What is an open source data platform?
An open source data platform is a collection of tools and technologies for managing, analyzing, and visualizing data. The primary advantages of an open source approach are low costs and easier scalability, without having to buy licenses for each node or server. In addition, open source provides the freedom to customize and enhance the platform according to different needs.
Another attraction of open source data platforms is the broad community of developers and users who contribute to the continuous improvement of the software. Regular updates, security patches, and a range of plugins and integrations are often driven by community needs and technological advancements.
This is part of a series of articles about open source AI
Open source data platform architecture: Key components
These data platforms typically include the following components.
Data management system (DMS)
A Data Management System (DMS) is critical for storing, organizing, and retrieving data efficiently. Open source DMS options like PostgreSQL, MySQL, and Apache Cassandra enable organizations to handle large datasets with ease. They provide features like high availability, data integrity, and SQL compatibility, ensuring that data is always accurate and accessible.
These systems support basic CRUD (Create, Read, Update, Delete) operations, and they often come with advanced capabilities such as indexing, transaction management, and multi-threading. These features ensure that the DMS can handle complex queries and workloads without compromising performance.
Data integration (ETL)
Data integration through ETL (Extract, Transform, Load) processes brings together data from multiple sources into a unified repository. Open source ETL tools like Apache NiFi, Talend, and Airbyte provide scalable and flexible options for data extraction, transformation, and loading. These tools support a range of data sources, including databases, APIs, and file systems.
The transformation phase is crucial for maintaining data quality and consistency across the platform. ETL tools offer capabilities like data cleansing, normalization, and enrichment to ensure that the integrated data meets analytical or operational needs. Leveraging open source ETL tools also means access to a wealth of community-contributed connectors and plugins.
Data transformation
Data transformation involves converting raw data into a format suitable for analysis or reporting. Open source tools such as Apache Spark, dbt (data build tool), and Pandas in Python enable various transformation tasks, from simple data cleansing to complex aggregations and enrichments. These tools support both batch and real-time processing.
The primary goal is to ensure that data is accurate, consistent, and ready for downstream applications. Data transformation workflows can automate repetitive tasks, reduce human error, and increase efficiency. Open source solutions often include extensive libraries and frameworks that can be tailored to transformation needs, driven by community contributions that enhance functionality and address emerging use cases.
Data catalog and lineage
A data catalog serves as an inventory of data assets, while data lineage tracks the data’s lifecycle throughout the platform. Open source tools like Apache Atlas and Amundsen provide unified solutions for data cataloging and lineage. These tools help organizations manage metadata, making it easier to discover, understand, and govern data assets.
Data lineage is crucial for compliance and audit purposes, as it shows how data flows through different stages of processing. It helps in identifying the source of errors and assessing the impact of changes in data processing pipelines. Using open source data catalog and lineage tools ensures that these capabilities are continually refined and updated by a community.
Data visualization
Data visualization is the final step in the data pipeline, converting processed data into graphical representations for better interpretation and decision-making. Open source visualization tools like Apache Superset, Grafana, and D3.js offer features for creating interactive and shareable visualizations. These tools support various chart types and can integrate with other components of the data platform.
Effective visualization allows stakeholders to quickly identify trends, outliers, and patterns in the data. Open source tools often come with customizable dashboards and real-time analytics capabilities, providing dynamic insights into business performance.
Related content: Read our guide to open source databases
Top open source data platforms and tools
1. Apache Hadoop
![]()
Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It can scale up from a single server to thousands of machines, each offering local computation and storage. Hadoop has a large ecosystem of tools, including components such as HDFS for storage, MapReduce for processing, and tools like Apache Hive and Apache Pig for data analysis.
Key features:
- HDFS (Hadoop Distributed File System): Provides high-throughput access to application data and is designed to scale to large clusters of commodity hardware.
- MapReduce: A programming model for large-scale data processing, breaking down tasks into small parts and distributing them across many nodes.
- YARN (Yet Another Resource Negotiator): Manages resources in clusters, allowing multiple data processing engines to handle data stored in a single platform.
- Extensive ecosystem: Includes tools like Hive, Pig, HBase, and Zookeeper, which support data warehousing, querying, and database management.
