
(Source: Adobe Stock)
1. Introducing Stream Processing
It’s been a while since my first (and only) Christmas Special Blog—back in December 2017 I wrote my first Apache Kafka® blog, about using Kafka for a Christmas tree light simulation. Since then I’ve built lots of realistic Kafka (and other open source technologies) demonstration applications to solve challenging Big Data + Streaming problems including an IoT logistics simulation (“Kongo”, my first multi-part Kafka blog series), Anomalia Machina (massively scalable anomaly detection achieving 19 billion checks per day, section 2.2 here), a geospatial version (Terra-Locus Anomalia Machina), a zero-code pipeline series (section 2.3 here), and recently a drone delivery application using Uber’s Cadence®, Kafka, and some ML!
Early on I wrote 3 blogs on Kafka Streams, introducing the Streams DSL concepts including topology, and a couple of Kafka Streams demonstration applications including keeping track of the weight of goods in trucks to prevent truck overloading (for the “Kongo” application), and solving a murder mystery (a standalone example). But I haven’t used Kafka Streams since 2018—although the demonstration applications involved complex stateful/windowed streaming consumers, which overlaps with the Kafka Streams goals (it also targets many-to-many stream processing, joins, and aggregations).
In fact, stream processing isn’t new, it’s been around since at least the “noughties”. I was involved in a joint project between the Australian National R&D Laboratory CSIRO (Commonwealth Scientific and Industrial Research Organisation) and the OGC (Open Geospatial Consortium) to build and evaluate a prototype continental scale real-time water monitoring and management system using the OGCs Sensor Web enablement standards, reference implementations, and an assortment of technologies available in the early 2000s. We explored using XMPP, Coral8, and Esper for CEP (Complex Event Processing) as part of the pipeline. Coral8 has long gone but Esper is still around (and is open source).
However, one of the challenges we discovered was scalability—particularly related to state management and stream joins over multiple streams with time windows. This came back to bite me in the 2010s at NICTA (National ICT Australia) and a spin-out company when I invented an automated distributed systems performance modeling tool. It used Java Streaming XML (StAX) to process millions of application performance traces to automatically build performance models in real-time—but it took up to 1 second to process each trace (each trace had 1000s of “spans”, correlated by an id, which needed joining, aggregation, state management, and much more to process)!
Since then, there has been an increasing amount of attention in the research community to stream processing scalability (e.g., “A survey on the evolution of stream processing systems – 2023”), and lots of new technologies, including Apache Kafka. Apache Kafka Streams is intrinsically more scalable than some of the older approaches, as it is based on Kafka. It is a Kafka API with a library, so it uses partitions to achieve scalability and Kafka for intermediate stream state management, along with RocksDB for stateful KTable management. Other complementary technologies that I’ve come across over the last few years include Apache Flink, Apache Spark (I wrote an older blog on “Apache Spark Structured Streaming with DataFrames”, Lenses, and of course some of the cloud-native stream processing platforms.
2. A Christmas Special!

(Source: https://www.flickr.com/photos/doctorwhospoilers/8244412757/ CC 2.0)
So, continuing in the tradition of Christmas Specials, let’s see if we can help Santa out this year. Santa’s Elves are normally very productive, but recently something has gone amiss in Santa’s workshop! The “toy” Elves and the “box” Elves have stopped talking to each other and have set up 2 separate production lines. Instead of a single streamlined production system with the toys and boxes being matched on 1 conveyor, there are now 2 conveyor belts. The “toy” conveyor is run by one group of Elves, and they put random toys on for packing. The “box” conveyor is run by a different group of Elves, and they just toss random boxes onto it. Why does this matter? Well, each toy has a unique “toyType”, and requires a specific box matching that type for it to be packed in—each toyType has a custom box for size, shape, and instructions etc., so you can’t use a random box for a given toy.
The packing Elves therefore need some help to match toys and boxes—we assume they pick a toy off the toy conveyor and have to find a matching box from the box conveyor as fast as possible, then place the toy in the box on another conveyor belt which takes it to Santa’s sack for delivery.
But time is critical! Because of the speed of the process, there’s a maximum grace period of 1 minute for each packing Elf to find a matching box, otherwise the unmatched toys and unused boxes fall off the end of the conveyor belt and an alarm goes off and the whole process grinds to an almighty halt! A back-of-the-envelope calculation reveals that for all the presents to be processed for every child (2 billion) in a year (31,536,000 seconds), 64 toys need to be packed per second (3840 per minute).

