In Part 1 of this blog, we introduced Apache Kafka® Tiered Storage and had an initial look at how it works in practice on a public preview version of Instaclustr’s managed Apache Kafka service. In this part, we will have a closer look at Performance, dam the river, and conclude.
Kafka Tiered Storage Performance

Mistaya Canyon – Icefields Parkway in Banff National Park, Canada. (Source: Adobe Stock)
Kafka is known for its high streaming flow rate, so an obvious question is “Does tiered storage impact Kafka’s performance?” Let’s find out.
The Instaclustr Kafka Dev team had already performed extensive performance testing of tiered storage before releasing this new feature, but I was also curious to try it out for myself. Some of my results confirm theirs, but others may require more investigation in order to understand what’s going on further. And your “mileage” may vary!
I spun up a small production-ready Kafka cluster on AWS with tiering enabled (on AWS S3), with 3 brokers (KFK-PRD-r6g.large-250, 3 x 2 = 6 cores) and 3 dedicated KRaft controller nodes (KDR-PRD-m6g.large-80), with RF=3. Once the cluster is running you can check that it’s enabled for tiering under the Details tab on the console, which will show:
Tiered Storage: AWS S3 – Enabled
Currently, we don’t display the S3 bucket details (so you will need to remember which bucket you configured if you want to check what’s happening on the AWS side of things). The console also doesn’t currently display any tiered storage metrics yet (but they are available from our monitoring API).
To generate data and check the basic consumer performance I just used the Kafka CLI tools kafka–producer-perf-test and kafka-consumer-perf-test, all running on a single (but large 36 core) EC2 instance in the same region as the Kafka cluster and S3 bucket.
Testing the tiered storage performance was slightly tricky due to the fact that segments can be either local only, local and remote, or only remote—and it was hard to tell which. After several failed attempts I therefore ended up following this methodology:
- Create a topic with tiering enabled, 6 partitions, and short local.retention.ms time limit.
- Write lots of data until there are at least 10 (1GiB) segments per partition in the S3 bucket.
- Wait for a while (30 minutes or more), checking the disk used metrics on the console until the local segments have been deleted.
- Run the consumer from offset 0 until all the records have been read back from tiered storage and record the metrics.
Here’s an example topic creation with 60s local retention time:
bin/kafka-topics.sh –bootstrap-server IP:9092 –command-config kafka.properties –create –topic test1 –partitions 6 –config remote.storage.enable=true –config local.retention.ms=60000
Here’s an example of the producer creating lots of 100 byte records flat out:
bin/kafka-producer-perf-test.sh —producer.config producer.props –topic test1 –num-records 200000000 –throughput 200000 –record-size 100
And finally, an example of the consumer command:
bin/kafka-consumer-perf-test.sh –bootstrap-server IP:9092 –topic test1 –messages 100000000 —consumer.config consumer.props –group 12345 –print-metrics
Note that the consumer.props contains a setting to read from offset 0 for new consumer groups (auto.offset.reset=earliest), and a new consumer group id needs to be provided each time the command is run to start from 0 again. The consumer is also a lot faster to run than the producer (10’s of seconds not many minutes)!
For comparison, I also created topics that were local only.
Initially, I was spending lots of time creating and writing data to multiple tiered topics in order to repeat tests, as I assumed that if the data had been read back by a consumer once, then the performance would be faster for subsequent reads from the start again (as they would be reading from local segments).
However, I concluded this wasn’t happening in practice, which dramatically sped up my testing process, i.e. reading from tiered storage does not re-create the local segments again.
The following graph shows the comparative throughput using the Kafka consumer performance CLI tool (which I think is just a single consumer/thread, so doesn’t demonstrate the maximum throughput given more partitions and consumers—it’s just designed to show the obvious differences at low consumption rates.
Also, given that the Kafka cluster CPU was very low with a single consumer there is obviously substantial room for more. However, even with a 36-core Kafka client EC2 instance I couldn’t get anywhere near maximum throughput so gave up).

