Apache Kafka provides developers with a uniquely powerful, open source and versatile distributed streaming platform – but it also has some rather complex nuances to understand when trying to store and retrieve data in your preferred order.
Kafka captures streaming data by publishing records to a category or feed name called a topic. Kafka consumers can then subscribe to topics to retrieve that data. For each topic, the Kafka cluster creates and updates a partitioned log. Kafka sends all messages from a particular producer to the same partition, storing each message in the order it arrives. Partitions, therefore, function as a structure commit log, containing sequences of records that are both ordered and immutable.
As Kafka adds each record to a partition, it assigns a unique sequential ID called an offset.
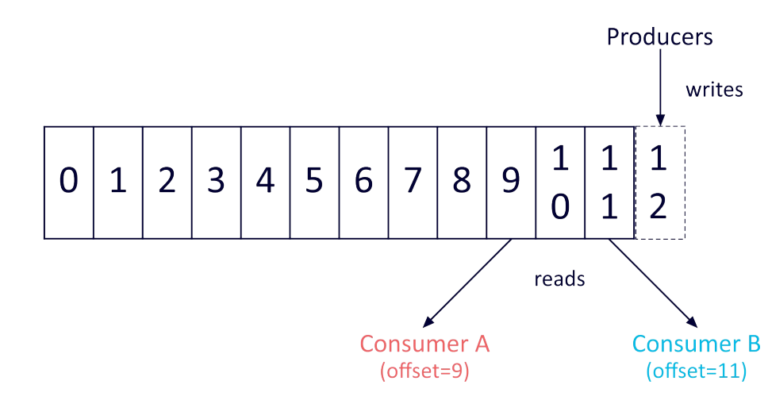
Because Kafka always sends real-time data to consumers in the order that it was stored in the partition, retrieving data from a single partition in your preferred order is simple: all you have to do is store it in the order you’d like it in the first place. But Kafka makes things significantly more complicated by not maintaining a total order of records when topics have more than one partition.
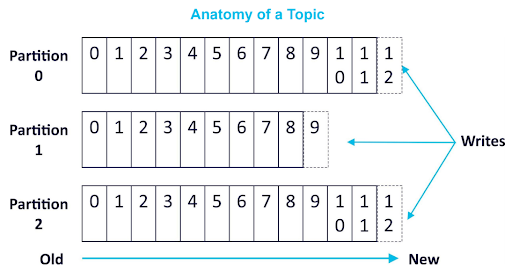
If your application requires total control over records (and being limited to a single consumer process per consumer group is no problem), using a topic with just one partition might be your best solution. For most applications that level of control isn’t necessary, however, and it’s better to use per-partition ordering and keying to control the order of retrieved data.
Using Kafka Partitioning and Keying to Control Data Order
The following example demonstrates the results of storing and retrieving data in multiple partitions.
To begin, let’s make a topic called “my-topic”, that has 10 partitions:
 Now let’s create a producer, which we’ll have send the numbers 1 to 10 to the topic in order:
Now let’s create a producer, which we’ll have send the numbers 1 to 10 to the topic in order:

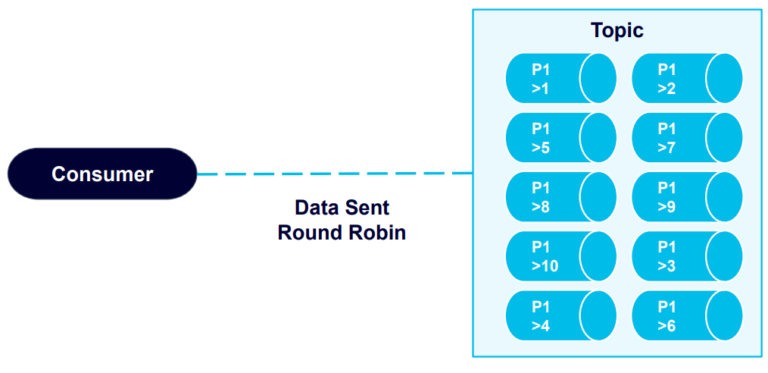
The topic stores these records within its ten partitions. Next, we’ll have the consumer read the data back from the topic, starting at the beginning:

The data is out of order. What’s happening is that the Kafka consumer retrieves the data in a round robin fashion from all ten partitions:
Let’s switch to a new example, where we create a topic with a single partition:

And send the same data, 1 to 10:

Now when we retrieve the data, it remains in the order that it was originally sent:
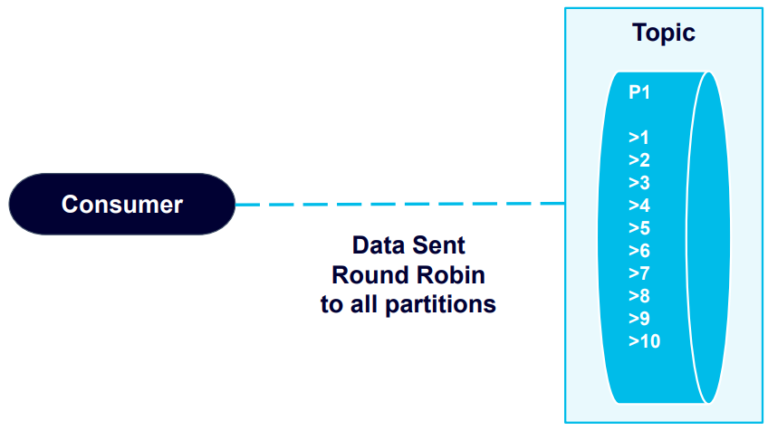
This example proves that Kafka will in fact guarantee data order within partitions.