Is There Anybody In There? (Canberra’s very own “Tardis”)
(Source: Paul Brebner)
Perhaps we can help Santa with some streaming open source technologies? Apache Kafka Streams would be an ideal match as it appears that we need to join 2 input streams together to produce a single output stream. But by bringing in the extra tradition of the Dr Who Christmas Specials as well, let’s bring in another dimension—Materialization! The Tardis travels through the Time Vortex by Dematerialising to enter the Vortex (thereby travelling through space and time), and Re-materialising or Materialising to arrive at the destination—note the English spelling as Dr Who originated in the UK. The Tardis also makes a distinctive groaning/wheezing noise when it enters and exits the Vortex (the complete history of the sound is here).
For a sound-effects-free version of Materialization, what I had in mind is a new stream processing technology that I came across recently, called RisingWave (from RisingWave Labs). RisingWave is worth a look because it’s open source (Apache 2.0 licensed), it uses a distributed streams processing engine so it promises to be scalable, uses cloud-native storage for state management, uses “SQL” for the processing language (and is PostgreSQL compatible at the protocol level), and is available as a cloud service or you can download and run it yourself. It uses Materialized Views (a magic database concept, similar to caching) for implementing efficient incremental real-time streams (note that this feature isn’t unique to RisingWave, Kafka Streams also does something similar for KTables—KTables are just materialized streams—like the materialised Tardis).
RisingWave Labs was kind enough to help produce this blog by providing a free RisingWave cloud trial and generous assistance with advice on connecting to Instaclustr’s Managed Kafka and writing RisingWave SQL etc., so what are we waiting for? In the rest of the blog, we’ll build a quick Kafka Elf Packing Assistance Machine (KEPAM?), and then do the same with RisingWave (combined with Kafka).
3. A Kafka Streams Toy and Box Matching Solution
The main components we need for a Kafka Streams example are: A Kafka cluster, Kafka producers (x2), a Kafka Streams processor, and a Kafka consumer (we’ll just use the Kafka CLI for that) to check the results.
3.1 Kafka Cluster
It’s easy to create a free-trial Instaclustr-managed Kafka cluster—just go to the trial signup page here. Here’s the support documentation that takes you through the steps for creating a Kafka cluster. For this experiment, I created a small developer-sized Kafka (3.5.1) cluster on AWS (with ZooKeeper rather than KRaft which is in preview at present—this also allows for Client to Broker TSL Encryption to be turned off, i.e., don’t select any “Kafka Listener Options”). I also decided to provision my cluster in AWS “US East (Ohio)” as RisingWave Cloud also supports this region.
3.2 Kafka Producer
We created 2 Kafka topics (“toys” and “boxes”) as follows. Both topics have a string Key of “toyType” (a random number from 1 to 100), and the “toys” topic has a single value of “toyID” and the “boxes” topic has a single value of “boxID” (both are JSON Strings). These represent unique “serial numbers” for toys and boxes and are monotonically increasing sequences (but are not comparable across toys and boxes, joins can only be done over “toyType”). The producers run for some time (several minutes) to generate two input streams of data representing the toy and box conveyor belts. The rate per second is configurable (for both topics, but typically would be the same), and given that toyType is a uniform random number there is a high chance that each toyType produced in a minute has one or more matching boxes. Here’s the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.io.FileReader; import java.io.IOException; import java.util.Properties; import java.util.Random; import org.json.JSONObject; public class ToysAndBoxes { public static void main(String[] args) { Properties props = new Properties(); try (FileReader fileReader = new FileReader("producer.properties")) { props.load(fileReader); } catch (IOException e) { e.printStackTrace(); } KafkaProducer<String, String> toyProducer = new KafkaProducer<>(props); KafkaProducer<String, String> boxProducer = new KafkaProducer<>(props); String toyTopic = "toys"; String boxTopic = "boxes"; Random rand = new Random(); int toyID = 0; int boxID = 0; int toyRate = 10; int boxRate = 10; int maxSeconds = 10; int maxTypeID = 100; for (int t=0; t < maxSeconds; t++) { // create toys for (int i = 0; i < toyRate; i++) { JSONObject toy = new JSONObject(); toyID++; toy.put("toyid", Integer.toString(toyID)); String key = Integer.toString(rand.nextInt(maxTypeID) + 1); toyProducer.send(new ProducerRecord<String, String>(toyTopic, key, toy.toString())); } // create boxes - may be at different rate to toys for (int i = 0; i < boxRate; i++) { JSONObject box = new JSONObject(); boxID++; box.put("boxid", Integer.toString(boxID)); String key = Integer.toString(rand.nextInt(maxTypeID) + 1); boxProducer.send(new ProducerRecord<String, String>(boxTopic, key, box.toString())); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } toyProducer.flush(); boxProducer.flush(); toyProducer.close(); boxProducer.close(); } } |
3.3 Kafka Producer Configuration
To connect to our Kafka cluster and test if the producer is working, go to the “Connection Info” tab on your Kafka cluster and find the Java Producer/Consumer configuration data (which is customized for your cluster)—it will look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer security.protocol=SASL_PLAINTEXT sasl.mechanism=SCRAM-SHA-256 sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="[USER NAME]" \11 password="[USER PASSWORD]"; |
Create and add this to a couple of files (producer.properties and streams.properties) as the Java code will need it to connect to your cluster.