2. Apache Spark
![]()
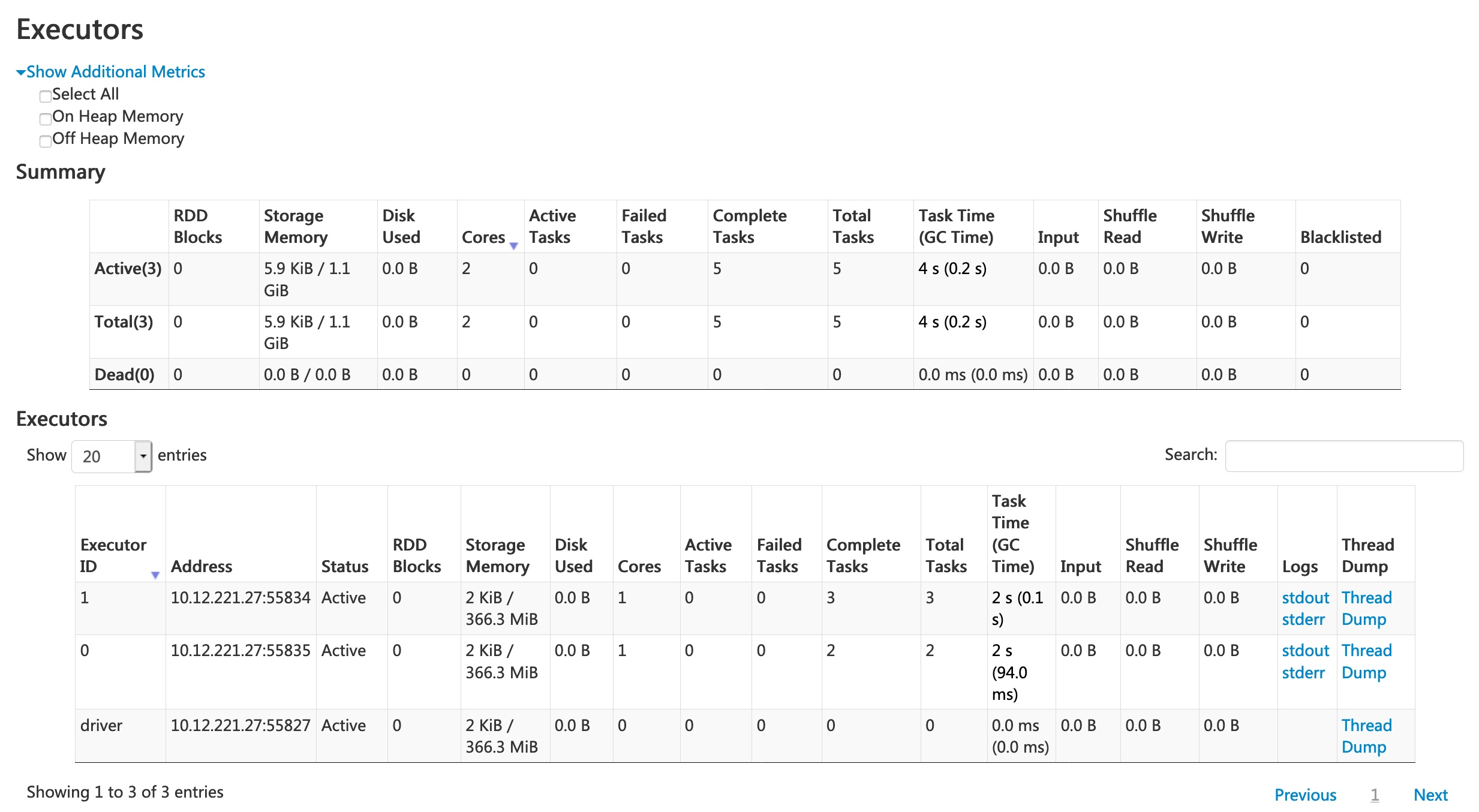
Apache Spark is an open source unified analytics engine for large-scale data processing, compatible with the Hadoop ecosystem. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Spark is known for its speed and ease of use, making it a popular choice for big data processing.
Key features:
- In-memory computing: Processes data in memory, which significantly increases the speed of data processing tasks.
- Advanced directed acyclic graph (DAG) execution engine: Optimizes query plans and ensures efficient data processing.
