What is an OpenSearch cluster?
An OpenSearch cluster is a group of nodes that work together to share data and provide high availability, improved performance, and horizontal scalability. It provides the infrastructure for information retrieval services, where nodes distribute tasks and manage data to ensure seamless querying and indexing.
In a cluster, each node plays a defined role, such as managing metadata, storing data, or balancing the load across the cluster. This distributed design allows OpenSearch to maintain performance and reliability even under heavy workloads. A cluster’s resilience is augmented through features like data replication and automatic recovery from hardware failures.
The cluster’s distributed nature allows it to handle larger volumes of data than a single server could manage. It achieves this by spreading tasks and data across multiple nodes, ensuring no single point of failure. By enabling horizontal scalability, OpenSearch clusters support efficient data retrieval and processing, accommodating growing user demands.
Tutorial: Creating your first OpenSearch cluster
This tutorial provides step-by-step instructions for creating and configuring an OpenSearch cluster, focusing on a multi-node setup. The steps include naming the cluster, setting node attributes, binding IP addresses, configuring discovery hosts, and starting the cluster.
Prerequisites
Before beginning, ensure OpenSearch is installed and configured on all nodes. You can follow the official OpenSearch installation guide for detailed instructions. Use SSH to connect to each node and locate the config/opensearch.yml file, where most cluster configurations are specified. This tutorial assumes you have administrative access to the servers and a basic understanding of networking.
Step 1: Name the cluster
The cluster name serves as an identifier, especially when running multiple clusters on the same network. By default, OpenSearch uses opensearch as the cluster name. To set a custom name:
- Open the
opensearch.ymlfile located in theconfigdirectory on each node. - Locate the line starting with
#cluster.nameand uncomment it. - Replace the default value with a descriptive name:
1cluster.name: opensearch-cluster
- Ensure all nodes in the cluster share the same name to prevent them from forming separate clusters.
- Save the file and repeat the process for every node.
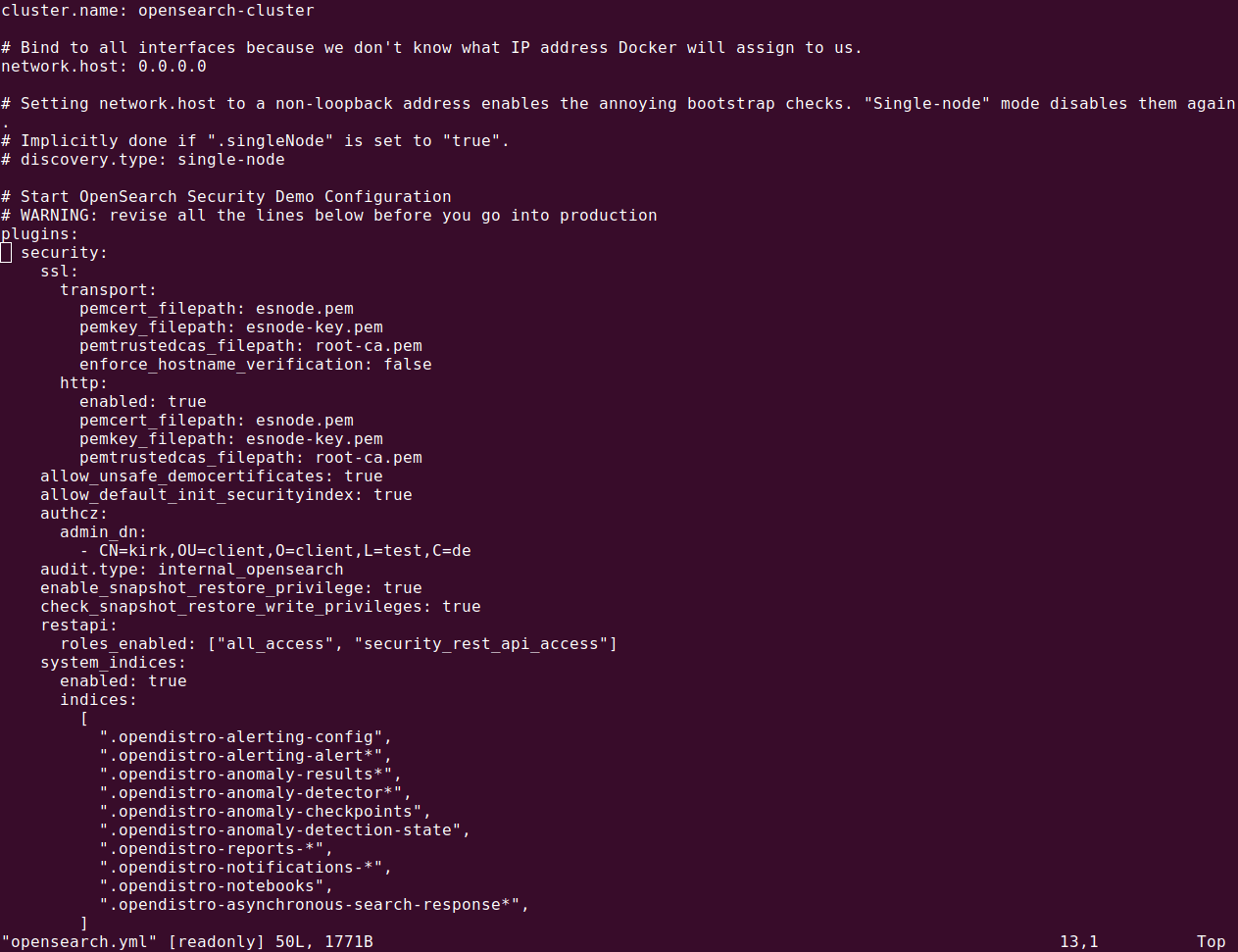
Step 2: Configure node roles
OpenSearch clusters typically include nodes with specific roles to optimize performance and reliability. You can define roles by modifying the node.name and node.roles settings in the opensearch.yml file.