You will also need to add the IP address of your client machine to the Kafka cluster Firewall Rules tab.
You can check if the producers are working correctly by running the Kafka CLI with the correct configuration as provided in the Producer/Consumer CLI tab.
3.4 Kafka Streams DSL

Now it’s time to join the conveyor belts!
(Source: Adobe Stock)
Here’s a code snippet for the Kafka Streams DSL “I” wrote to join the toy and box topics over a 1–minute window:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
Properties props = new Properties(); try (FileReader fileReader = new FileReader("streams.properties")) { props.load(fileReader); } catch (IOException e) { e.printStackTrace(); } StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> toysStream = builder.stream("toys"); KStream<String, String> boxesStream = builder.stream("boxes"); KStream<String, String> toys_and_boxes = toysStream .join(boxesStream, (leftValue, rightValue) -> leftValue + " fits in box " + rightValue, JoinWindows.of(Duration.ofMinutes(1))) ; toys_and_boxes.to("toys_in_boxes"); KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); |
Extra configuration properties (put them in streams.properties) for Kafka Streams include the following:
|
1 2 3 4 5 |
application.id=elves default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerdecommit.interval.ms=1000 |
When I say “I” wrote this code, actually I had some help—but not from one of Santa’s Elves —but from Bing+ChatGPT! Yes, ChatGPT is very good a taking instructions for Kafka producers and Kafka streams DSL and producing bug-free code. I didn’t write the producers or streams code and it worked perfectly (with some changes requested, i.e., the process can be incremental, I initially forgot to mention the 1-minute window and ChatGPT added that feature when requested).
This stream processing pipeline works correctly, and the results are written back to Kafka to the “toys_in_boxes” topic in the form:
|
1 2 3 4 5 6 7 8 9 |
{"toyid":"3"} fits in box {"boxid":"6"} {"toyid":"5"} fits in box {"boxid":"2"} {"toyid":"15"} fits in box {"boxid":"9"} Etc |
The assumption is that the packing Elves can consume this topic, and each Elf takes the next toyid, finds the correct box (e.g. 3 matches 6), puts the toy in the box on the output conveyor and goes back for the next toy. However, with this simple processor, there are a couple of simplifications! First, there may be no boxes that match a given toy in a 1–minute window. Second, there may be more than 1 box that matches. Finally, a box may already have been taken by another Elf (if it matched more than 1 toy in the window), so the Elf may have to go back to the topic to find another possible box. All of these could be fixed with minor modifications to the DSL (ChatGPT to the rescue again). Also, note that I/ChatGPT didn’t include any JSON-specific code—so it just treats the values as Strings, which works fine for this example (and it’s trivial to add JSON-specific extensions—just ask ChatGPT).
4. A Kafka+RisingWave Toy and Box Matching Solution
The main components we need for a Kafka+RisingWave example are: A Kafka cluster, Kafka producers (x2), a RisingWave Cloud cluster, RisingWave sources and sinks, a RisingWave SQL pipeline, and a Kafka consumer to check the results. We’ll reuse our Kafka cluster, Kafka producers (with some modifications), and the Kafka consumer from above.