- Built-in libraries: Includes MLlib for machine learning, GraphX for graph processing, Spark SQL for SQL and structured data processing, and Spark Streaming for real-time data processing.
- Unified engine: Supports both batch and real-time processing, reducing the need for separate processing engines.
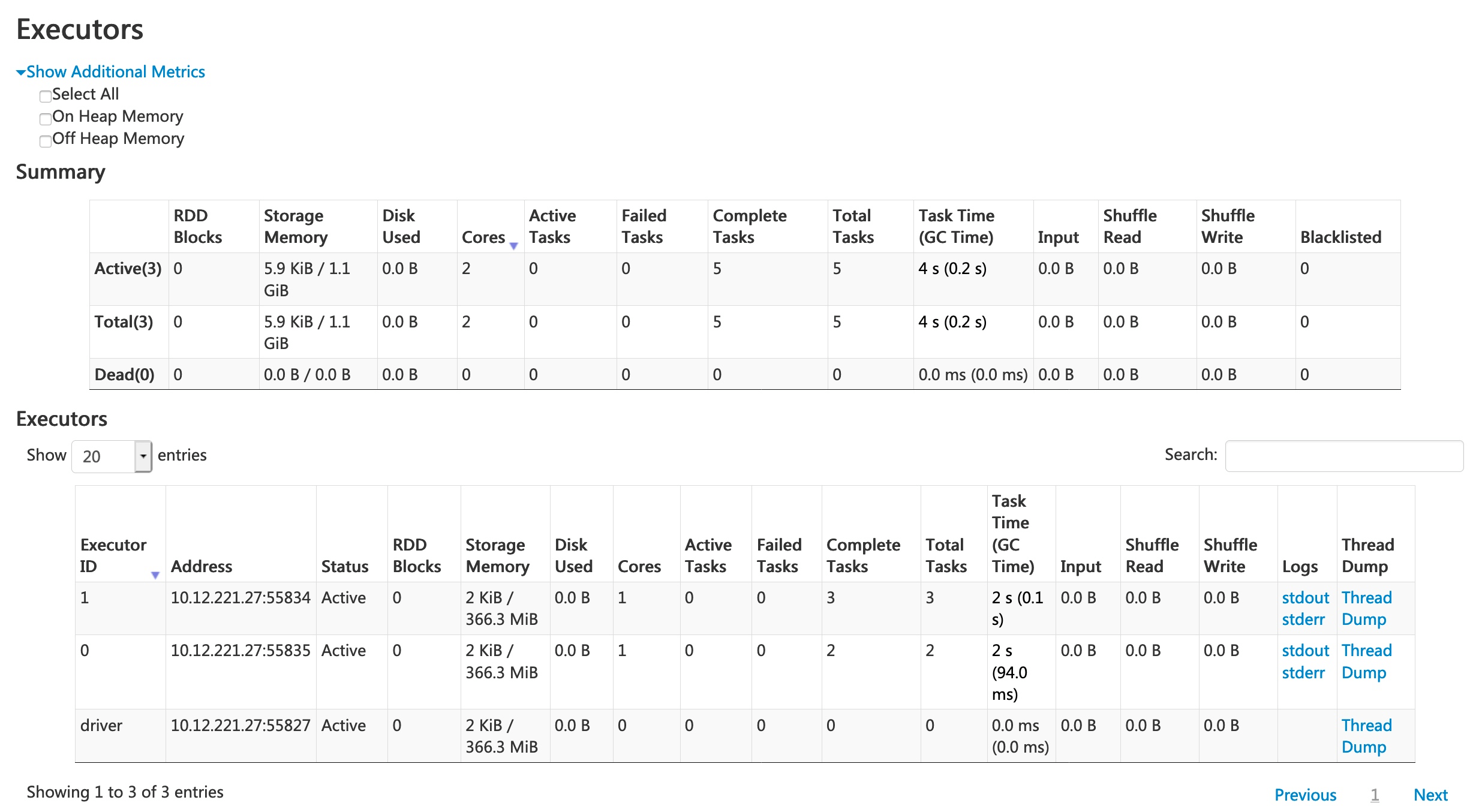
Source: Apache Spark
{kind=link}
3. Apache Kafka
![]()
Apache Kafka is a distributed streaming platform capable of handling trillions of events a day. It can publish and subscribe to streams of records, store them in a fault-tolerant manner, and process them as they occur.