Cluster manager node
The cluster manager node oversees cluster-wide metadata and manages node coordination:
|
1 2 |
node.name: opensearch-cluster_manager node.roles: [ cluster_manager ] |
Data nodes
Data nodes handle indexing and search requests. For this tutorial, designate two nodes as data nodes:
|
1 2 |
node.name: opensearch-d1 node.roles: [ data, ingest ] |

Coordinating node
The coordinating node distributes client requests to other nodes without storing data or metadata. Assign a node as a dedicated coordinating node by setting node.roles to an empty array:
|
1 2 |
node.name: opensearch-c1 node.roles: [] |
This ensures the node functions solely as a request distributor.
Step 3: Bind nodes to IP addresses
To enable communication between nodes, configure the network.bind_host setting. By default, OpenSearch binds to the local loopback address, restricting the cluster to a single node. To allow multi-node clustering:
- Open the
opensearch.ymlfile on each node. - Add or modify the
network.bind_hostsetting with the node’s IP address:1network.bind_host: <node-ip-address> - Replace
<node-ip-address>with the actual IP of the node. Alternatively, use predefined values like_local_for loopback addresses or_site_for site-local addresses. - Save the file and repeat the process for each node in the cluster.
Note: For clusters created using Kubernetes and/or Docker, the above solution may not be applicable, because IP addresses are dynamic and assigned at runtime.
Step 4: Configure discovery hosts and initial cluster manager nodes
Node discovery is critical for forming a cluster. OpenSearch uses the discovery.seed_hosts setting to locate other nodes and initiate cluster formation.
Update the opensearch.yml file on each node with the following:
|
1 2 |
discovery.seed_hosts: ["<ip-d1>", "<ip-d2>", "<ip-c1>"] cluster.initial_cluster_manager_nodes: ["opensearch-cluster_manager"] |
Note the following:
- Replace
<ip-d1>,<ip-d2>, and<ip-c1>with the private IP addresses of the respective nodes. - The
cluster.initial_cluster_manager_nodessetting specifies the node(s) eligible to become the cluster manager during the initial election process.
Save the changes and ensure consistency across all nodes.
Step 5: Start the cluster
With the configurations complete, start OpenSearch on all nodes to initialize the cluster. Use the following command:
|
1 |
sudo systemctl start opensearch.service |
If OpenSearch was installed from a tar archive, you may need to manually create a systemd service. Refer to the OpenSearch documentation for instructions.
Step 6: Verify cluster formation
After starting the OpenSearch service on all nodes, verify that the cluster has formed successfully:
Check the logs to confirm node communication and cluster creation:
|
1 |
less /var/log/opensearch/opensearch-cluster.log |
Run the following _cat API query from any node to view cluster details:
|
1 |
curl -XGET https://:9200/_cat/nodes?v -u 'admin:' --insecure |
Example output
|
1 2 3 4 5 |
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role cluster_manager name x.x.x.x 13 61 0 0.02 0.04 0.05 mi * opensearch-cluster_manager x.x.x.x 16 60 0 0.06 0.05 0.05 md - opensearch-d1 x.x.x.x 34 38 0 0.12 0.07 0.06 md - opensearch-d2 x.x.x.x 23 38 0 0.12 0.07 0.06 md - opensearch-c1 |
Each node in the cluster, along with its role and state, should be listed.
Step 7: Advanced configuration (optional)
You can also opt to configure shard allocation awareness. This improves fault tolerance by distributing primary and replica shards across multiple zones.
