Instaclustr recently announced the availability of a public preview of Apache Kafka® tiered storage. This is a long-awaited “feature” (more a fundamental architectural shift really), proposed in KIP-405 in 2019, which finally appeared in Kafka version 3.6.0 late last year (KAFKA-7739).
Tiered storage is still “early access” so is not currently recommended for use in production and comes with some limitations. Kafka version 3.8.0 was released while I was writing this (July 30, 2024) and has many tiered storage bug fixes), so keep a look out for the production-ready version.
What is Apache Kafka “Tiered Storage”?
Put simply, it’s a way of “tiering” the Kafka data (records, associated with topics and partitions) so that cheaper and bigger storage can be used in conjunction with the existing local storage.
Previously, a Kafka cluster was only made up of multiple identical brokers that provide both compute and storage resources. To increase storage you had to add more brokers or increase the size of brokers (change to brokers with larger disks).
But by doing this you are also increasing the compute capacity of the cluster, so you can’t increase storage capacity independent of compute capacity.
So, What’s Changed?
Apache Kafka calls this a new feature, but in my opinion, it’s a fundamental architectural shift from a relatively simple homogeneous cluster architecture to a (more complex) heterogeneous tiered architecture. With tiered storage, you now have the option to have essentially infinite record storage using cheaper cloud storage.
Some local storage is still required, but you can potentially reduce the amount of local storage needed, and/or increase the total amount of storage in use (and therefore how much data and how long the records are maintained for) by copying records to cloud storage.
If you need to read older records that are only available on cloud storage, they are automatically moved back to the brokers. All of this comes with no major changes to the Kafka clients (producers and consumers), but there are a few extra topic configurations for consumers; the tiered storage works transparently.
Kafka is a streaming system and streams, by definition, are fast-moving, continuous, unbounded, and essentially infinite—the data just keeps coming and you may want to go back to the source again multiple times for various use cases. As a result, Kafka water metaphors are common, including the “Current” conference.
I recently wrote about the connection between a dam I was kayaking on and Kafka. There’s a long history of using “water” to model other systems (e.g. MONIAC).
I thought a tiered fountain would be a good way to explain the new Kafka–tiered storage—water cascades from the top tier into the lower pond:

A 2-tiered fountain (Ganymede’s fountain) in Bratislava, Slovakia, where the recent Community over Code EU 2024 conference was held. (Source: Paul Brebner)
However, a fountain isn’t a 100% accurate model of Kafka tiered storage. Yes, it does illustrate the general flow of records from the top tier (representing Kafka brokers) to the bottom tier (representing cloud storage), and then back again if a consumer needs them—but we will discover that there is no waiting for records to “overflow” from the top tier before they spill into the pond at the bottom.
So, let’s see how it actually works, with a different type of water feature to explain it eventually.
What’s Hiding Behind the Kafka Partitions?

(Source: Adobe Stock)
No, not a giraffe! But what is hiding behind the partitions?
To understand how Kafka tiering works, it helps to understand the basics of how Kafka normally stores data on the broker’s filesystems.
All I previously knew about this aspect of Kafka was that Kafka writes an append-only log of records to the filesystem, as this is faster than random writes to disk, and ensures that all the records are available for multiple consumer groups, and potential replaying later if required.
This was one of the fundamental differences between traditional Message Oriented Middleware such as JMS, which optionally persisted messages to disk for higher durability, but then had to delete them once they were consumed—with more overhead. I noticed that newer messaging systems like Apache RocketMQ now persist by default.
But reading about Kafka tiering I found out that records in a given partition are written to multiple disk “segments” (Here’s a good explanation of partitions and segments).
When the current (called the “active segment”) for each partition becomes full (based on time/age or space/size) it is closed or “rolled”, and made read-only, and a new segment is created.
All subsequent records written to the partition are written to the new active segment. The “active segment” is always the most recent segment of a partition and is the only segment that new records are written to.
So, at a high-level, topics have multiple (1 or more) partitions that have multiple disk segments, only one of which is active per partition at any one time.
But what are segments? They are individual files on the disk, and each segment contains a range of record offsets for a single partition.
For a Kafka cluster, there are multiple segments for the same partition/offset range based on the replication factor (RF=3 for production is common—which means there are 3 copies of each segment on different brokers and disks).
Spoiler alert: with Kafka tiering there can be more than RF number of segments!
If consumers are keeping up and processing records in close to real-time, they will be mostly reading from the active segment. If they get behind or want to read older data from a specific offset/time, or just from the beginning (offset 0), then they read from the closed segments.
Segment Deletion—Space vs. Time

