






















In our Security Advisory published 8 January, we advised of up to 20% increase in CPU utilization and small increase in latency across managed clusters in AWS and GCP following the rollout of the patches to the cloud provider hypervisors. We have since observed a reversal of this impact in the weeks following the initial announcements. That is, these effects disappeared when further AWS and GCP patches were rolled out by the cloud providers.
We assessed the risk of the vulnerabilities to our environment as Low. Our clusters run as single tenant and customer access is limited to the application layer. If a user were able to exploit either of the vulnerabilities they could only gain access to their own information.
Patches have now been released for the instance operating system. Prior to a fleetwide rollout of these OS upgrades we undertook a benchmarking exercise to understand if any performance impact to customer clusters could be expected.
Results Summary
- Our benchmark testing showed no performance impact following the instance operating system patches.
- During the testing period, we noticed a fleetwide reversal of the initially observed CPU impacts of the patches. All benchmarks were repeated following this observation.
The following sections detail the full testing methodology and results of our Container Linux benchmarking.
Testing Methodology
Tests were executed against three different AWS instance sizes, and one Azure instance size. These were chosen as they are the more commonly used instance types in our managed service fleet.
| Cloud provider | Instance type | Node count | Instance CPU | Instance RAM |
| AWS | m4.xlarge | 6 | 4 | 16 |
| AWS | r4.xlarge | 3 | 4 | 30 |
| AWS | i3.2xlarge | 3 | 8 | 61 |
| Azure | DS12 v2 | 3 | 4 | 28 |
All cassandra clusters were running Cassandra 3.11.1.
All stress boxes were in the same private network and region as the respective cluster.
All stress boxes in AWS were running Ubuntu server 17.04.
The stress box in Azure was running Container Linux, and cassandra-stress was run from
inside a docker container.
Data was inserted and a mixed INSERT/SELECT workload was executed before and after upgrading the Container Linux version containing the meltdown patch (1576.5.0).
– data load was ran with 25 million iterations (date)
$ cassandra-stress user profile=stress-spec.yaml n=25000000 cl=QUORUM ops\(insert=1\) -node file=node_list.txt -rate threads=100