Key features:
- Distributed commit log: Provides durable storage and is replicated for fault tolerance, ensuring high availability and reliability.
- High throughput and low latency: Can process hundreds of megabytes of reads and writes per second from thousands of clients.
- Stream processing: Offers Kafka Streams, a client library for building applications and microservices, and ksqlDB for interactive, SQL-based stream processing.
- Connectors: Comes with Kafka Connect, a framework for connecting Kafka with external systems such as databases, key-value stores, and search indexes.
4. Apache Airflow
![]()
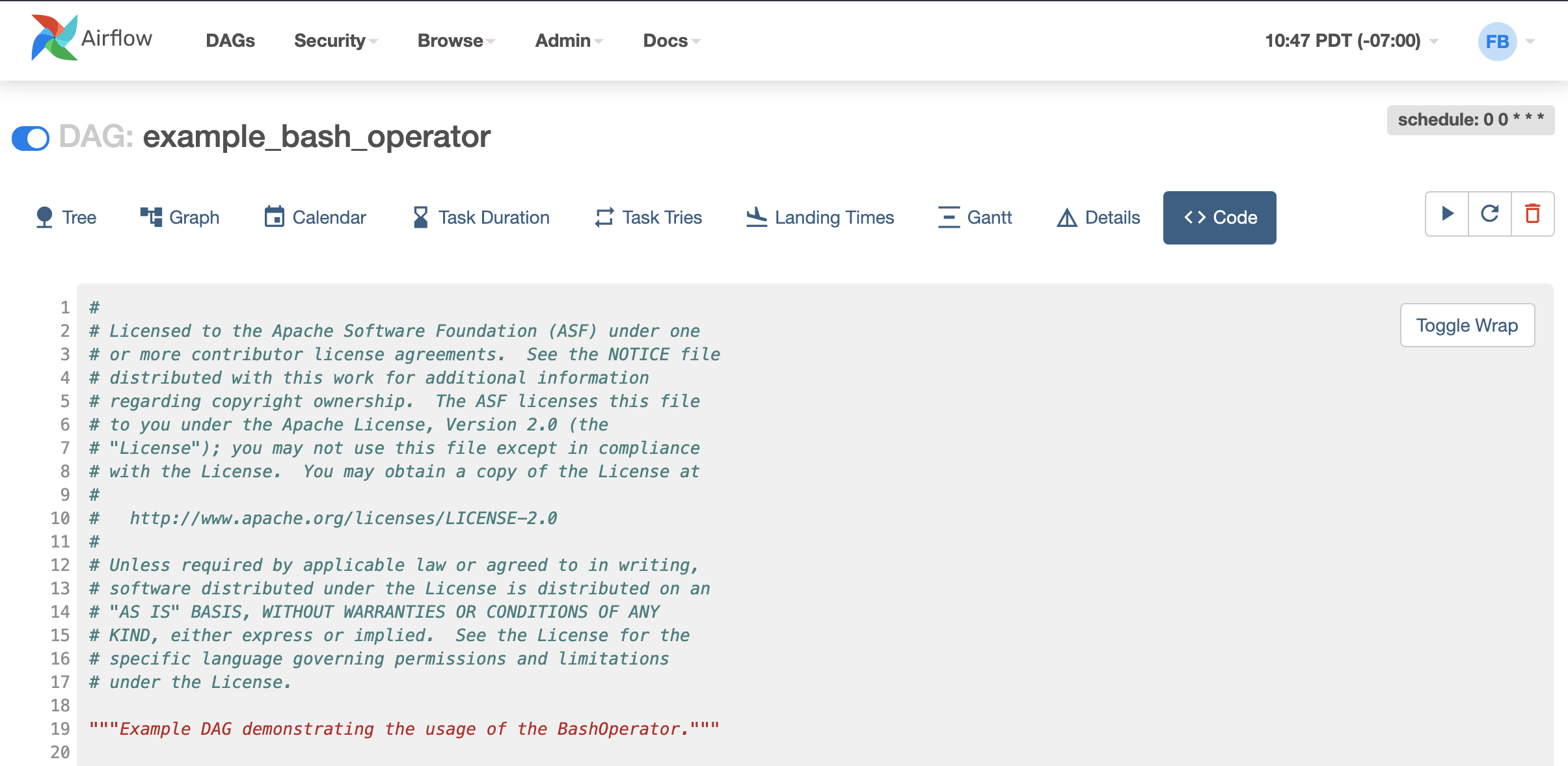
Apache Airflow is an open source platform to programmatically author, schedule, and monitor workflows. It allows for the orchestration of complex data pipelines, ensuring that workflows are run efficiently and correctly.