Now let’s explore how to use keying by adding keys to producer records. We’ll create four messages, each including one of four different keys (in our example: Costco, Walmart, Target, and Best Buy), and send them to a topic with two partitions:
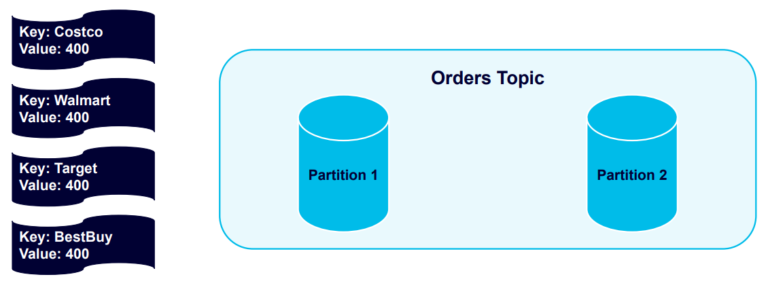
The four keys are hashed and distributed evenly into the partitions:
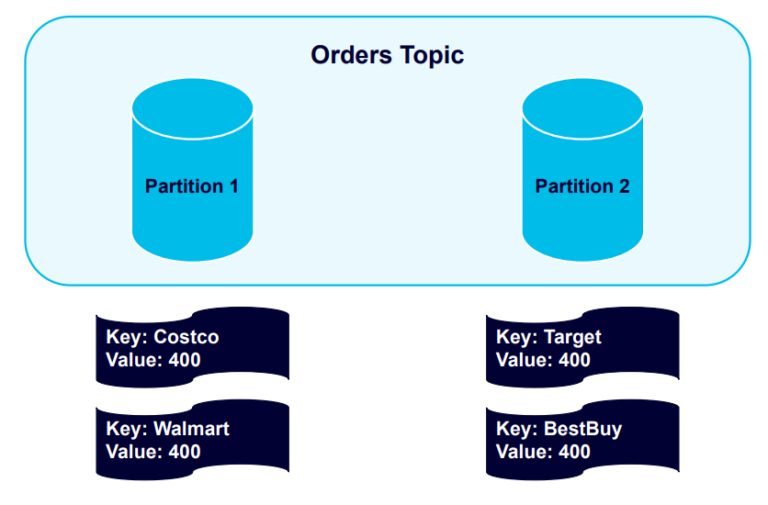
Let’s see what happens when we send four more messages, using the same keys:
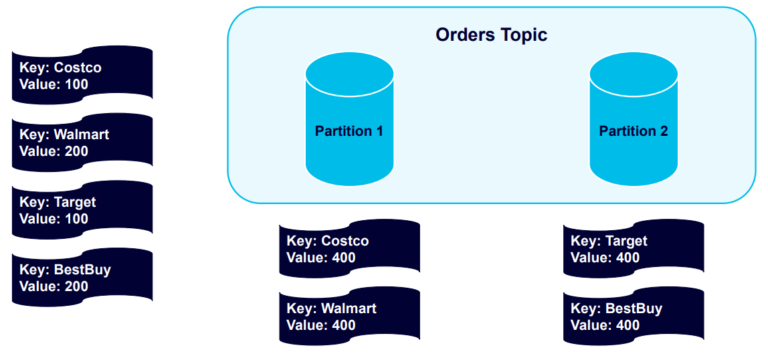
Kafka sends all further keyed messages to the partitions using those keys:
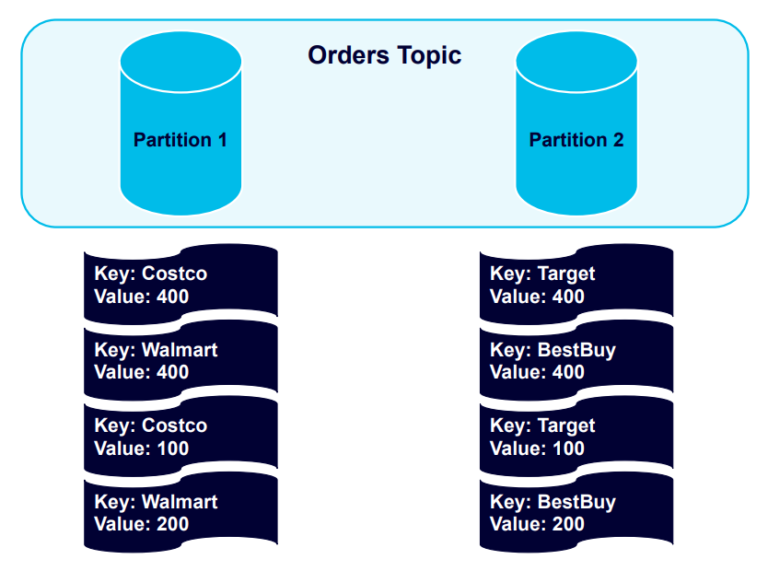
The records are stored in the partitions in the order they were sent.
Now we’ll add more partitions to the cluster, which can offer a healthier balance of data across partitions:
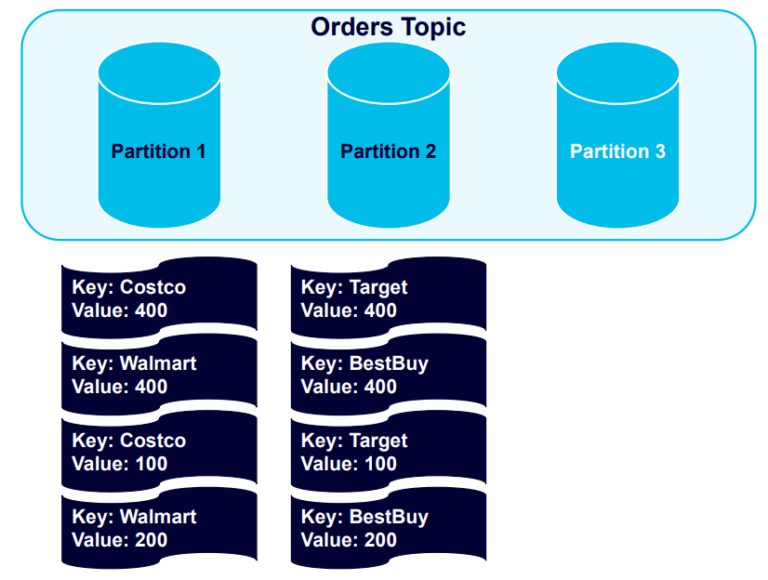
Triggering a rebalance event will then redistribute the records across the partitions:
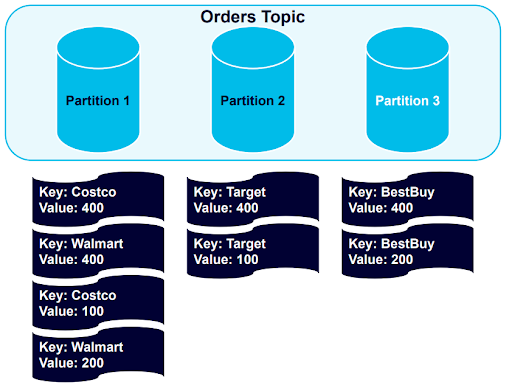
As we can see, all records with the Best Buy key have been balanced to Partition 3, and the data is otherwise still nicely structured by key. We’ll demonstrate this further by adding four more messages:
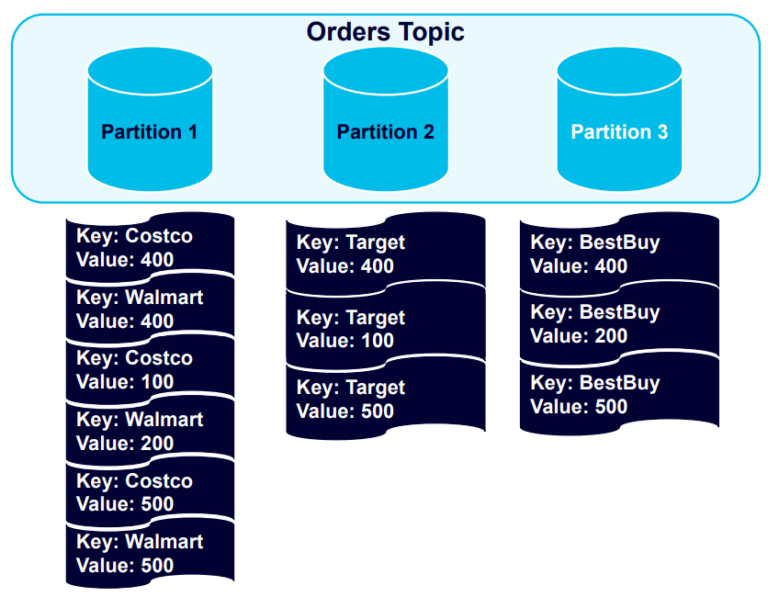
New records are organized into partitions according to their keys. Given that we have four keys and the partitions our unbalanced, it’s logical to add another partition and trigger a rebalance:
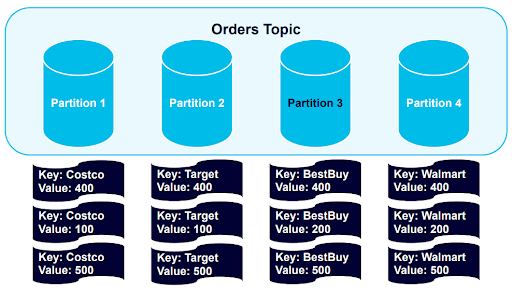
The data sets, partitioned by key, are now in a healthy balance.
How to Make Sure Kafka Always Sends Data in the Right Order
A number of circumstances can lead to Kafka data order issues, from broker and client failures to reattempts at sending data leading to errors. Dealing with these issues requires a thorough understanding how the Kafka producer functions.
Here’s an overview:
Download our free eBook: Apache Kafka – A Visual Introduction, to learn the fundamentals of Kafka in a fun way.
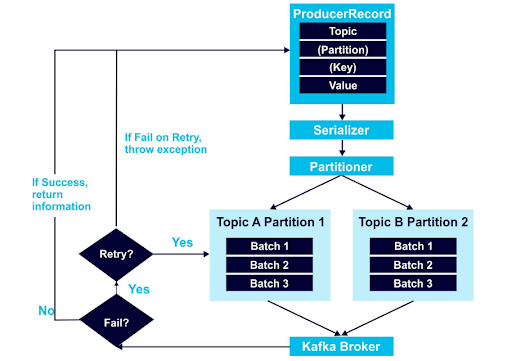
A ProducerRecord object includes the topic where the data should be sent, and the data value. Optionally, it can also include an assigned partition to use, and a key. I recommend always using keys to organize data, as demonstrated in the examples above.
As you can see in the diagram, ProducerRecord data is encoded with the Serializer. After that, the Partitioner algorithm figures out where the data should go, and sends it to the Kafka Broker. Next is the Kafka retry mechanism, a frequent origin of data order issues.
These issues occur in scenarios like this:
You try to send two records to Kafka. One is sent successfully, but a network issue causes the other to fail. You try to resend the data, but now you have two active requests at the same time, creating the possibility that the data will be stored out of order.
The solution is to set Kafka’s max.in.flight.requests.per.connection parameter to 1. When this is set higher than one, and the retries parameter is above zero, the broker can fail at writing the first message batch but succeed at the second that was in-flight at the same time, then retry and succeed at writing the first message (switching their stored order). By setting max.in.flight.requests.per.connection to 1, you can make sure those requests are completed sequentially, in your intended order.
If data order is absolutely critical to your application, I also recommend setting in.flight.requests.per.session to 1. This tells Kafka not to send any other messages until the current message batch is complete. However, this technique comes with severe costs to producer throughput and is only appropriate for use cases where data order is crucially important. Also, beware of the temptation to set allowed retries to zero; doing so has a devastating effect on system reliability.
How to Leverage Exactly-Once Message Delivery
There are three different methods for delivering messages in Kafka, each offering unique behaviours:
- At-Once Message Delivery – Delivers a message batch a single time, or not at all. This method will never create issues associated with resending messages (because it doesn’t) but might let messages be lost.
- At-Least-Once Message Delivery – Never gives up until a message is delivered. This guarantees a successful delivery but allows for the possibility that a message will be delivered more than once.
- Exactly-Once Message Delivery – Ensures that each message is delivered a single time. This method involves extra steps to guarantee a singular successful delivery, even as failures and retries occur.
For the task of maintaining data ordering, Exactly-Once Message Delivery is the right choice.
Components Required to Implement Exactly-Once Message Delivery
Exactly-Once Message Delivery relies on these three components: an idempotent producer, transactions across partitions, and a transactional consumer. Let’s explore.
1) Idempotent producer
Activating producer idempotency ensures that messages last only for a single delivery process, eliminating issues with retries. With idempotency, each Kafka message gains a producer ID (PID) and a sequence ID. If there’s a failure in the broker or client that triggers a retry, the topic will only accept messages including PIDs and sequence IDs it hasn’t seen before. At the same time, the broker goes further in guaranteeing idempotency by automatically deduplicating all messages sent by the producer.
2) Transactions across partitions
Apache Kafka version 0.11 introduced a transaction coordinator, and a transaction log that maintains the state of atomic writes. Using transactions, it’s possible to transform and atomically write a message to multiple topics or partitions and use an offset to track if the message is consumed. Thus, we can ensure that each message is processed just once.
Each producer is assigned a transaction coordinator (much like the consumer group coordinator), which assigns PIDs and manages transactions. The transaction log functions as the state store for the transaction coordinator, maintaining a persistent record of all transactions.
3) Transactional Consumer
Last but not least, we need the transactional consumer to only read committed data. To force this, set the isolation.level parameter to read_committed (it’s set to read_uncommitted by default).
The 10-Step “Exactly-Once Message Delivery” Kafka Transaction Workflow
This diagram and workflow steps demonstrate the data stream processing of successful Exactly-Once Message Delivery:
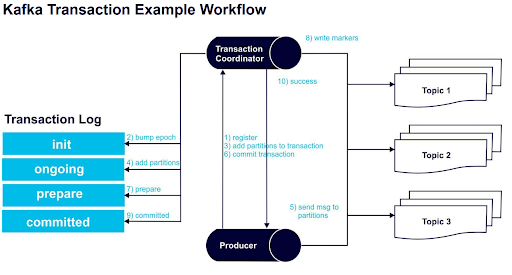
The 10 steps:
- Kafka uses initTransactions() to register a transaction ID – a unique and persistent producer ID – with the transaction coordinator.
- The epoch of the PID is bumped up by the coordinator to make sure that only one legitimate producer instance is active, and writes from previous PID instances aren’t accepted.
- The producer adds a new partition with the coordinator, then sends data to the partition.
- The coordinator stores the state of each transaction into memory and writes it to the transaction log.
- Messages are sent to the partitions by the producer.
- The producer starts a commit transaction, triggering the coordinator to begin the two-phase commit protocol.
- Commit protocol phase 1 – the coordinator updates the transaction log to prepare the commit.
- Commit protocol phase 2 – the coordinator writes transaction commit markers to the topic partitions that the transaction involves.
- The transaction is marked committed by the coordinator.
- The Exactly-Once Message Delivery transaction succeeds.
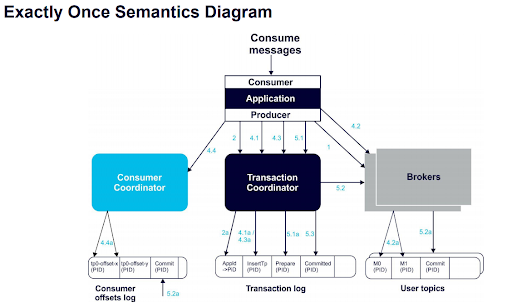
Here’s a more technical view of the architecture behind this process:
Now that you better understand how Kafka works and some effective methods for controlling data order, you can be confident developing applications with Kafka that are free from data order issues.
Transparent, fair, and flexible pricing for your data infrastructure: See Instaclustr Pricing Here
Streamline your Kafka deployment with Instaclustr’s Kafka managed service. Contact us today to discuss a solution for your application.