding and utilizing ClickHouse’s keys (primary, partition) and indexes is crucial, not only for query performance but for overall ClickHouse performance. Consider these factors carefully in your ClickHouse schema design.
Curiosity #2: Data mutation
Like me, you may easily take for granted the features you’re used to! Well, ClickHouse is not well-suited for frequent modifications and mutations, and it does not fully support ACID transactions. And you better watch out for your data INSERTS: do them in large batches!
However, it’s important to remember that it was not designed for these purposes. Instead, it excels in scenarios where read-heavy operations and real-time analytics are prioritized.
For scenarios requiring frequent updates, consider integrating ClickHouse with systems better suited for mutable data, using ClickHouse primarily for analytical workloads.
Curiosity #3: Table engine
Like any other database, ClickHouse uses Table Engine to define how data is stored, indexed, and queried. What struck me first was the wide range of engine options to suit various use cases (maybe I was living under a rock!). This feature enables ClickHouse to handle a wide variety of data storage and retrieval scenarios efficiently.
What I found amazing is the external systems integration. Forget about the JDBC and ODBC ONLY; ClickHouse supports S3, Kafka, and even Timeseries, offering incredible versatility, flexibility, and performance optimization.
It’s important to note that choosing the right engine for your use case can significantly improve performance and efficiency. Therefore, it’s worth taking the time to understand the pros and cons of each engine. I strongly recommend spending some time on this.
A glimpse into the added value of ClickHouse in a modern stack: Our internal use of ClickHouse
Ocean for Apache Spark (OfAS) is a fully managed service offered by NetApp Instaclustr. It is built to simplify the deployment and usage of Apache Spark™ on Kubernetes. A key element of this involves improving the Spark user experience. We achieve this by offering enhanced metrics and visualizations for Spark’s workloads (check out more details in this blog).
To create enhanced metrics and visualizations, one crucial element is the aggregation of millions of Spark applications’ memory and CPU usage logs in near real-time. After aggregation, we provide our users with live dashboards and graphs of the memory usage of their Spark drivers and executors through the console. The figure below shows a screenshot of Spark node metrics in the OfAS console:
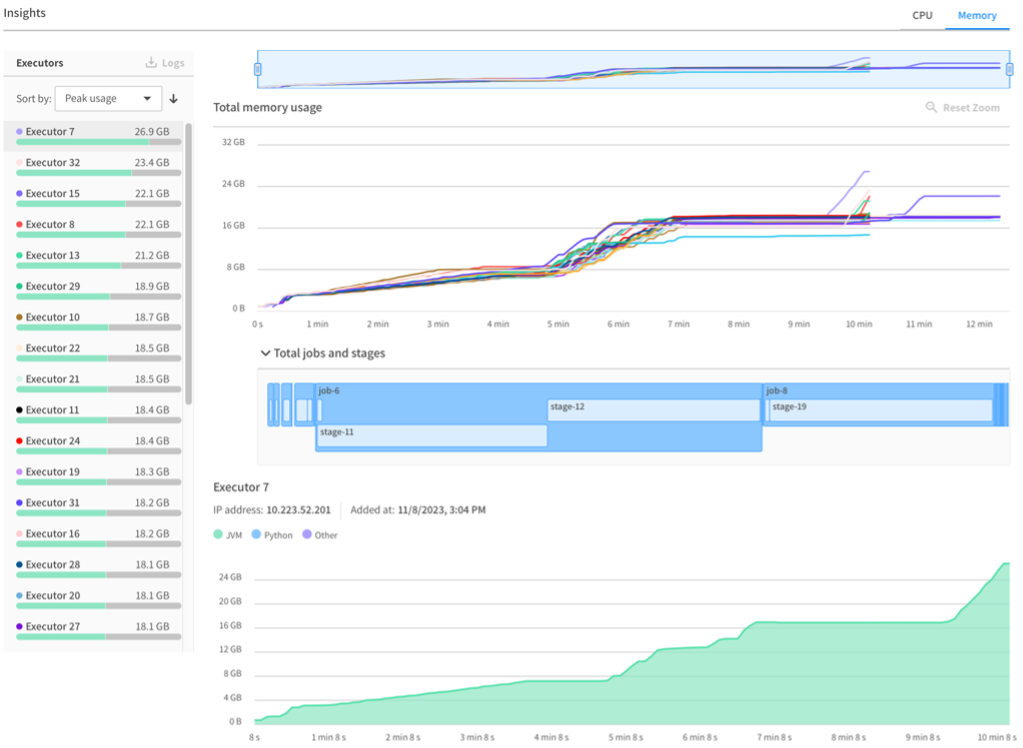
Figure 2: OfAS metric console: Executors Memory Usage Over Time
The metrics described above are directly produced by each Spark application. Spark offers a Monitoring and Instrumentation feature, which, when enabled, allows the driver and each executor to generate metrics at a specified polling frequency.
The challenge was significant: retrieving (millions of) metrics, aggregating them, and displaying memory usage chart for each pod used in a Spark application.
ClickHouse for storage and time series manipulation
After an internal process consisting of benchmarking different solutions and evaluating our options, we ultimately chose ClickHouse.
If you have reached this point in the blog post, you are probably already aware of all its benefits. It may be redundant, but I will still highlight the key differentiating factors that tipped the scale in favor of ClickHouse.
We chose ClickHouse for the following reasons:
- Speed and efficiency for aggregation: ClickHouse is exceptionally fast and efficient for aggregation tasks based on our internal benchmarks.
Low disk storage usage: ClickHouse compression reduce storage requirements without sacrificing efficiency. - SQL-like query language: ClickHouse uses a query language based on SQL, making it accessible and familiar to our Engineering team.
- Powerful aggregation functions: It offers powerful aggregation functions, especially useful for time series queries. I avoided going deeply into this topic, as it deserves its own dedicated blog post. In short, with data points for 81 metrics every 3 seconds, we aggregate them over specific intervals to prevent the pressure of displaying too many data points at once. The graph below illustrates the importance of aggregation when analyzing a single metric over time:
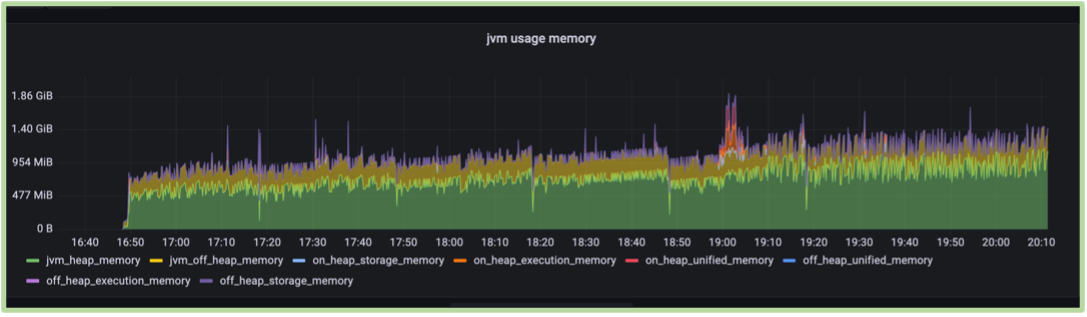
Figure 3: JVM memory usage Timeseries.