- Add custom node attributes for zones:
12node.attr.zone: zoneA # On opensearch-d1node.attr.zone: zoneB # On opensearch-d2
- Update cluster settings to enable shard allocation awareness:
123456PUT _cluster/settings{"persistent": {"cluster.routing.allocation.awareness.attributes": "zone"}}
You can execute this command to see if node has been allocated to requested zone:
1curl -XGET "http://localhost:9200/_nodes?pretty"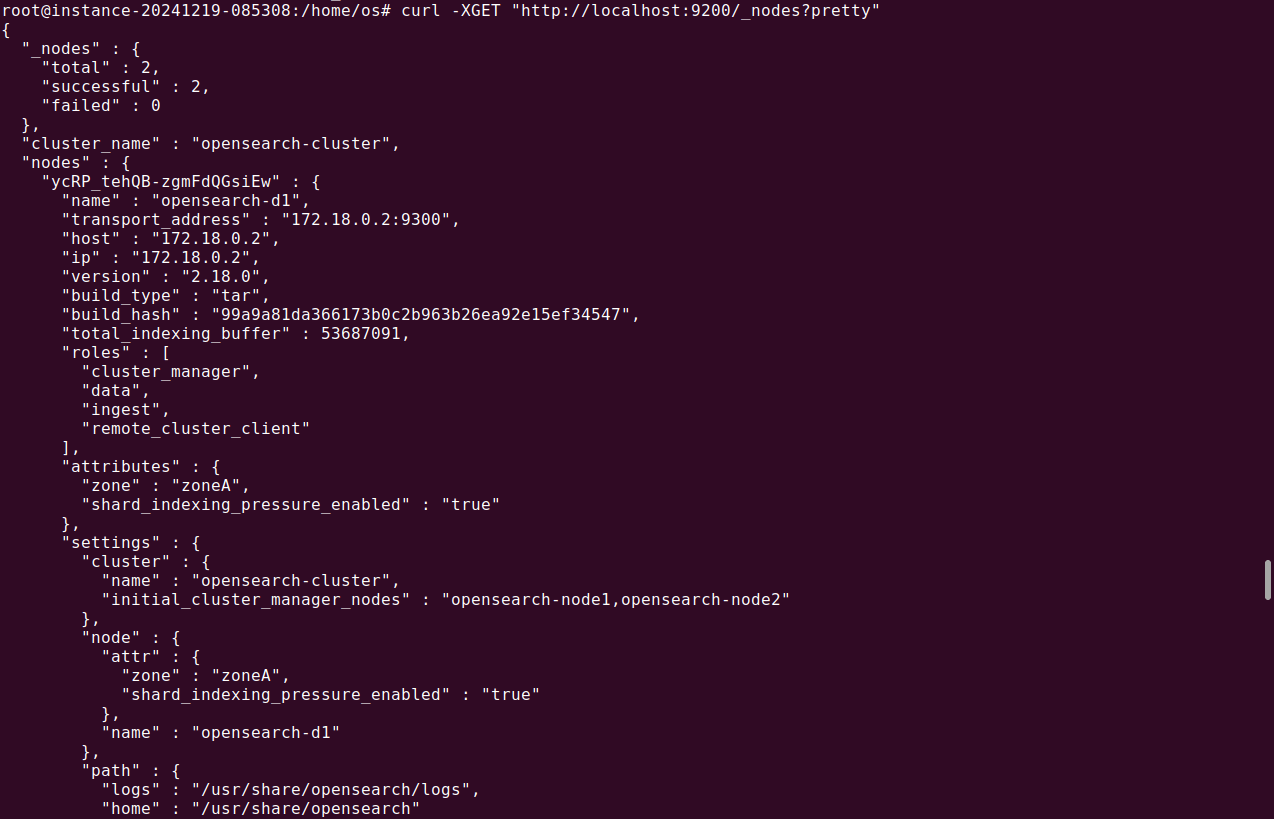
By following these steps, you’ve successfully created a multi-node OpenSearch cluster. This setup can be scaled or augmented with features like hot-warm architectures, forced awareness, or custom shard allocation strategies.
Related content: Read our guide to OpenSearch tutorial
Tips from the expert
Kassian Wren
Open Source Technology Evangelist
Kassian Wren is an Open Source Technology Evangelist specializing in OpenSearch. They are known for their expertise in developing and promoting open-source technologies, and have contributed significantly to the OpenSearch community through talks, events, and educational content
In my experience, here are tips that can help you better configure, optimize, and manage an OpenSearch cluster:
- Enable cross-cluster search for federated queries: If you manage multiple clusters, use cross-cluster search to allow querying across them without duplicating data. This enables unified analytics while keeping clusters optimized for specific workloads.
- Deploy hot-warm-cold architecture for tiered data storage: Separate nodes into tiers based on their purpose: hot nodes for real-time data, warm nodes for less frequently accessed data, and cold nodes for archival storage. This setup reduces costs while maintaining performance for critical operations.