(Source: Adobe Stock)
But do the non-active segments last forever? No—by default they are deleted after a retention period, otherwise, the finite disk space on the brokers would eventually fill up–real (local) storage is not infinite in practice.
For non-tiered Kafka, once the local segments are deleted the data has gone for good (unless backed up somewhere else), and an attempt by consumers to read non-existent records will result in an error.
The relevant broker log configurations that determine how long records are available for consumers to read:
- retention.hours (default 168)
- retention.minutes
- retention.ms
These configure the time to keep a log file before deleting it. There’s a hierarchy for these (ms to hours, smaller units override bigger ones, and the Kafka CLI only allows the ms version).
The default is 168 hours (1 week = 7 days = 168 hours), which can be overridden by setting any of the others or setting log.retention.ms to -1 for no time limit (useful if you want to specify a size limit, see below).
Logs can be deleted based on space/size – although this makes it harder for consumers to determine if records will be available or not (noting that consumers can read from specific offsets or times—offsets are more common, but you can’t know the time for a given offset in advance):
This is -1 by default (infinite), which means that only the time limit applies—unless it’s also -1 in which case segments are never deleted!
But what does this setting mean and when does it come into play? From some extra reading, I discovered that it’s the maximum size of logs per partition in a topic (also described here in the topic configuration docs), so the maximum size for a topic is therefore:
maximum topic size = log.retention.bytes x number of partitions in the topic
(I’m not sure if this includes the active segments or not). If you set log.retention.bytes then both time and size limits apply—whichever kicks in first will result in segment deletion—i.e. delete if (time >= log.retention.ms || size >= log.retention.bytes).
To summarize what we know so far, segments have a lifecycle like this:

Now let’s move on to tiered storage!
Tiered Storage in Practice
Given this basic background on Kafka storage, I decided it was time to try out our new Kafka tiered storage service for real.
Apache Kafka tiered storage documents are here: https://kafka.apache.org/documentation/#tiered_storage
Our support documents are here:
https://www.instaclustr.com/support/documentation/kafka-add-ons/using-kafka-tiered-storage/
The process for creating a Kafka cluster with tiered storage on our console (RIYOA—Run In Your Own Account—is the only option at present) is very similar to a normal Kafka cluster but requires the extra option of a Tiered storage Enterprise Add-on.
You also need to provide an AWS S3 bucket that has been previously created and have access to. This is where the tiered Kafka data will be stored.
These steps result in the creation of a Kafka cluster with the broker level remote.log.storage.system.enable configuration set to “true”, allowing topics to be created with tiered storage.
Remote.storage.enable
But note that by default topics are not enabled for tiered storage—you have to create/configure them individually with the following configuration per topic (e.g. using the Kafka kafka-topics.sh CLI command):
–config remote.storage.enable=true
This probably means that when you create a Kafka cluster with tiered storage enabled you should deselect the option to automatically create topics (when a record is first written to a topic), as topics automatically created will not have tiered storage enabled.
But what happens once tiered storage is enabled for a topic?
I discovered (by trial and error) that there are several other configurations you need to think about for topics with tiered storage. I was trying to test tiered storage out by creating topics with tiered storage enabled, and then inspecting the AWS S3 bucket to see if/when the log appeared.
I was mystified as this was sometimes taking a long time. I also noticed (using the console monitoring to see how much local disk space was being used) that the disk usage increased substantially before eventually flattening off and/or dropping. What was going on?
After more investigation, I discovered several essential things about tiered storage. First, the current active segment on the local storage must be closed/rolled before it is eligible to be copied to tiered storage. Once it’s copied then the closed local segment is then also eligible for deletion. But what determines when these events happen?
Local.retention.ms/bytes
Given that we’ve looked at the default retention configurations already, let’s see what’s changed for tiered storage for retention. There are some new configurations at the broker level as follows:
- local.retention.bytes
- local.retention.ms
Taking a step backwards briefly, the original log.retention.bytes and log.retention.hours/minutes/ms still apply globally–that is, they determine how old/large segments can get before deletion—but once tiered storage is enabled for a topic, in practice this means that the oldest segments are on tiered storage so these values determine when segments on S3 are deleted.
This is a big change from non-tiered Kafka, as previously these configurations determined the maximum age/size of segments globally AND on local storage (as they were only available in one place).
But now with tiered storage what determines the maximum age/size of local broker segments? Simply, these new local configurations. Both have default “magic numbers” of -2, which means the same value as the corresponding original log.retention configurations.
This default in unlikely to be useful in any practical scenario that I can’t think of however, and the local values would typically be << the global/remote values.
These new local storage settings can also be configured at the topic level (with the Kafka CLI) as follows:
- –config local.retention.ms=value
- –config local.retention.bytes=value
You can also override the original log.retention values if you wish, which as noted already, for tiered storage topics determine the max time/size of segments on S3:
- –config retention.ms=value
- –config retention.bytes=value
This diagram helps understand the relationship between local and remote retention settings, and if local or remote segments are used by consumers:
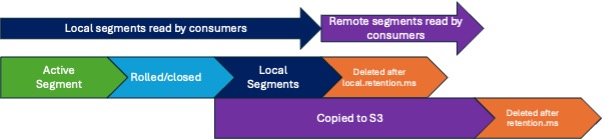
Time To Roll up the Segments

Rolled (coiled) rope on a boat ready for use, Ha Long Bay, Vietnam (Source: Paul Brebner)
But what explained the long delay in the appearance of log files on S3? Based on some erroneous descriptions of how Kafka tiered storage works (that segments are only copied to remote storage once they reach the retention limit—this is not correct), I wasn’t expecting to see objects appearing in S3 immediately, so I was somewhat confused about when to expect to see them created.
Fundamentally, segments are not eligible for copying to tiered storage until after they are closed. When is the active segment closed/rolled? Again, there is a hierarchy of configurations which impact when the active segment is rolled, starting at the broker level with:
- segment.bytes (default 1GiB)
This setting determines the maximum size of each segment. The default value is 1GiB. Then there are also some time-based limits:
- Log.roll.hours (default 168 hours)
- There are no minutes
- Log.roll.ms
The default is 168 hours! With the default settings, it can therefore take a while before the local active segment is “rolled” and eligible for copying to S3—whichever is first of writing 1GiB of records—to a single partition, so if a topic has many partitions and a low write rate, this could take a long time—or up 1 week when the roll time limit kicks in.
There are also topic-level configurations for these. For testing, I tried changing these settings to make it more immediately obvious if tiering was working or not:
- –config segment.ms=10000
- –config segment.bytes=100000
This forces the rolling of active segments after 10s or 100k bytes, whichever comes first. These changes were just for testing, in production a larger segment size (e.g. the default) will result in better performance (see below).
On the AWS side of things, here’s an example of what you can expect to see.
Under Amazon S3, buckets, and the name of the bucket that was used during the console creation process, you will see an object with the cluster ID-data, with folders for each topic that has tiering enabled, more folders for each partition, and for each partition, multiple objects of type indexes, log, and rsm-manifest as follows (this was from a run using the default segment size):

So, to sum up what we’ve discovered so far, if you create a topic with tiering enabled, then segments will be copied once they are closed to S3.
It’s important to note that copies are made as soon as possible after closing, but potentially with some (small) delay. The copying process is asynchronous, and relies on fixed Kafka broker resources, so it does sometimes take time.
Consequently, you can end up with more than the replication factor number of copies of segments for some time. That is, the local segments will typically overlap with the remote segments for some time.
But this depends on the local.retention configuration mentioned above. In theory, you can (and I have tried to) set local.retention.ms to 0 or small values (seconds or minutes).
So why would you want to set it to a higher value? Well, the read path is still more or less the same for Kafka consumers. If a consumer wants to read records, and they are available from local storage, that’s where they will be read from—and this may be faster than retrieving them from S3 (see below).
What are the trade-offs? If you have high write rates and limited local storage you may need to be more aggressive with the local.retention settings. Experiments revealed that it can take significant time (tens of minutes) for the deletion of local storage that has hit the retention limits to kick in.
What’s going on? As far as I can tell, log deletion is only “best effort”, there’s no guaranteed time of deletion, and the time configurations are just the maximum time that records are guaranteed to be available to be read by consumers—they may hang around longer. In particular:
- remote.log.manager.task.interval.ms
- Interval at which remote log manager runs the scheduled tasks like copy segments, and clean up remote log segments, default 30 seconds.
- remote.log.manager.thread.pool.size
- Size of the thread pool used in scheduling tasks to copy segments, fetch remote log indexes and clean up remote log segments, default 10.
- log.retention.check.interval.ms
- The frequency in milliseconds that the log cleaner checks whether any log is eligible for deletion, default 5 minutes.
- file.delete.delay.ms
- The time to wait before deleting a file from the filesystem, default 1 minute.
In practice, these times are cumulative, impacting when deletion occurs:
Active segment → full/time limit → rolled → copied to S3 → local.retention limit reached → segment eligible for deletion → check interval → file delete delay → deleted!
This graph of time vs. disk used (GiB) on my test cluster shows that the local segments are being deleted approximately every 5+ minutes giving a saw-tooth pattern for disk usage:
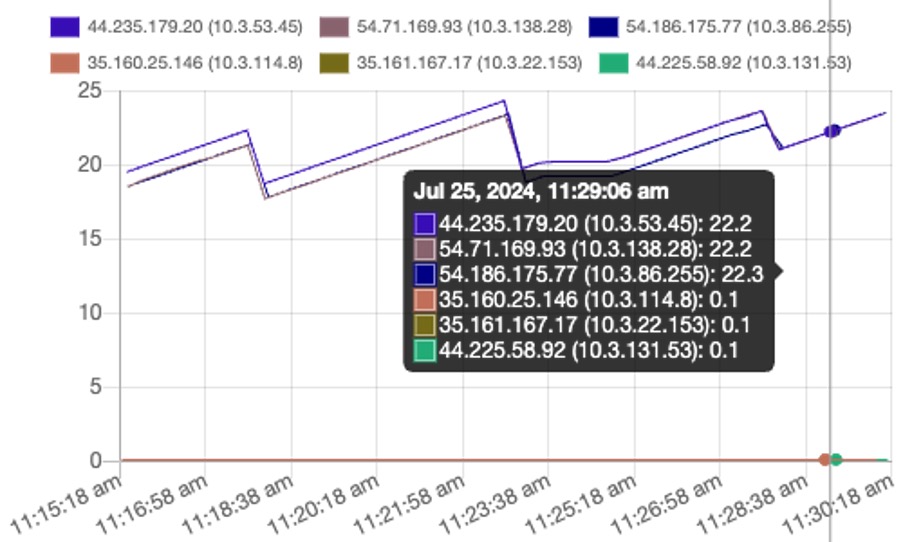
Remote Segment Deletion—Time to (Eventually) Take out the Rubbish

Remote segment deletion takes place eventually, i.e. once segments are eligible, they will eventually be removed—just like putting the bins out on recycling collection day. (Source: Wikimedia)
{kind=link}
I was curious to also check if/when segments stored on S3 were deleted based on the retention configurations. Sure enough, they are, but sometimes slower than for local segments.
I guess there’s no particular rush and depending on other tasks (e.g. copying and reading segments to/from tiered storage) there are finite resources to use for deletion. Deleting topics manually for some reason triggered remote segments to be deleted more quickly.
But watch out, if you spin up a trial Kafka tiered storage cluster, test it out, and then eventually delete it, it doesn’t automatically delete the segments from S3—you will need to remember to do that manually.
There is probably no point in keeping the S3 objects around any longer than the Kafka cluster that produced them, as once the cluster has been deleted there is no longer any meta-data that would enable them to be (easily) read by Kafka again.
That’s all for Part 1! Check out Part 2 where we’ll take a look at Performance and a new and improved Dam model of Kafka tiered storage.