The oversimplified architecture diagram below describes the different steps required to process the logs. We are always looking for ways to improve, and of course, it is an evolving approach. Our aim is to reduce processing time to better meet our customers’ needs:
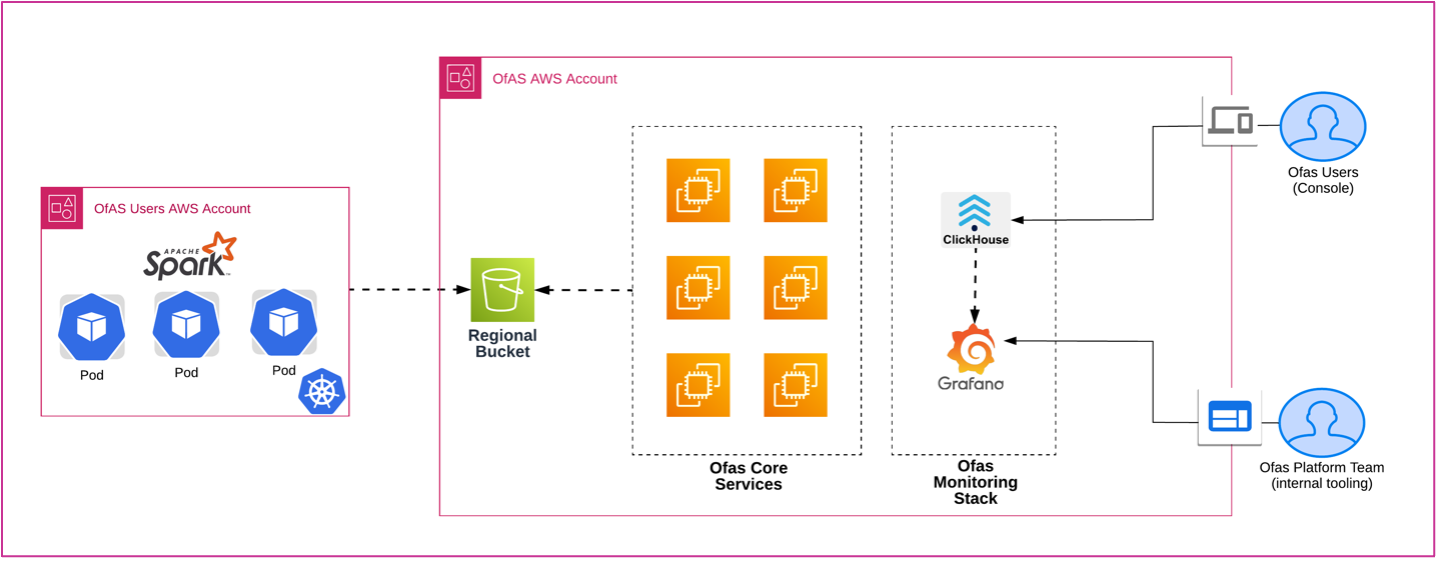
Figure 4: OfAS Spark Application logs processing flow.
Bonus—ClickHouse and Grafana for monitoring
As a bonus, ClickHouse and Grafana dashboards have proven to be very useful. Using Grafana dashboards to visualize data from ClickHouse helped us experiment with and explore options for the Spark metrics explained previously.
Additionally, and somewhat unexpectedly, this combination has enhanced our monitoring capabilities. We can now have near real-time alerts on any degradation occurring at the Spark application level. This allows us to proactively investigate and address the root cause of such situations.
Overall, ClickHouse is an amazing technology with undeniable value. We now fully recognize and appreciate its value for our usage. We are planning to expand its usage for various use-cases and engineering tasks, including customer-facing applications like the memory charts described above and much more.
Summary and where to start
To answer the question posed in the title: “What does it take to learn the internals of ClickHouse?”: it requires intellectual effort to adapt, learn, and progress.
There are plenty of training materials available, but based on my experience, the best approach is to go through the documentation and start with the key concepts. Once the concepts are acquired, you might be wondering how to begin using it yourself.
ClickHouse is an open source project, and you can follow its comprehensive documentation to build (install) and deploy it on your own. Running it locally on your laptop is a good way to start testing.
However, setting up and maintaining a ClickHouse cluster can be quite challenging, like any other open source technology! Ensuring proper data replication and sharding, fault tolerance, and overall stability requires significant time and effort.

Figure 5: Intelligent, open– source, application data infrastructure.
Recognizing these challenges and our customers’ needs and requests, Instaclustr offers a managed service for ClickHouse, currently in a private preview release but with GA expected by the end of 2024. This service will allow you to enjoy the powerful features of ClickHouse without the complexities and headaches of managing the infrastructure yourself.
If you are interested in exploring Instaclustr for ClickHouse and contributing to its evolution, reach out to your Instaclustr Customer Success representative. Alternatively, you can contact us at [email protected] for access. We welcome your interest and look forward to collaborating with you.