4.1 RisingWave Cloud
Once you log in to the RisingWave cloud GUI (I used Google login as email wasn’t working for me), there is the option of creating a free cluster. I created mine on AWS in us-east-2 (which matches the region I created the Instaclustr Kafka cluster in). Once it has been created, you can click on the tabs on the left-hand side of the screen to look at the Cluster (Overview of cluster resource usage, materialized views, etc.), or create a source, query, or sink etc.
The first thing I wanted to do was create 2 sources to connect to my Kafka cluster topics.
4.2 RisingWave Source

Initially, we had some problems accessing the “chimney” (Source: Adobe Stock)
RisingWave is a Kafka Streams equivalent (in the Apache Kafka ecosystem at least, it also works with many other sources/sinks as well), so it needs to connect to Kafka directly to work, i.e., it doesn’t support Kafka Connect for integration. I initially tried using the RisingWave sink wizard to do this but found that the easiest solution was to create a sink in the Query GUI. First, you have to add the RisingWave cloud IPs to the Instaclustr Kafka cluster Firewall Rules page. For this demo I opened up all the ports using “0.0.0.0/0” as I had problems with adding the specific RisingWave IPs—this is not recommended for production, however.
Here are the 2 source SQL creations:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
CREATE SOURCE IF NOT EXISTS source_toys (toyid varchar) WITH ( connector = 'kafka', topic = 'toys', properties.bootstrap.server = IP1:9092,IP2:9092,IP3:9092', scan.startup.mode = 'earliest', properties.security.protocol = 'SASL_PLAINTEXT', properties.sasl.mechanism = 'SCRAM-SHA-256', properties.sasl.username = 'user', properties.sasl.password = 'password', ) ROW FORMAT JSON; CREATE SOURCE IF NOT EXISTS source_boxes (boxid varchar) WITH ( connector = 'kafka', topic = 'boxes', properties.bootstrap.server = IP1:9092,IP2:9092,IP3:9092', scan.startup.mode = 'earliest', properties.security.protocol = 'SASL_PLAINTEXT', properties.sasl.mechanism = 'SCRAM-SHA-256', properties.sasl.username = 'user', properties.sasl.password = 'password', ) ROW FORMAT JSON; |
Under the RisingWave GUI click on “Source” and you should see the 2 new sources you’ve created—all being well the “Health check” will show “Active” (eventually—there may be a slight delay). One slightly odd thing I noticed was that under “Has primary key” they both say “False”—we’ll come back to this Key question later.
If you click on the source name you can look at more details, including the “Schema” which describes the columns (remember, RisingWave is PostgreSQL compatible, so it looks and acts like a “streaming” database). For these sources, the columns include the named columns (toyid, boxid), but also some other interesting columns including “_rw_kafka_timestamp” (this is the way that you can refer to the Kafka timestamp).
Why did I go to the trouble of using the Query editor to create the sources rather than the Source wizard? The problem was that the wizard gave a message about connectivity errors, so I wasn’t sure if it was going to work or not. I went back and had a go with the wizard again and you can ignore this message as it does actually create the sources correctly, so perhaps the connectivity test is more strict than necessary. The other options I used are in the Kafka source documentation. For production, you would probably want to configure Kafka sources to use “scan.startup.mode=’latest’” so that only new records are processed.
4.3 Materialized View: Windows and Joins

Santa’s Sleigh slides (or sometimes flies)
(Source: Adobe Stock)
Materialized views are an important concept in RisingWave, and to process moving source data you need to create at least one Materialized view to consume them.
Here’s my first attempt – which didn’t work:
|
1 2 3 4 5 6 7 8 9 10 11 |
create materialized view toys_in_boxes as select source_toys.toyid as toyid, source_boxes.boxid as boxid from tumble(source_toys, _rw_kafka_timestamp, interval '1' minute) join tumble(source_boxes, _rw_kafka_timestamp, interval '1' minute) on source_toys.key = source_boxes.key and source_toys.window_start = source_boxes.window_start; |
I wanted to create a single stream from the 2 sources (source_toys, source_boxes), joined over the key (which is the “toytype” that matches toys to boxes), over a 1-minute window. You have a choice of window types in RisingWave—tumble and hop. With RisingWave you can join over 2 windows of the same type (and time period), so the tumble is performed first, followed by the join. Tumbling windows are contiguous time intervals, and hopping windows are scheduled time intervals.