– mixed load was ran for 4 hours both before and after the upgrade (date)
$ cassandra-stress user profile=stress-spec.yaml duration=4h cl=QUORUM ops\(insert=1,simple1=10,range1=1\) -node file=node_list.txt -rate threads=30
The stress keyspace was using LeveledCompactionStrategy and NetworkTopologyStrategy with RF=3
The first round of testing showed no noticeable performance impact from patching
ContainerOS so the tests were re-run to confirm the results. The re-run presented the
same results.
Hypervisor performance gains
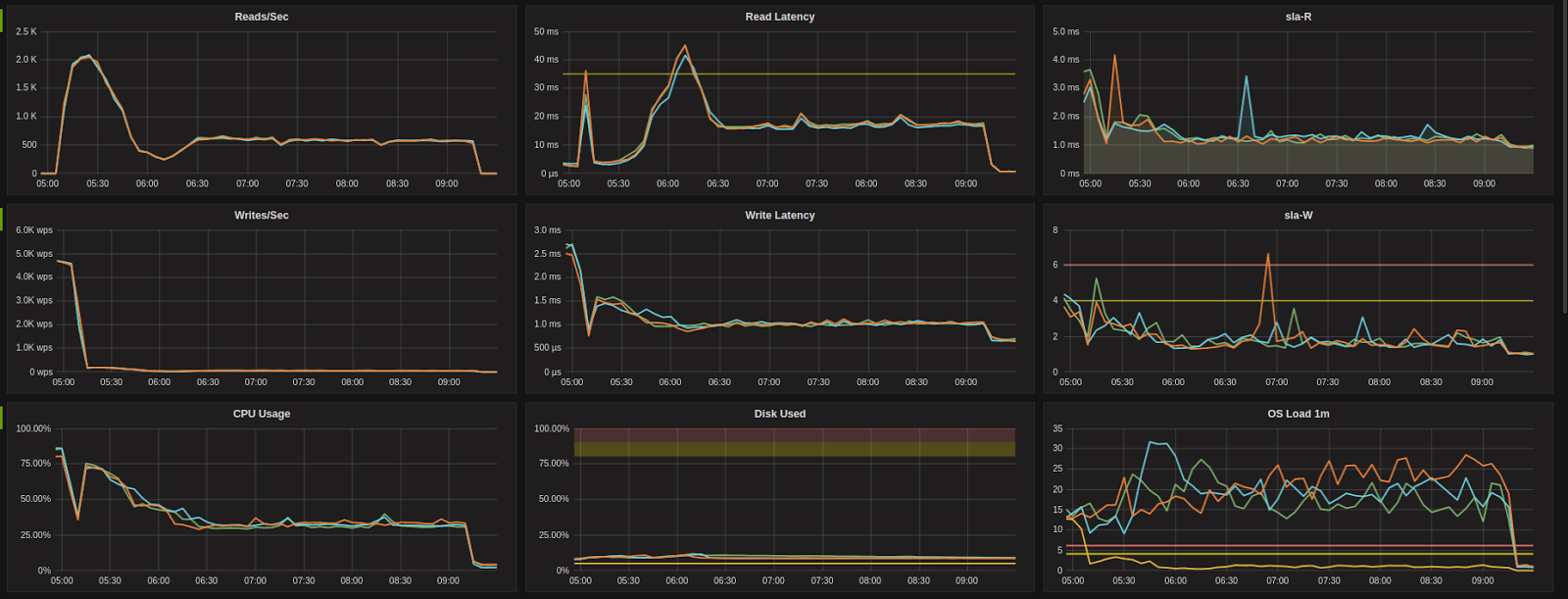
During the first round of testing executed on 11-13 January, we noticed a unexpected improvement in performance after upgrading. Upon further investigation we observed a similar improvement in performance across our fleet of managed nodes and concluded this was due to a patch made to the underlying AWS hypervisors and not related to the guest OS upgrades – the tests were repeated to confirm results.
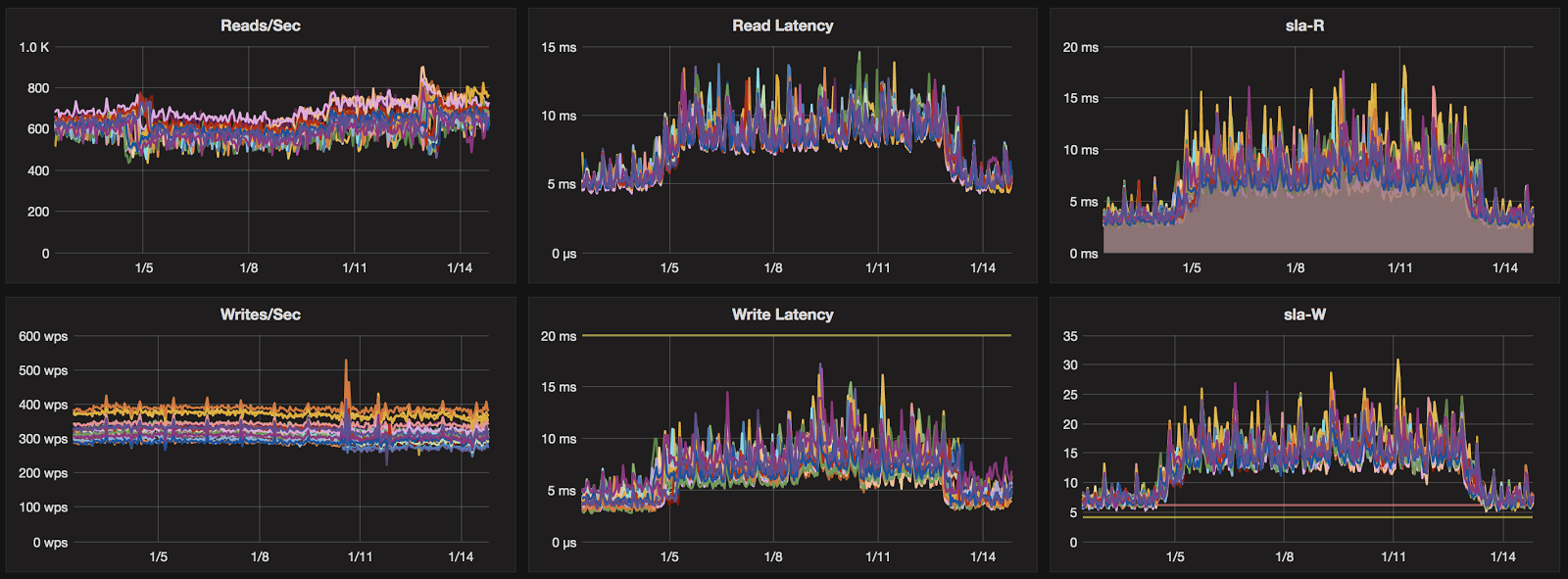
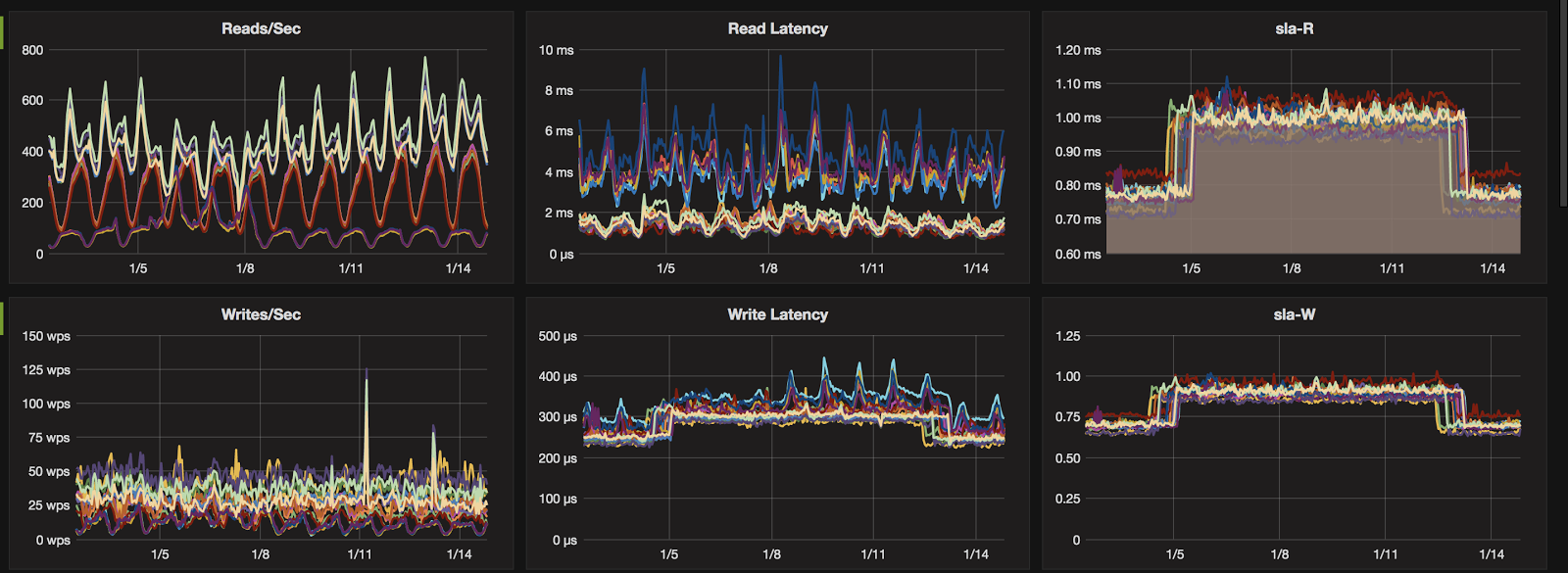
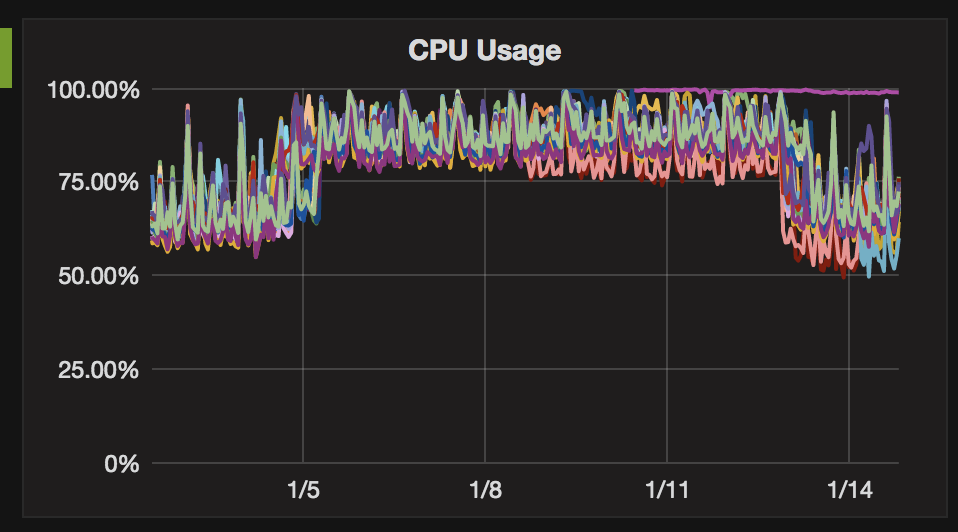
Sample clusters showing latency and cpu impact of initial cloud provider Hypervisor patch, and subsequent return to baseline performance levels.