This graph shows the difference between consumer throughput for local only segments, tiered only (no local segments, I ensured they were deleted before the tests were run) for the 1st and 2nd identical runs, and with smaller segment sizes (1MB).
What do we notice? The throughput for local segments is fastest, at 3.2 records/s, and tiered storage is slower (1.2 M records/s)—i.e. local segments are 2.5 times faster than tiered. Small segments have a dramatic impact on throughput! Local segments are 21 times faster than small remote segments.
Finally, the 2nd run reading from tiered storage is no faster than the 1st. I assumed that the results would be cached for immediate reuse, but that apparently doesn’t happen.
(I did read somewhere that the tiered segments are not copied onto local storage so they never become local segments again—they are however copied into local cache for reading by the consumer — but presumably the cache is not long–lived or large enough to contain all the remote segments for long; see this explanation about local caching if you are interested in more information).
If some segments are still local, then the TPS increases—i.e. in practice it will be between the worst remote only tiering TPS and the best local only TPS (orange and blue bars on the graph).
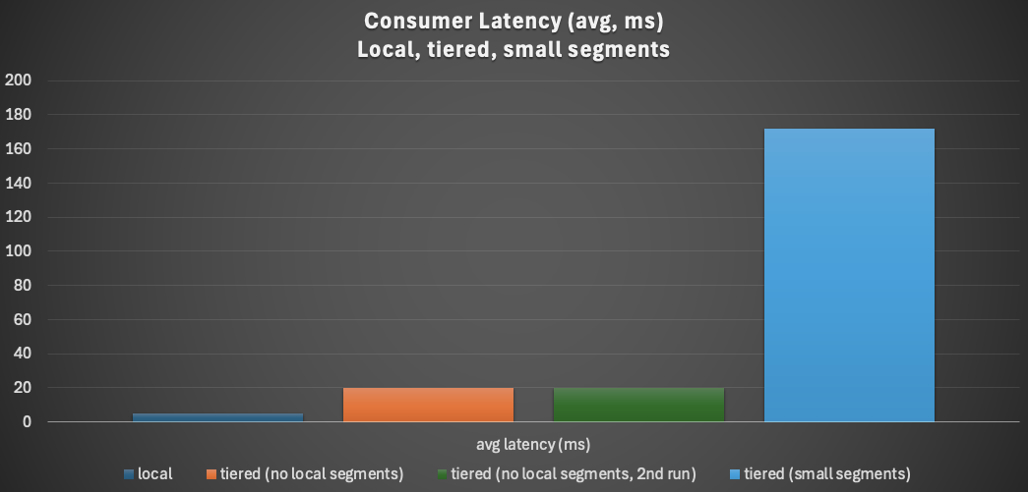
Here’s a graph showing the same story with looking at consumer latencies (average, ms). Consumer latency increases from the shortest for local segments (5ms), tiered storage (19ms), to the longest for small, tiered segments (172ms).
What does this mean in practice?
If you are tempted to reduce the segment size, make sure you do adequate benchmarking to understand the performance impacts of tiered storage for your use case. The performance of consumers reading from (only) tiered storage may be worse than from (only) local storage, however, note that:
- The tiered consumer throughput is considerably faster (x6) than the producer rate (194,000 TPS, for a producer only load using 60% of the cluster CPU—see the last bar on the next graph), and
- Given that lower rate from tiered storage, you may need to increase the number of partitions and consumers for the topic to process the topic at the same rate with tiered storage as with local
- But you should ideally do this when creating the topic (although tiered configurations can be changed after creation), and
- Given that you are reading historical data there may not be a particular rush to process them.

What else have we noticed about the relative performance of local vs. tiered storage? Here are some other observations:
- Producer (write) latency is not impacted (as copying segments to tiered storage is asynchronous).
- Copying segments to tiered storage uses more Kafka cluster resources—at least 10% more CPU (and potentially network)—so you may need to size your cluster accordingly.
- Copying segments to tiered storage can take time, but in theory there’s no particular rush to copy them, unless your local storage is about to be exhausted Always try to ensure sufficient storage headroom.
- Similarly, with the deletion of local segments—it can take time, see the previous point.
Note that (a) none of these tests were run for longs periods of time (e.g. hours), (b) on a typical size production cluster (3 brokers is very small) (c) or at full load for producers or consumers—so they don’t reveal/compare maximum capacities, and (d) reported latencies are only averages—ideally percentiles would be reported.
The averages are likely to be skewed by high tail latencies (I did notice longer latencies between initiating the consumer poll and the first batch of records to be returned, presumably because there is overhead in retrieving the first segment from S3).
A Better Water Model of Kafka Tiered Storage—a Dam!

The Hoover Dam wall with the outflow from the hydroelectric plant way down below
(Source: Paul Brebner)
After the false start with the tiered fountain model of Kafka tiered storage (in Part 1), and reading these 2 blogs, you can probably see where it needs some improvements.
So, what’s a better, water–based model of Kafka tiered storage? A Dam—with pumped hydro. Time to dam the river!
How does water get past (over, under, around, through) a dam, and how does a typical hydroelectric dam work? There are several water routes possible.
Typically, water for the turbines comes from the bottom of the dam, so starts flowing as soon as there is any water in the dam. If the water level in the dam rises too much then a spillway allows the water to escape around the dam before it can reach the top. But that is another route—over (some dams are designed to spill over the top, but others aren’t and would fail catastrophically). So, in the worst case, if the dam fails, through the dam!
So, forget fountains and keep the dam in mind as we summarize what we’ve learned about Kafka tiered storage. We never want the local broker storage to fill up completely (to reach the top of the dam) as something will break. How does Kafka/dams prevent this from happening?
First, tiered storage works like the hydroelectric outflow, data is continuously copied from local to remote storage (unlike a fountain, where the top tier has to fill up before overflowing). This happens as soon and as quickly as possible (once each segment is rolled/closed).
Second, to ensure fast consumer reads, some data is retained on the local storage (local.retention.ms configuration)—this is like water in the dam lake, it’s there to use and enjoy (e.g. for fishing and water sports etc.).
Three, to ensure that the local storage isn’t exhausted, you need to optimize how long/much data is retained as local segments (again, using local.retention.ms) before being discarded—this is a similar mechanism to dam spillways. The spillways on the Hoover Dam are just huge drains!

(Source: Wikimedia)
{kind=link}
Finally, for most dams, the water is only used once. However, there’s another type of system that reuses water, pumped hydro. The water that flows through the turbines is kept in another reservoir, from where it can be pumped back up into the main dam when needed (or may overflow and be discarded).
This models Kafka tiered storage: copying of segments to remote storage, reading from remote storage when required again, and deletion of remote segments.

(Source: Adobe Stock)
Kafka Tiered Storage Is a Write-Through/Read-Through Cache
By the end of this discovery process (and aided by the Pumped Hydro Dam model), I realized that there’s an even simpler model for Kafka tiered storage: Kafka tiered storage is really just a write-through cache.
Data is first written to the local Kafka storage (as normal) and then written through Kafka to the backend (remote) cloud storage (asynchronously, after a short delay due to having to wait for active segments to be rolled/closed)–which technically makes it a “write-back” cache!
The local storage (cache layer) is used for reads by default, but if there’s a cache “miss”—i.e. once it expires (due to cache eviction), it works as a read-through/back cache, the remote copies are used instead (as long as they haven’t expired too). Simple really!
This is a tried and trusted caching approach for high performance distributed systems but is sensitive to things like the cache hit rate, the cache eviction policies and backend storage latencies, and is an essential “feature” of many n-tiered architectures—one of my first conference papers evaluated n-tiered middleware architecture performance.
10 Things to Watch Out For
- You need an AWS S3 bucket for remote storage.
- Create an Instaclustr managed Kafka cluster with tiered storage enabled.
- Create topics with tiered storage enabled and sensible retention configurations based on your use case, consumer behaviour, and write rate and local storage size (the local.retention.ms = retention.ms default value will not be a good choice, it should be << the default value in practice).
- Segments are written to remote storage as soon as possible after they are closed (unlike some documentation which suggests they are only copied once the local retention limit is reached—this is incorrect).
- So, you will have more copies than the replication factor (RF) setting most of the time (apart from the active segment which only has RF copies).
- Remote operations (copy, delete, read) take extra cluster resources and extra time.
- Consumers can work out if they are reading from local or tiered storage by comparing the current time to the local.retention.ms setting for the topic (in theory at least, if reading using time rather than offset). Is this useful? Maybe, as given reduced read performance you may need to spin up more consumers to get a higher read rate for some use cases.
- Write performance (latency at least) is not impacted by tiering, but read performance is potentially slower (reduced throughput, higher latency)—but “your mileage (km?) may vary”—so we recommend doing your own benchmarking as there are multiple factors that could impact read performance from remote storage (cluster resources, cluster load, choice of cloud storage to use for remote storage, segment sizes, record sizes, number of topic partitions and consumers, and consumer processing latency etc).
- If you delete your Instaclustr managed Kafka cluster, any remaining tiered segments on S3 are not automatically deleted—you can either manually delete all the tiered topics before cluster deletion, or manually delete the S3 objects yourself afterwards.
- Try out Tiered Storage yourself with Instaclustr’s Public Preview and spin up your first cluster for free!