Kafka Streams supports 4 window types: Hopping, Tumbling, Session, and Sliding (the last 2 are event-triggered). I wasn’t sure what the default JoinWindows windows type was that I used above—it’s a sliding window —so the window semantics may be different (the names are at least!). This is a big topic and includes academic work on time windows and terminology, use cases and how to select the correct time window type, and a comparison of if and how different Streams processing frameworks implement them, etc., so I may revisit this in a future blog. Here’s a recent survey of window types in stream processing systems.
4.4 Missing Keys
 Missing Keys can be challenging.
Missing Keys can be challenging.
(Source: Adobe Stock)
In this example I use a tumbling window for each source, using the virtual value “_rw_kafka_timestamp”, with an interval of ‘1’ minute. The problem with this example was immediately apparent when I tried to run it—there is no Kafka key in the RisingWave sources. Currently, RisingWave makes the Kafka timestamp visible, but not the Kafka key—this will be added in a future version. Note that in Kafka Streams joins are done over the Key, and streams can be “re–keyed” if you need a different key (and one of my older blogs has an example). In the meantime, what’s the workaround? I solved the missing key problem by modifying my Kafka producers, duplicating the “toyid” key as an extra value in the input topics (giving new topic and source names), and this SQL code:
|
1 2 3 4 5 6 7 8 9 10 11 |
create materialized view toys_in_boxes2 as select source_toys2.toyid as toyid, source_boxes2.boxid as boxid from tumble(source_toys2, _rw_kafka_timestamp, interval '1' minute) join tumble(source_boxes2, _rw_kafka_timestamp, interval '1' minute) on source_toys2.toytype = source_boxes2.toytype and source_toys2.window_start = source_boxes2.window_start; |
I asked Bing+ChatGPT to write the RisingWave SQL. Unfortunately, it probably doesn’t have sufficient examples to be accurate yet and made up the time window function (incorrectly). When asked to fix it, it hallucinated, making the problem worse (it could potentially be improved by providing RisingWave examples as “context” to the ChatGPT session). I asked for some human help from RisingWave eventually to get it working correctly.

Things that can wrong: Keys Tumbling into a Drain (Sink?)
(Source: Adobe Stock)
4.5 RisingWave Kafka Sink
Finally, you need to create a RisingWave Kafka sink to write the results back to our Kafka cluster, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE SINK toys_in_boxes2_sink FROM toys_in_boxes2 WITH ( connector = 'kafka', topic = 'toys_in_boxes2', type = 'append-only', properties.bootstrap.server = IP1:9092,IP2:9092,IP3:9092', properties.security.protocol = 'SASL_PLAINTEXT', properties.sasl.mechanism = 'SCRAM-SHA-256', properties.sasl.username = 'user', properties.sasl.password = 'password', ) |
The RisingWave Cloud GUI has a Sink tab, where you should now be able to see the new toys_in_boxes2_sink—unfortunately, you don’t see as much detail as the sources, e.g., the Kafka topic it is writing to.
The RisingWave Cloud GUI has a nice layout of the materialized view topology:

Unfortunately, it is missing the specific source and sink names (but the open-source version may have more information, under “Streaming -> Graph” – it’s nice that the open-source version has some bonus features).
5. Speed

(Source: Adobe Stock)
Given that Christmas draws nigh, let’s check if the Elf packing production line is keeping up, and that everyone will receive their gifts in time for Christmas day.
The RisingWave trial cloud cluster specifications are:
- Compute node: 1vCPU, 2 GB memory; x1
- Frontend node: 1vCPU, 1 GB memory; x1
- Meta node: 1vCPU, 1 GB memory; x1
- Compactor node: 1vCPU, 1 GB memory; x1
- ETCD: 1vCPU, 1 GB memory; x1
That’s a total of 5 vCPUs.
And the specifications for the developer Instaclustr Kafka Cluster are:
- t4g.small 2 cores, 2GB RAM (x3, a total of 6 vCPUS).