Benchmark testing results
All tests were executed twice. In all cases, both rounds showed no noticeable performance impact from Container Linux patches.
The final findings are displayed below:
M4.xlarge (AWS)
Before:
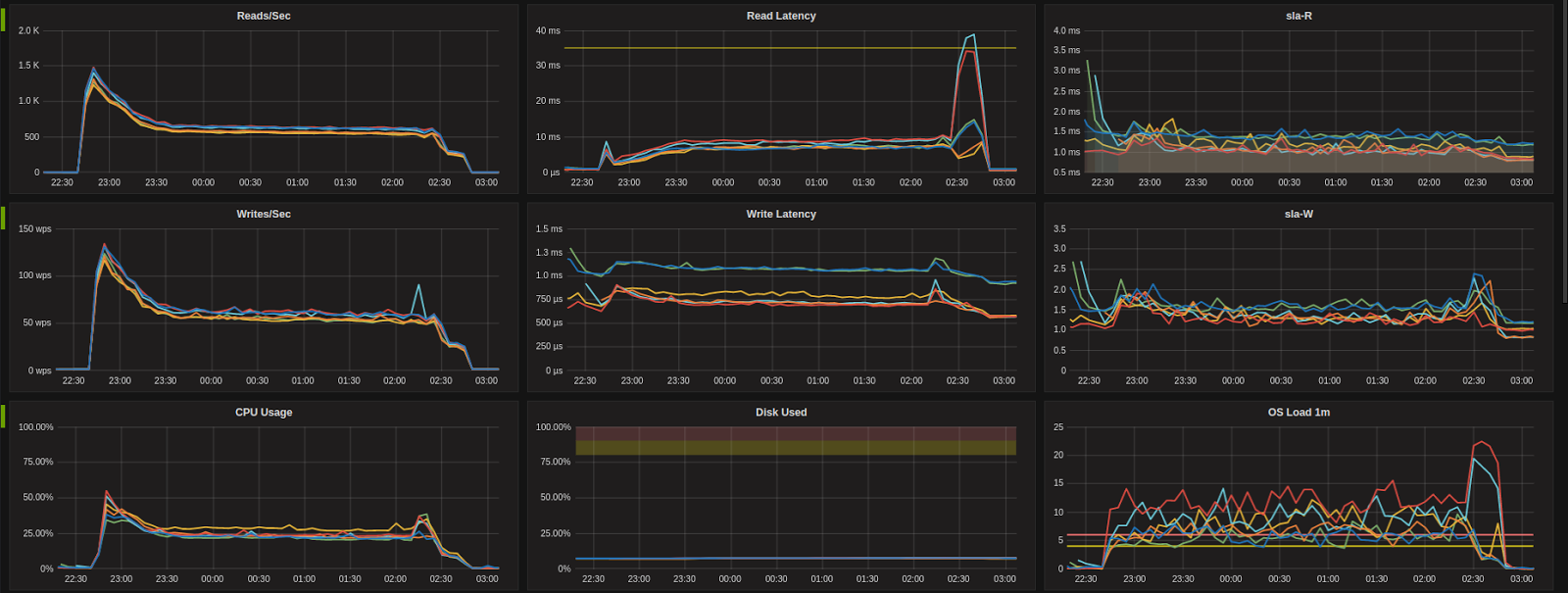
After:
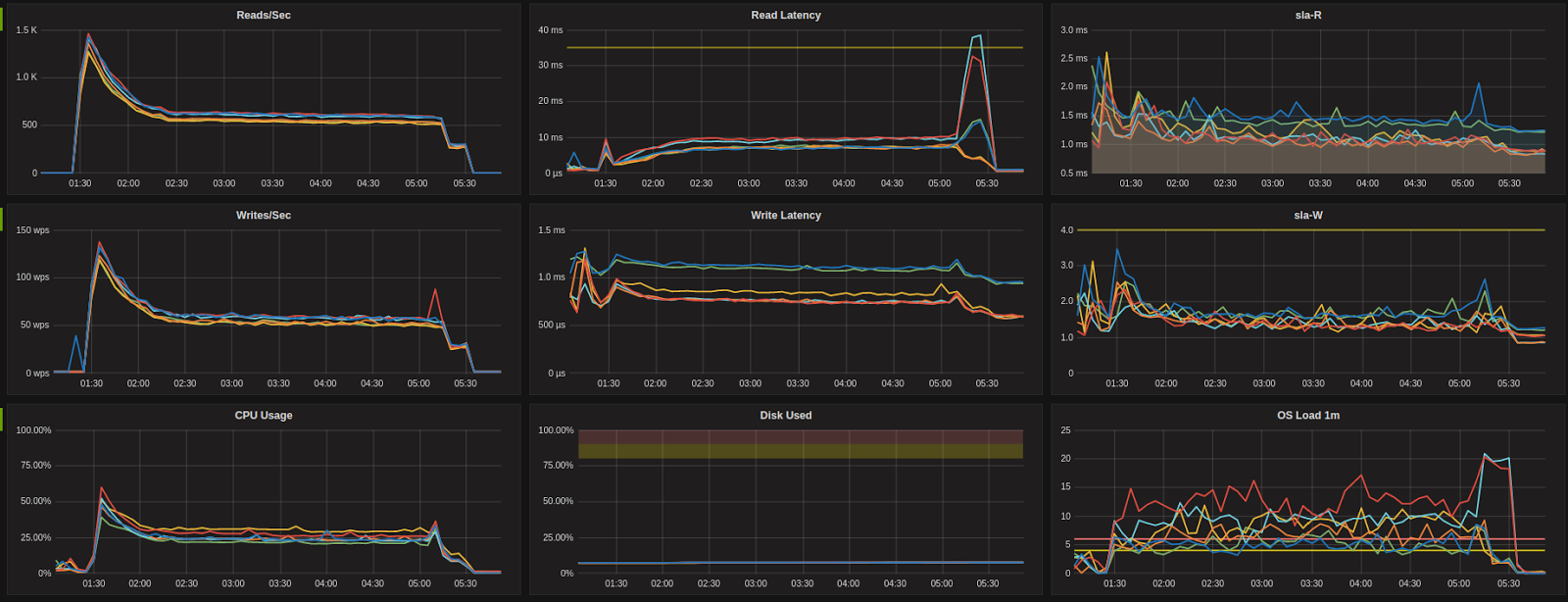
R4.large (AWS)
Before:
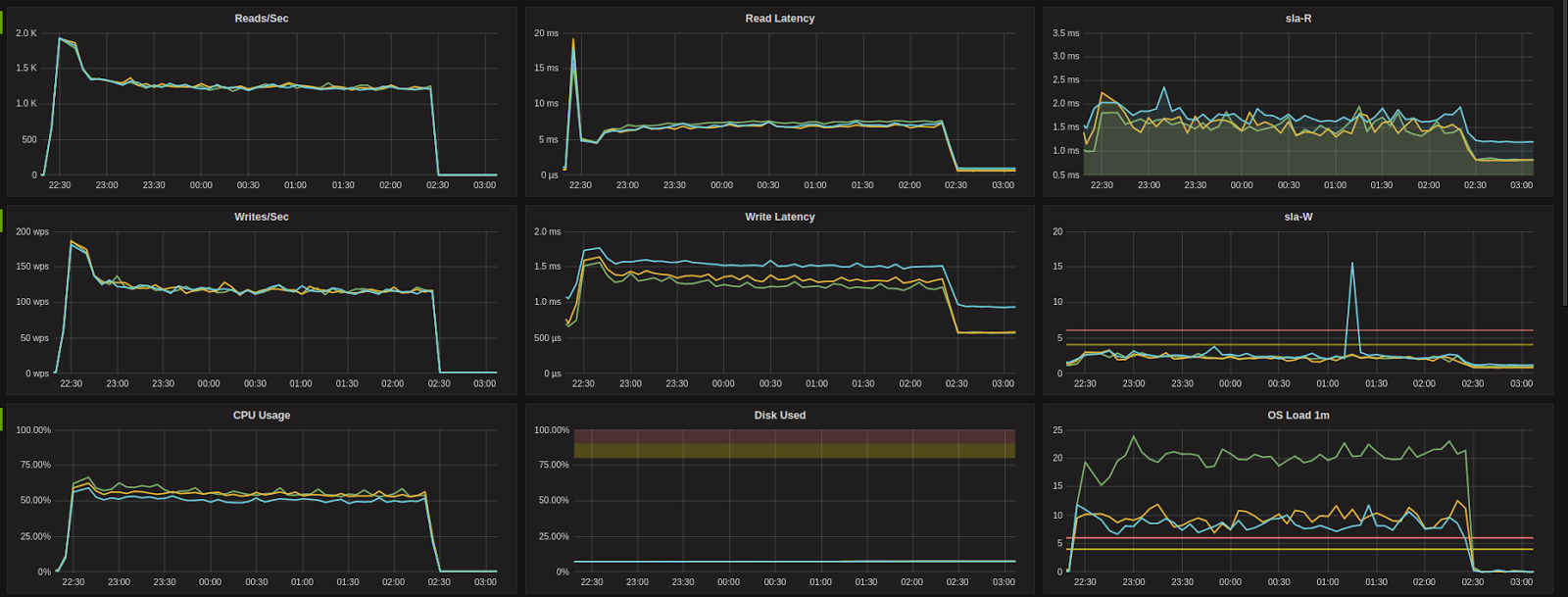
After:
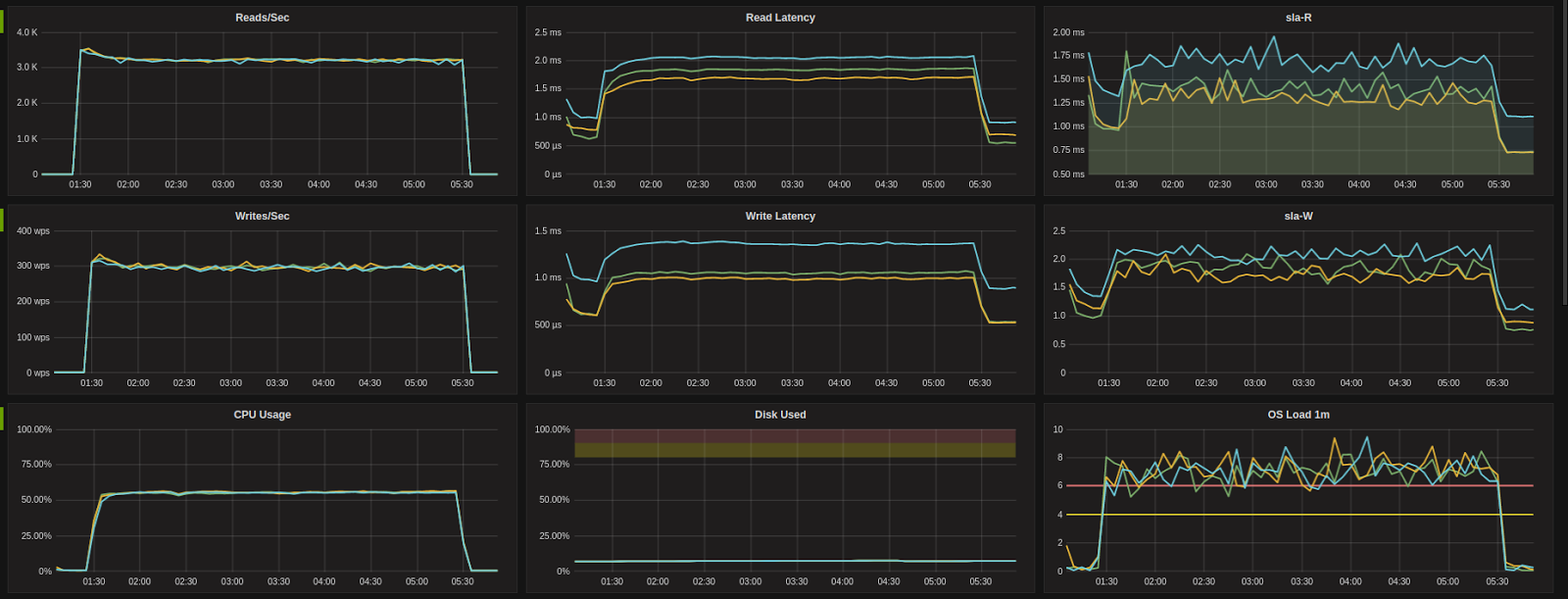
I3.2xlarge (AWS)
Before:
After:
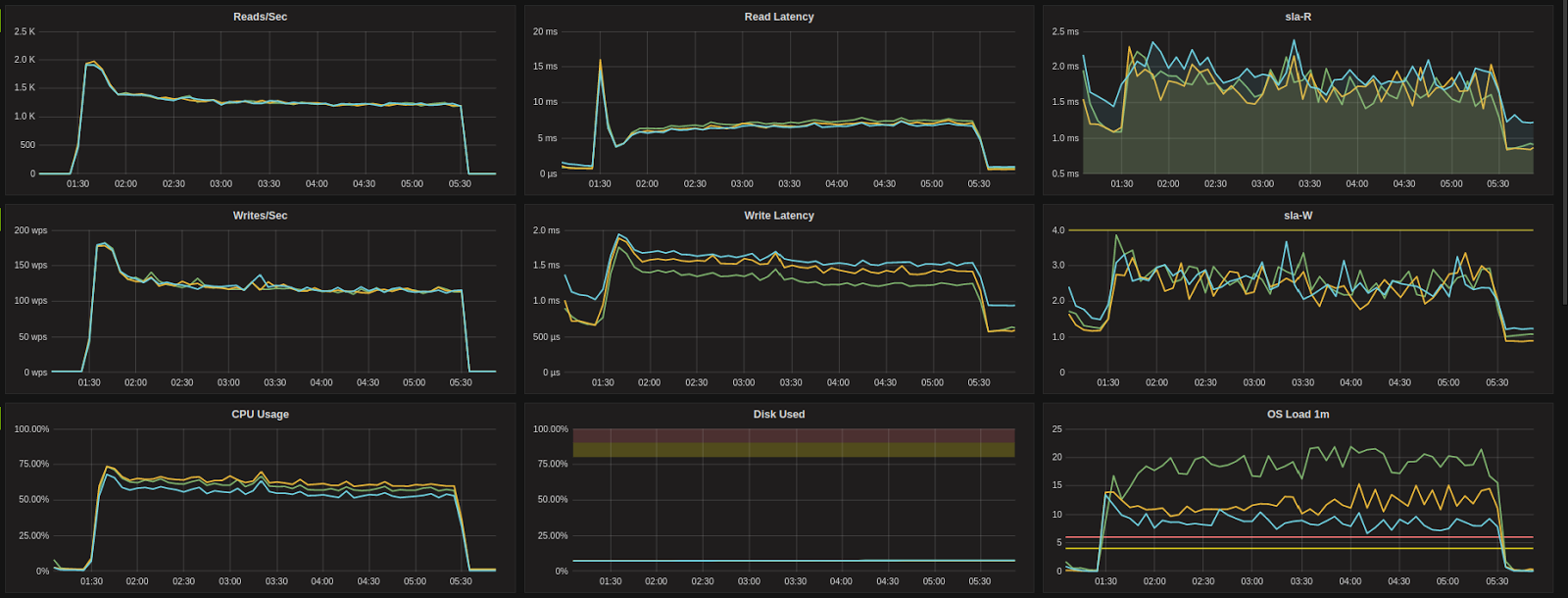
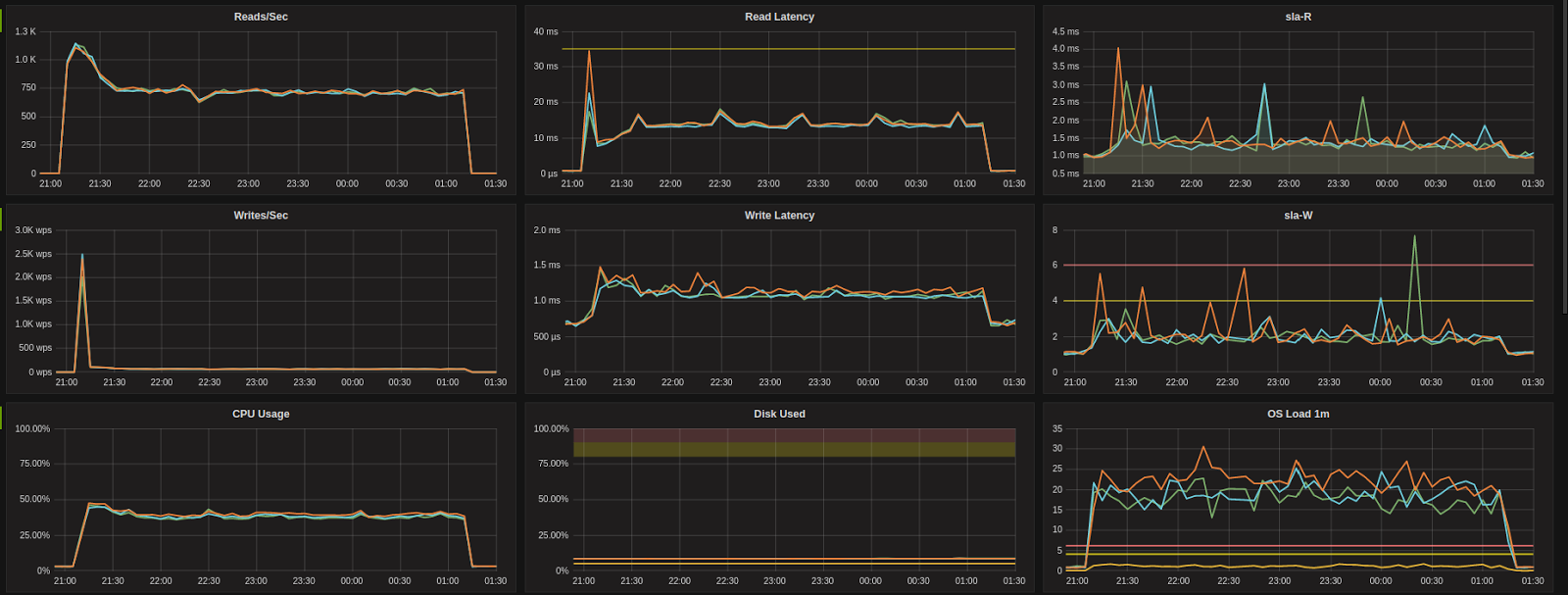
DS12-V2 (AZURE)
Before:
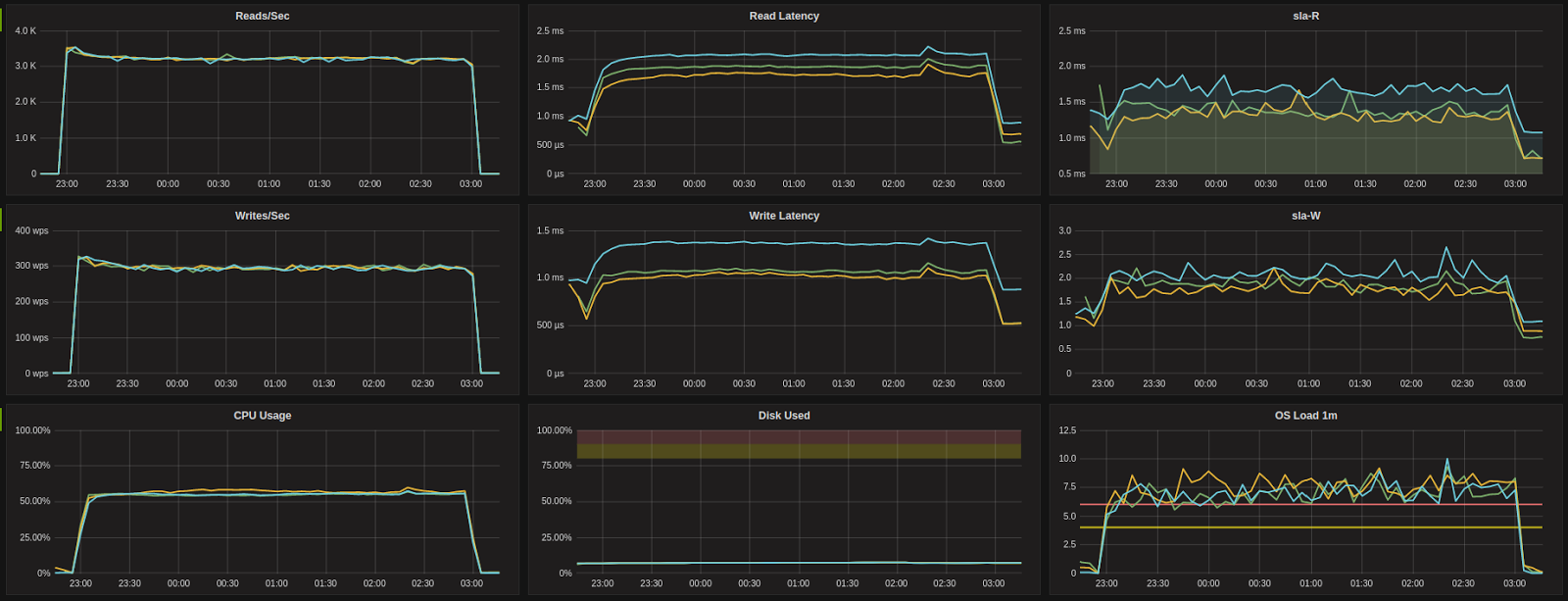
After:
Next steps
Instaclustr will be applying container operating system upgrade (Container Linux v1576.5.0) to all nodes in the fleet over the next two weeks. The OS upgrade will be completed without cluster downtime, but will require a rolling restart of each cluster.
Plan out OS upgrades
Where possible we will upgrade non-production clusters first. For customers hosting a Development and/or Test environment with us in addition to Production, we will work with those customers to upgrade the lower environments and allow 1 week for testing prior to upgrading Production clusters.
Advise and upgrade
We will be upgrading the underlying OS of all nodes over the next two weeks. We will provide updates on progress on https://status.instaclustr.com. The OS upgrade will be completed without downtime, but will require a rolling restart of each cluster.
If you wish to discuss scheduling of the upgrade to your system or have any other questions about these test results or the impact of these patches, please contact [email protected].
Should you have any questions regarding this patch, please contact us by email [email protected].