- Implement snapshot lifecycle management (SLM): Automate regular backups of your OpenSearch indices using SLM policies. This ensures consistent data protection and simplifies recovery processes in case of failures.
- Utilize index lifecycle management (ILM) for data retention: Use ILM policies to automate index rollovers, deletions, or archival based on age or size. This keeps your cluster performant and compliant with data retention policies.
Best practices for OpenSearch clusters
Developers should be familiar with the following practices when working with clusters in OpenSearch.
1. Monitor cluster health regularly
Regularly monitoring cluster health is crucial to maintaining an OpenSearch environment’s stability and performance. This involves tracking various metrics such as node availability, shard status, and search performance, allowing users to detect and respond to issues promptly. Automated alerts can notify stakeholders of performance anomalies or failures.
By leveraging monitoring tools and dashboards, administrators can visualize data trends, predict potential bottlenecks, and undertake preemptive maintenance to mitigate risks. Real-time monitoring supports quick responses to emerging issues, reducing the impact of disruptions on the cluster’s performance.
Related content: Read our guide to OpenSearch dashboards
2. Optimize node roles for performance
Assigning roles based on hardware capabilities and organizational needs enhances efficiency, balancing loads across the cluster. For example, allocating more resources to data nodes can improve data retrieval times, while dedicating specific nodes to coordination functions can smooth client interactions with the cluster.
Effective role optimization involves assessing the unique requirements of the data environment and adjusting roles, such as designating cluster manager or coordinating nodes, to align with these needs. By fine-tuning node roles, admins improve resource allocation and cluster throughput.
3. Secure your cluster access
Implementing security measures such as role-based access controls (RBAC), encryption, and secure network configurations ensures that only authorized users can access and modify cluster settings. This starts with proper authentication protocols and extends to comprehensive auditing trails and monitoring to detect and mitigate unauthorized access attempts.
Encryption of data at rest and during transmission adds another layer of security, ensuring data remains protected from interception and unauthorized exposure. Regular security assessments and updates help mitigate vulnerabilities, ensuring the cluster remains resilient against the evolving threat landscape.
4. Regularly update OpenSearch versions
With each new release, developers provide enhancements, bug fixes, and critical security patches, addressing vulnerabilities and improving functionality. By staying current with updates, administrators ensure that their clusters benefit from the latest innovations and protections, mitigating risks associated with outdated software.
Continuous updates require developing a strategy to manage incompatibilities and downtime effectively. Testing new versions on staging environments before full deployment can help identify potential issues, ensuring smooth transitions. This proactive approach enhances cluster operations and extends its lifecycle.
5. Use shard allocation strategies efficiently
Aligning shard distribution with data types or access patterns can significantly influence search speeds and system loads, impacting the cluster’s overall efficiency. By implementing strategies such as balanced shard allocation or co-located shards, developers enhance redundancy and fault tolerance, improving the cluster’s ability to handle dynamic and diverse workflows.
The balance of shards across nodes prevents overloading individual nodes, thus maintaining consistent performance. Regular reviews of allocation strategies can adapt to growing or shifting data needs, ensuring the cluster remains effective.
OpenSearch on the Instaclustr Managed Platform: Experience the power of scalable search and analytics
Instaclustr for OpenSearch offers managed services that take the complexities of deploying and maintaining this robust platform off your plate. With expertise in open source technologies, Instaclustr ensures that your OpenSearch clusters are optimized, scalable, and always available, allowing you to focus on what truly matters: building great products and improving your customer experience.
Instaclustr for OpenSearch
When it comes to operationalizing OpenSearch, Instaclustr provides several key benefits:
1. Fully managed OpenSearch
Get end-to-end management for your OpenSearch deployment, including setup, scaling, monitoring, and routine maintenance. Stay focused on scaling your business while Instaclustr handles the grunt work of managing your platform.
2. High availability and scalability
Instaclustr ensures high availability with multi-node configurations that provide failover capabilities. Whether you’re running a small application or scaling to enterprise-grade workloads, Instaclustr helps your OpenSearch clusters grow seamlessly with your business needs.
3. Open source expertise
As a champion of open source technology, Instaclustr eliminates vendor lock-in and with the crucial benefit of transparent pricing. This commitment ensures that your OpenSearch deployment is always community-driven, independently audited, and aligned with the latest developments in the ecosystem.
4. World class support
Instaclustr’s focus on customer success means you receive 24×7 support from seasoned OpenSearch engineers. No chatbots; just real people ready to solve real problems and help you make the most of your investment.
5. Monitoring and optimization
Instaclustr doesn’t just manage your OpenSearch cluster—they actively monitor and optimize its performance. Advanced analytics and proactive alerts mean you’re always one step ahead when it comes to performance issues.
For more information see: