






















If you’re in database administration, chances are you’ve faced an age-old question: is it better to become slightly proficient in lots of different database tools, or become very proficient in one tool that can do a bit of everything reasonably well?
I have been a software engineer for over 35 years, and have been privileged to be a part of the PostgreSQL community for over 20 years. I have never regretted the decision to join forces with thousands of entrepreneurs and geniuses that make up the PostgreSQL community. For the first 15 years, I worked with 7 or 8 databases. For the last 20, I’ve never had to learn a new database technology, because PostgreSQL always gets me where I need to go.
In this blog post, I’ll explore the value of PostgreSQL for database administration and explain why you should learn it if you are pursuing a career in this field.
What is Database Administration?
Database administration is the practice of storing and protecting data. For years, this practice labored in obscurity as a sub-function of application development or an also-ran of operations management. In the modern world of electronic everything, enterprise organizations are beginning to understand that data is the lifeblood of organization management. As the awareness of data analysis improves, the market understanding of the importance of data is improving at an astounding rate. Database administrators are now considered a vital role in the service delivery pipeline. They are also being given a much louder voice in the role of operations. In order to perform this critical function of data storage and protection, database administration has grown to include many tasks:
- Security of data in flight and at rest
- Security of data at an application access level
- Redundancy of data for multiple consumers
- Availability of data through service stability
- Recovery of data in disaster scenarios
- Interpretation of data through defined storage
- Maintenance of data for cleanliness
- Archiving of data after retention policy has expired
- Acquisition of data from foreign systems
- Provision of data to applications
Where Does PostgreSQL Fit In?
The role of PostgreSQL in this market is as an open source Post-Object Relational Database Management System (PORDBMS). PostgreSQL has been available in the market for more than 25 years. In this time, it has grown to be a mature offering of data services. These services are produced by thousands of developers across the world.
For the moment, suffice it to say that you are not working in a vacuum here. So let’s go through that acronym one concept at a time and use it to define what PostgreSQL has grown to become.
P stands for post. As in after object relational in clock time. This refers to the advanced storage and interpretation features of PostgreSQL such as JSON and XML support, alternative storage engines, replication models, and enterprise management tools. For the last decade or so, the PostgreSQL global development community has been concentrating on the tool set surrounding PostgreSQL to make it a world class database ecosystem.
OR stands for object relational. This one is quite a bit more complex than you would imagine at first glance. The obvious reference is to the fact that the entities in the database (relations—tables, views, functions, etc.) are associated with one another through data references that are design dependent. In addition to that, the objects themselves may be used as base classes in an object-oriented programming sense. That is, a table may be defined using the definition of another table or a function may take a table definition as input and provide a different table definition as output. This rather unique implementation follows through to using built in data types as basis for your own custom data types, as well as constraint definitions.
DB stands for database. This is the core of the system which manages the data storage and retrieval layer. It is written in C, and it’s blindingly fast.
MS stands for management system The PostgreSQL service is a bit of a misnomer. It is actually several services working together to perform storage, retrieval, user management, caching, temporary storage, and several other tasks. It can grow to several hundred or even thousands of Linux processes, all requiring the coordination of a central service.
The modern enterprise stores data in many different systems, and in many different formats. These systems include data warehousing, reporting, operational data storage, single source of truth systems, extract transform load (ETL) systems, application support systems, and much more.
A quick definition of some of these systems:
- Enterprise Data Warehousing (DW or EDW) usually a large system designed to take data from many sources and use it to make business decisions across the entire enterprise. This data typically has the relational components condensed into non-relational facts and dimensions for data processing applications. Performance numbers, system health, and growth projections are derived from the decomposed data elements.
- Reporting typically a subset of the data in a warehouse that is dedicated to a particular consumer with nice charts and graphs to show key business metrics.
- Operational Data Storage (ODS) also called a “single source of truth”. A dumping ground for data across the organization to make fast operational decisions across teams in a live environment.
- Online Transaction Processing (OLTP) An operational system that performs a specific business function and uses data in row form. That is, a collection of data elements that defines a single object. OLTP systems are usually application specific.
- Extract, Transform, Load (ETL, ELT) intermediate systems that may be needed for data collection. These systems store data from many sources that could have conflicting data types and storage models. In order to make the data rational, some level of transformation may occur. This also includes data enrichment (such as adding a geographic point to an address), or data cleansing (such as ensuring that the address is a verified postal mail delivery point).
- Non-Relational this method began with storage systems such as NoSQL, Hadoop, Cassandra, Mongo, etc. which were designed specifically to store data without associating it to other data in the model. The retrieval language was also drastically simplified. This was seen as an optimization step for data retrieval. However, just because relational data models are available in PostgreSQL doesn’t mean that you are required to use them. These methods can be largely repeated in a PostgreSQL model without resorting to anything overly esoteric.
There are several forms of data storage available to target each of these system architectures. There is no particular requirement or enforcement from the database that these data storage structures must remain specific to the system for which they were conceived. That is, you may use any storage technique in any capacity that you choose. So it is very advantageous to learn all of the techniques for all of the storage systems, as you may run into them anywhere.
PostgreSQL is generally thought about as an open source database in a relational database context (it is included in the name after all). This tends to relegate it to OLTP systems. However, PostgreSQL has grown significantly over the years and can perform all of these functions (and much, much more) in some capacity, even the ones that are defined as non-relational (NoSQL, Hadoop, Mongo, etc.).
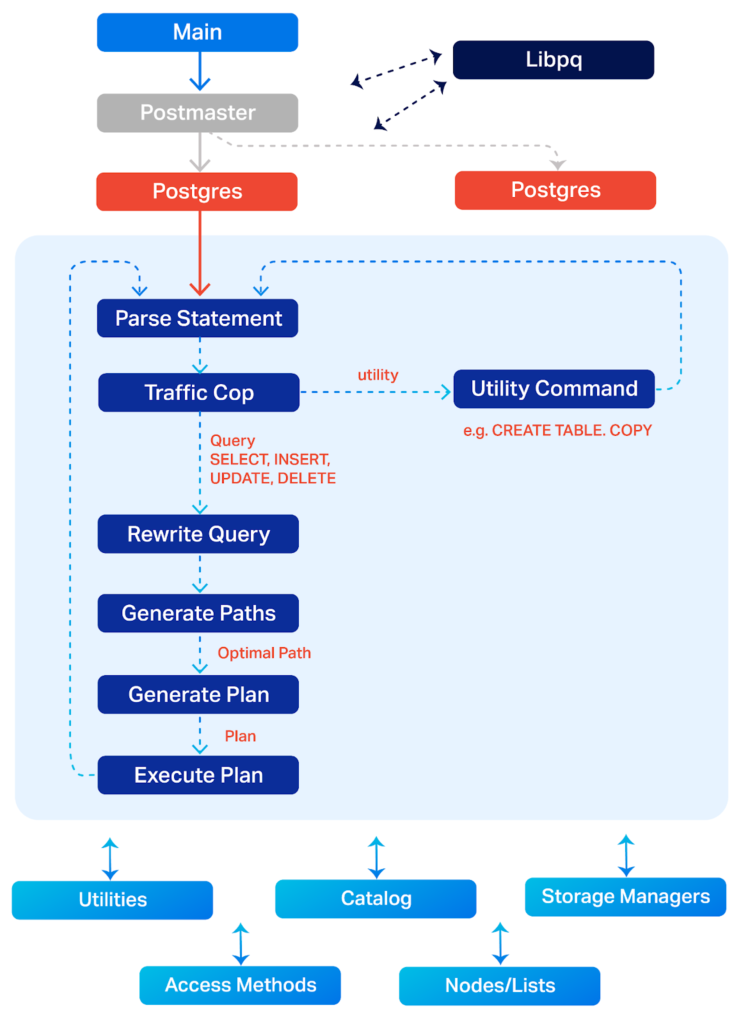
PostgreSQL architecture. Adapted from PostgreSQL documentation here: https://www.postgresql.org/developer/backend/.
The Pros and Cons of PostgreSQL
This brings us to a very hot debate in the database community. The question of whether it is more advantageous to retain all of the data in one system, or to separate the data by function into bespoke systems. And the answer is, well, both. Or maybe not. Or maybe neither. Kinda depends. Sorta. Mostly.
The question is usually very poorly asked and is therefore pretty poorly answered. To say that PostgreSQL is just for OLTP is to undersell its abilities to the point of libel. But to say that it can do everything is also a bit overstated. To ask the question in a bit better understanding, it would look like: “At what architectural point should I begin separating my data into scalable services?”