I modified the Kafka producers slightly to scale the arrival rate, and to ensure that the toyId cardinality was also scaled to ensure a consistent ratio of approximately 1.3 matching boxes per toy, no matter what the scale. The following graph shows the throughput (in, out and total) for increasing scale up to 100 x the required load (64 toys per second x 64 = 6,400/s):

The results are close to linear which is good. But I stopped at scale x 100 for 3 reasons: Too many toys—that’s enough toys for 200 billion people (orders of magnitude more than the population of the planet, although maybe some people receive more than 1 gift?!); there was an increasing lag in the matching results arriving at the destination Kafka topics (1-10s delay); and the resources (RAM in particular) on the RisingWave cluster were approaching a limit as shown in the following graph:
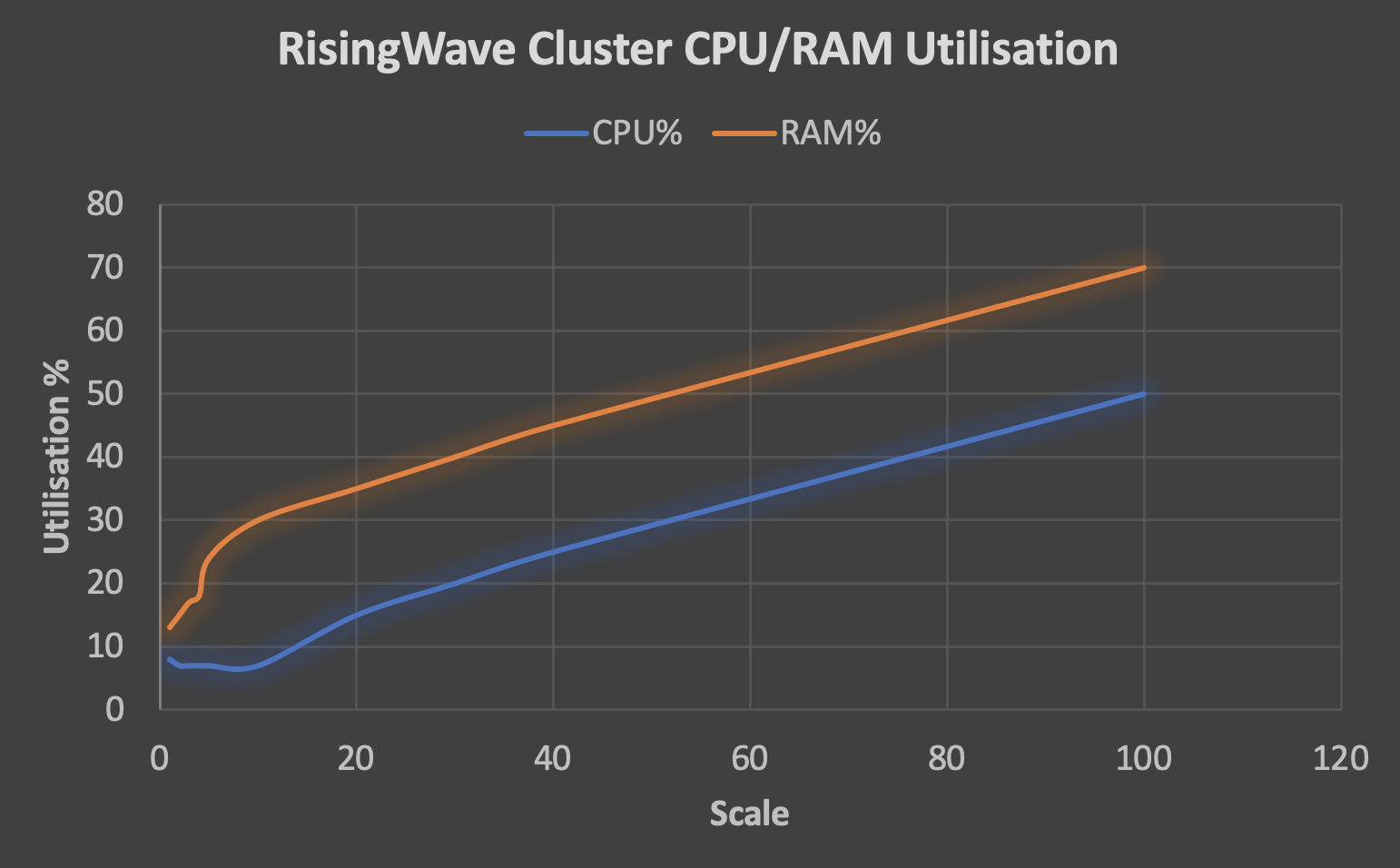
However, these results suggest that RisingWave could hopefully cope with a higher throughput with larger cluster sizes. The CPU utilization on our Kafka clusters was minimal (15% maximum) as Kafka can easily cope with 10s of thousands of msg/s per partition/vCPU. It’s also worth noting that Kafka Streams performed identically under these load conditions, so to see any differences we’d need to increase the throughput substantially.
6. Conclusions

Surfers riding the waves in Galicia, Spain
(Source: Adobe Stock)
So, what have we learned in this blog? Did RisingWave “rise” to the occasion of being a drop-in replacement for Kafka Streams (or better still, ksqlDB, which is also SQL-based but not open source)?
We’ve managed to spin up an Instaclustr Kafka cluster and a RisingWave cloud cluster and get them working successfully together—although there were a few initial challenges with creating RisingWave sources to connect to Instaclustr Kafka.
We’ve built a simple streams processing application using both Kafka Streams and RisingWave SQL to help Santa Elves’ solve their problem and pack toys in the correct boxes. So, both approaches solve the problem in one way or another.
Let’s have a brief look at the pros and cons and things to watch out for.
RisingWave is a Kafka Streams equivalent, so it behaves just like a Kafka client (and more), so it doesn’t use the Kafka Streams API, or even Kafka directly (e.g., for state management). However, as noted above, it supports many other sources and sinks so it can fit nicely into those ecosystems as well as the Apache Kafka ecosystem.
It manages state using cloud-native stores (e.g., S3). It therefore doesn’t use much of the Kafka cluster resources, leaving potentially more resources for other Kafka uses. But it must be provisioned with its own dedicated resources and has custom sources and sinks to integrate with other technologies, including Kafka.
Being a “self-contained” stream processing solution, it also can’t take advantage of any improvements to Kafka Streams. For example, I listened to an interesting talk from Current 2023 on dynamic rules for Kafka streams. Data and rules streams can be “joined” in a new DSL stream processor, which handles dynamic rules changes, and large numbers of rules and topologies etc. It uses some new Kafka Streams KIPS including version state stores (e.g., KIP-960, KIP-968, KIP-969). All Kafka Streams KIPs are here, including this brain-expanding one KIP-857: Streaming recursion! However, RisingWave is also innovating, including support for JSONB columns and recursive expressions on the roadmap.
RisingWave uses a different language (RisingWave-specific SQL) and terminology, so there is a bit of a learning curve to adopting it as your Streams Processor, particularly if you are familiar with Kafka Streams already. Time Window names and semantics may be different to Kafka Streams, so this may be confusing.
RisingWave doesn’t (yet) support the Kafka Key (or other Kafka meta-data apart from timestamp) so topics require extra pre-processing to add the key as a value for use in RisingWave.
The RisingWave GUI support for SQL topology pipeline visualization is only basic, but there is good GUI support for clusters, materialized views, sources, queries, and sinks etc. There is also basic support for graphing stream outputs in real-time which is nice (bar, line, and area graphs). And in theory, you can also connect more powerful visualization tools such as Apache Superset (which I’ve used before) to RisingWave.
Bing+ChatGPT doesn’t know the RisingWave SQL dialect 100% yet (mainly the windowing and temporal joins) and tended to hallucinate. However, it was good at Kafka streams DSL and “PostgreSQL” style RisingWave SQL (e.g., using a “DATE_TRUNC” function to split time-series into buckets, instead of using a RISINGWAVE windowing function).
The RisingWave cloud has nice GUIs and some wizards, but there are some minor issues with creating sources connected to Instaclustr Kafka with the wizard (they give a connectivity error, which can be safely ignored when connecting to Instaclustr’s Kafka). The workaround I used was to use the SQL query editor to create sources and sinks (RisingWave is aware of the problem and in the process of fixing it).
One major reason to use RisingWave over Kafka Streams may be scalability and resource usage. However, this is more than enough for one blog—enjoy your Christmas wave-catching activities (or whatever counts as holiday fun in your part of the world).

(Source: Adobe Stock)
Hopefully, by using our Kafka Elf Packing Assistance Machine, the Elves didn’t make too many mistakes packing toys into boxes—Season’s Greetings!