






















At Instaclustr we spend a lot of time managing Cassandra clusters – we have team of engineers that 24×7 do nothing but manage Cassandra clusters. Big clusters, tiny clusters, clusters with awesome data models and clusters with less awesome data models – we manage them all.
Over time, we’ve developed a lot of tricks and tools to help us in this job. We’re happy to announce that, as part of our commitment to the Apache Cassandra open source community, we’re making our most generally useful tools available for open use.
The tools (that we’ve imaginatively called ic-tools) supplement the information available from the nodetool utility that is part of core Apache Cassandra. Whereas nodetool tends to report based on summary statistics maintained as Cassandra services operate, ic-tools directly reads Cassandra’s data files when executed. This allows reporting of more detailed and accurate statistics.
We’ve found the information available from these tools to be invaluable in answering questions to help diagnose Cassandra issues or just better understand what Cassandra is doing with your data. The information available from the tools is pretty broad. Some highlights that will resonate with many Cassandra users include:
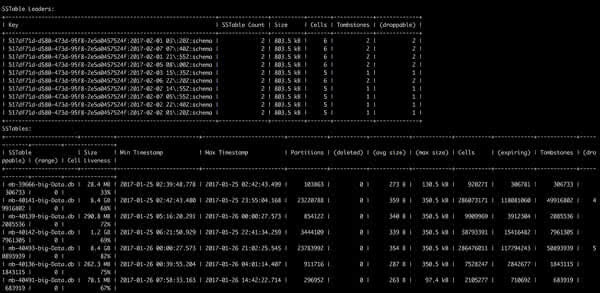
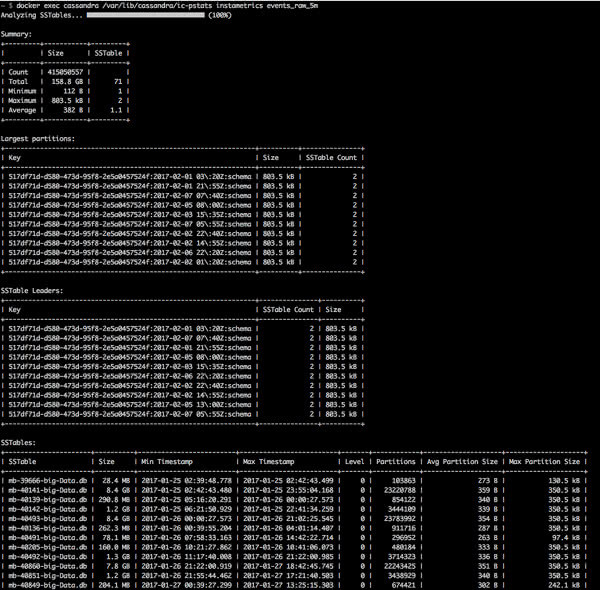
- Partition keys of the largest partitions by data size, number of columns and sstables spanned
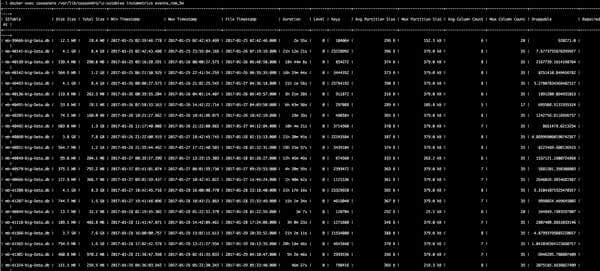
- Information about data age (timespan) of data in sstables
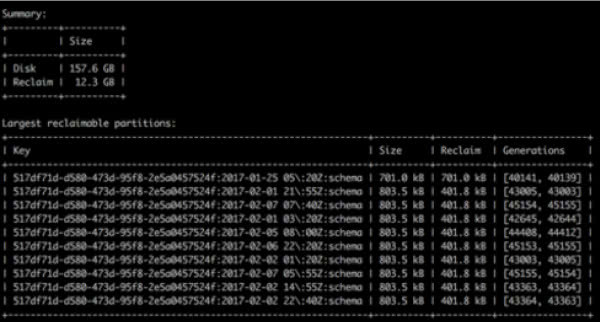
- Tombstone information including partition keys of partitions with the most tombstones and calculation of potentially reclaimable space if/when tombstones are purged
This is just a highlights list of key data. See the help page and examples below for a more complete list.
The tools are available on a supported basis for our enterprise support customers and on an unsupported basis for the general community (although we’ll probably answer questions on the C* user email list). For users of Instaclustr’s Managed Service, our Technical Operations team will run these as needed when working with you to help diagnose issues.
The source code is published on our GitHub. We’re more than happy to take pull requests and other suggestions for improvements. We’ll also be talking to the C* project to see if any of this code makes sense in the core project.
We hope these tools will be as useful for the rest of the Cassandra community as we’ve found them in our work. Let us know in the comments if you have any feedback.
Contact Instaclustr for any enquiries or sign up for a free trial.