First let’s dive into the “eggs all in one basket” advantages and disadvantages. For starters, the data is stored with consistency at the transaction level. That is, you won’t get one version of a row from one source, and a different row from another. All changes are reflected across the system in coherence with one another. The second big advantage is one of high availability configuration.
The more systems you split the data into, the more of them you have to have disaster plans and operational procedures for. One system equals one procedure plan. Much simpler. Also, a single system is easier to monitor. What happens if one part of a multipart service goes down? Is the system available or not? If there is only one system, then there is no difference of interpretation.
Do you really want to support multiple database types? Really? With one administrator or with several? Are the database administrators going to be separated by service or by skills? How many other pieces of architecture have to be designed to go with that? Load balancing, connection pooling, connection concentrators, DNS, caching, etc.? Creating a data services layer based on many data storage types can become overwhelmingly complex very quickly.
Now for the opposite point of view. The advantages to decentralization are that multiple services can be tuned independently for performance. Growth can be maintained for the largest growing service without having to upgrade everything. External utilities can also be sized appropriately to service. Performance is usually improved and diagnostics become divided by service making issues in flight easier to locate and diagnose.
Whether or not you go with one architecture or the other also depends a lot on the skill set of the implementation team. A “one-man-show” might want to keep the disaster recovery and high availability plans as simple as possible. More skills and more available time make more complex configurations realistic.
PostgreSQL Does Everything. Kinda.
So this brings us to the final form of the question: “At what point is it appropriate to separate the services?” And that answer lies with your specific data usage pattern. That is, PostgreSQL is a vertical scalability model by design. There can only be one system receiving changes to data at a time. This limitation determines the maximum number of transactions for your application that PostgreSQL will allow.
As you approach 60% of that limitation, you should start planning for multiple databases, whether they are also PostgreSQL or not. At about 80% of capacity, you should execute that plan. The plan is to stay in the single system solution as long as possible, but have a plan to get out of it if you outgrow it. The vast majority of systems will never outgrow the single system. This is an experience value, but after 24 years of PostgreSQL experience, it seems to be a pretty safe one.
After all that, this discussion was to determine which solutions fit in the PostgreSQL box. The answer to that question is all of them, to a point. And some of them still fit after that point. By the time you get there, which ones are appropriate will become apparent.
Looking for 24/7 Expert Support for PostgreSQL? Get in Touch!
Design Doesn’t Include Optimization
Please don’t succumb to the error of premature optimization at the database level. This is a concept borrowed from software development, where a developer tunes a function or service for theoretic scalability, but then in practice the actual data patterns don’t work out the way the developer imagined. This leads to wasted time and effort put forth in the initial coding effort, that is later thrown in the trash when the real usage pattern appears or the requirements change.
The database development version of this is to agonize over scalability without a usage pattern. Just design what the diagram calls for, and leave it at that. When the data comes in, there are methods to scale in flight that are very effective for a very long time. When you see a pattern emerge, design towards it.
This also includes index design. Useless indexes in PostgreSQL are costly. Don’t just throw indexes at every likely column and hope for the best. It won’t be the best and can be worse than nothing at all.
Optimization Doesn’t Include Design
PostgreSQL is best tuned using actual data in the field, at size. By that I mean that the PostgreSQL query engine considers indexes, partitions, and other elements with sizes. A small table that fits in memory may not need any indexes at all, and a large one may not profit from them. It is all firmly engraved in Jell-O, and depends largely on the traffic pattern.
This is an advanced skill that requires some observation time in the field to adjust. The good news is that these adjustments can be made to a running system with minimal impact to service delivery. They are designed that way because the engineering model of PostgreSQL architecture requires it to be so.
PostgreSQL Use Cases Are Growing
Use cases for PostgreSQL are growing exponentially over time. That is, the number of applications that PostgreSQL can target is becoming greater as time goes by, and (more importantly) the number of applications that it can’t target is going down.
Two decades ago, it would have been reasonable to say that PostgreSQL was appropriate for OLTP solutions with a few megabytes of data. Now that target market includes OLTP, ETL/ELT, OLAP, ODS solutions, and much more. Now, it is easier to say what kind of applications PostgreSQL does **not** target, such as seismic data processing or the NYSE. But these corner cases are becoming fewer and fewer, almost to a vanishing point.
As PostgreSQL use cases grow, so do the professional opportunities for those who take the time to learn it. If you’re in development or database administration and haven’t yet learned PostgreSQL, this is an exciting time to dig in and see what it can do for your projects (and your career).