Key features:
- DAGs: Allows defining workflows as DAGs of tasks, ensuring clarity in task dependencies and execution order.
- Extensible: Plugin architecture enables integration with various systems and services, and custom operators can be added to extend functionality.
- Dynamic pipelines: Workflows are defined in Python, allowing for dynamic generation of tasks and dependencies.
- Rich user interface: Provides a UI to monitor, trigger, and debug workflows, giving clear insights into task statuses and workflow progress.
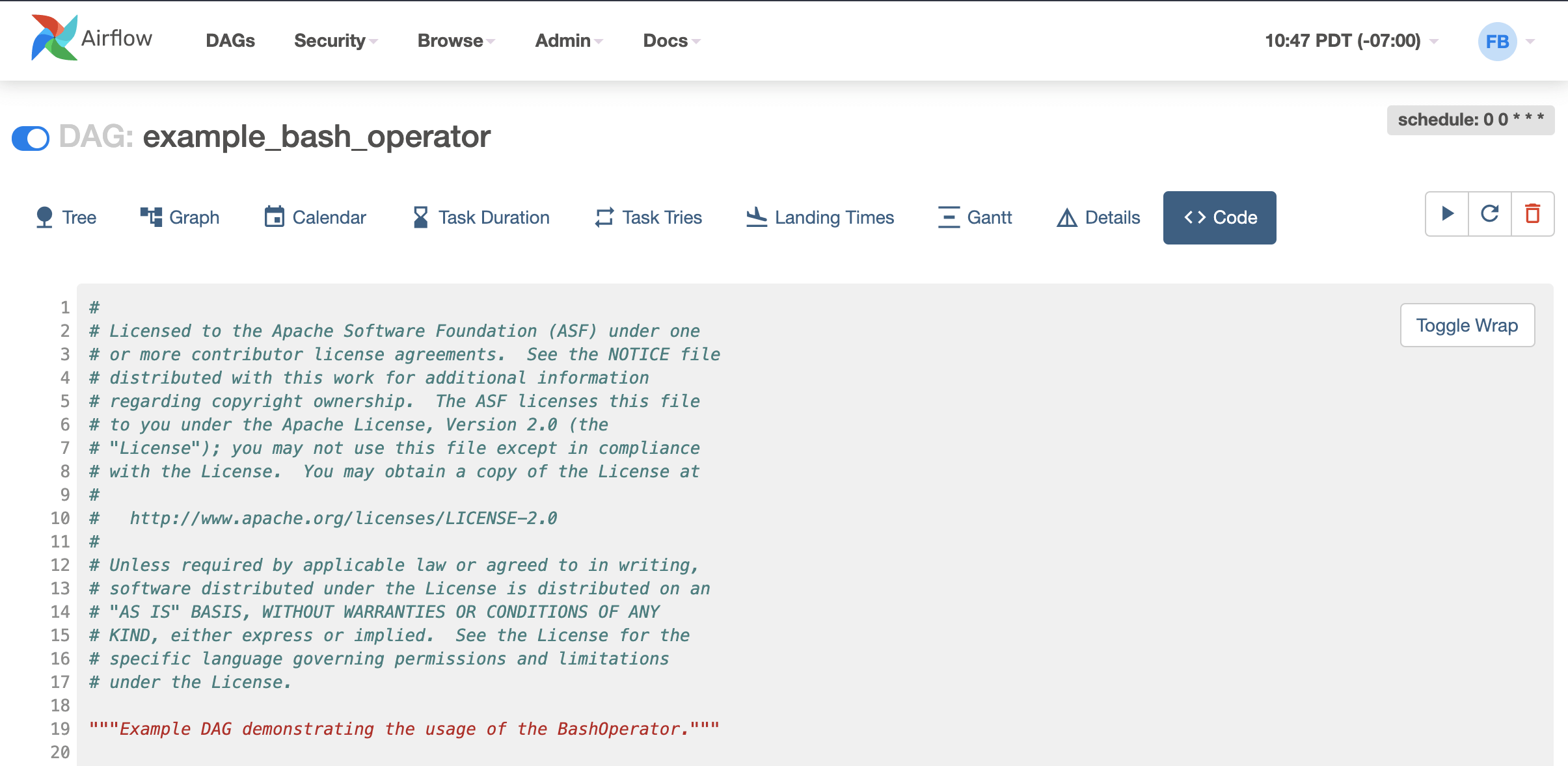
Source: Apache Airflow
{kind=link}
5. Apache Cassandra
![]()
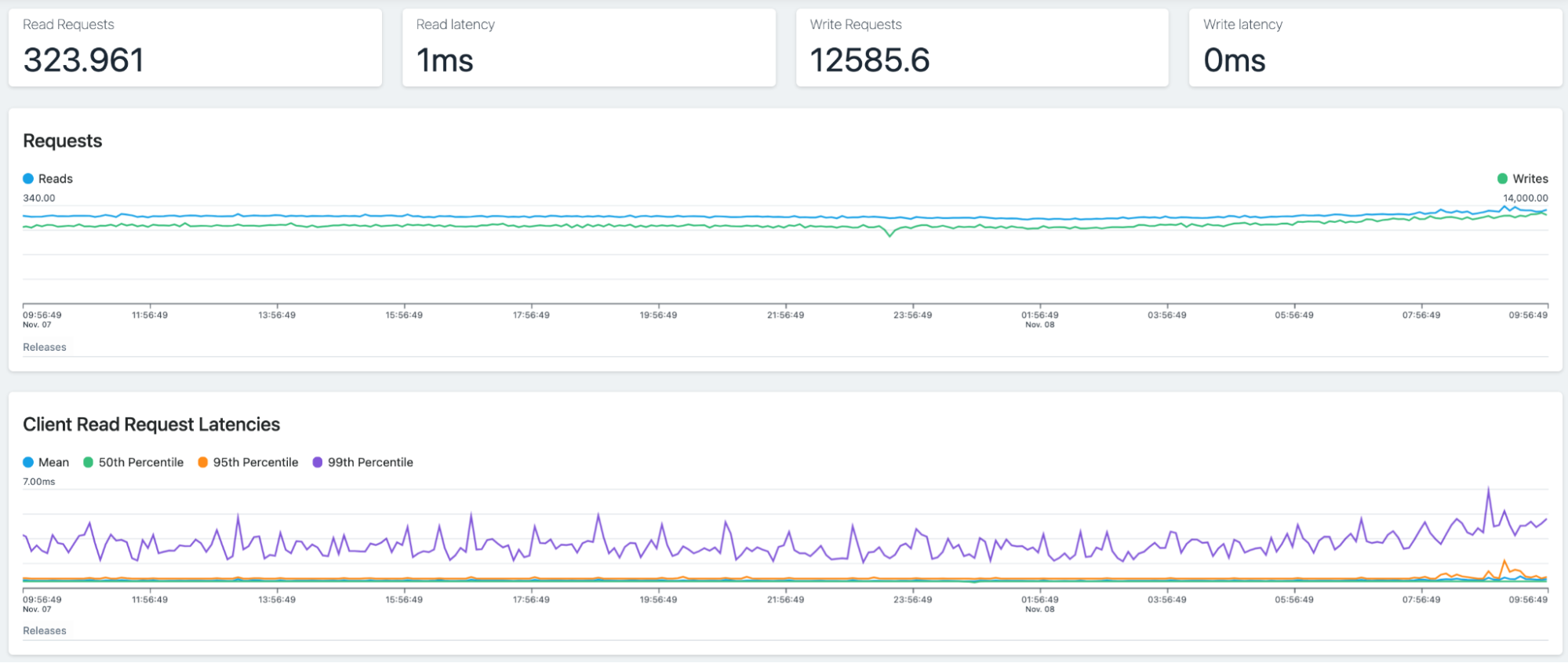
Apache Cassandra is a highly scalable, distributed NoSQL database built to handle large amounts of data across many commodity servers without any single point of failure. It is well-suited for applications that require high availability and fault tolerance.
Key features:
- Peer-to-peer architecture: All nodes in the cluster are identical, eliminating single points of failure and ensuring continuous availability.
- Tunable consistency: Allows configuration of consistency levels based on application needs, balancing between consistency and performance.
- Write-optimized storage: Designed for high write throughput with features like log-structured storage and memtables.
- Distributed data: Uses consistent hashing to distribute data across nodes, ensuring balanced data distribution and efficient data retrieval.
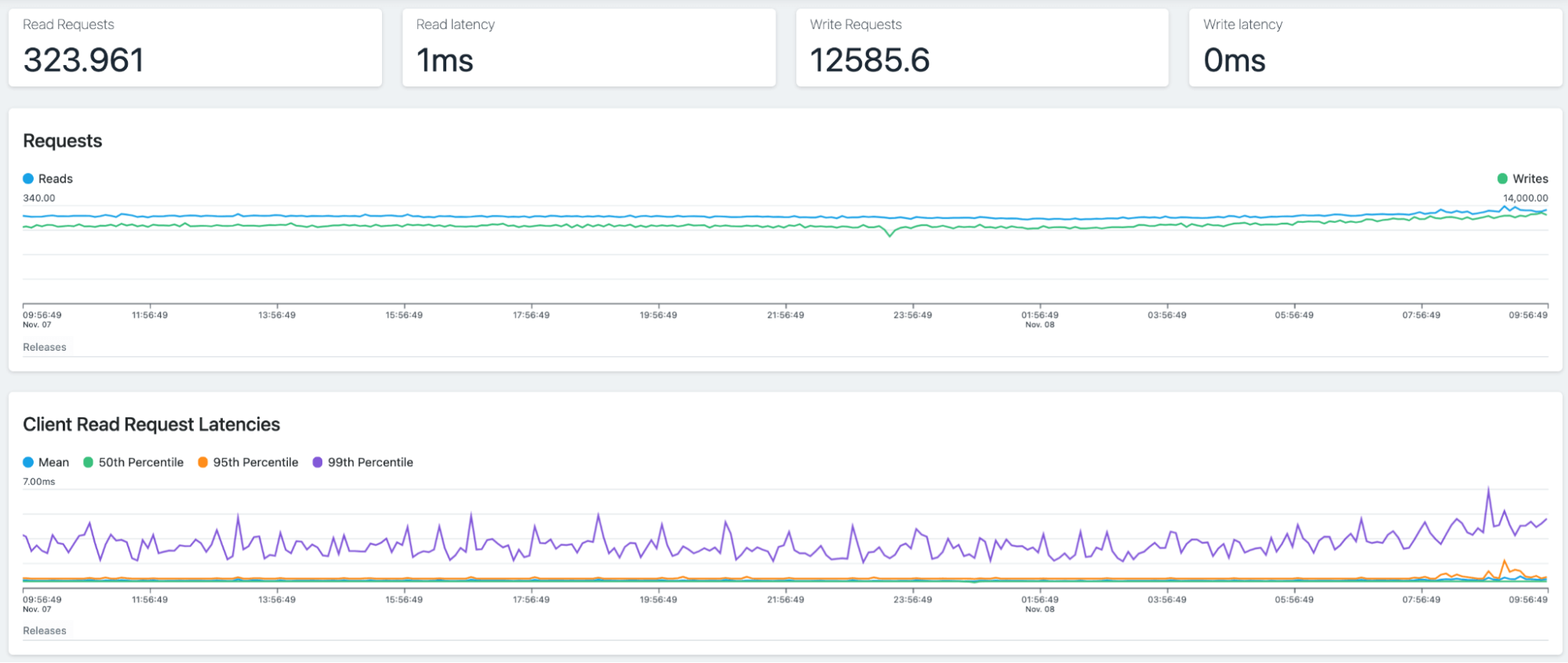
Source: Apache Cassandra
{kind=link}
6. OpenSearch
![]()
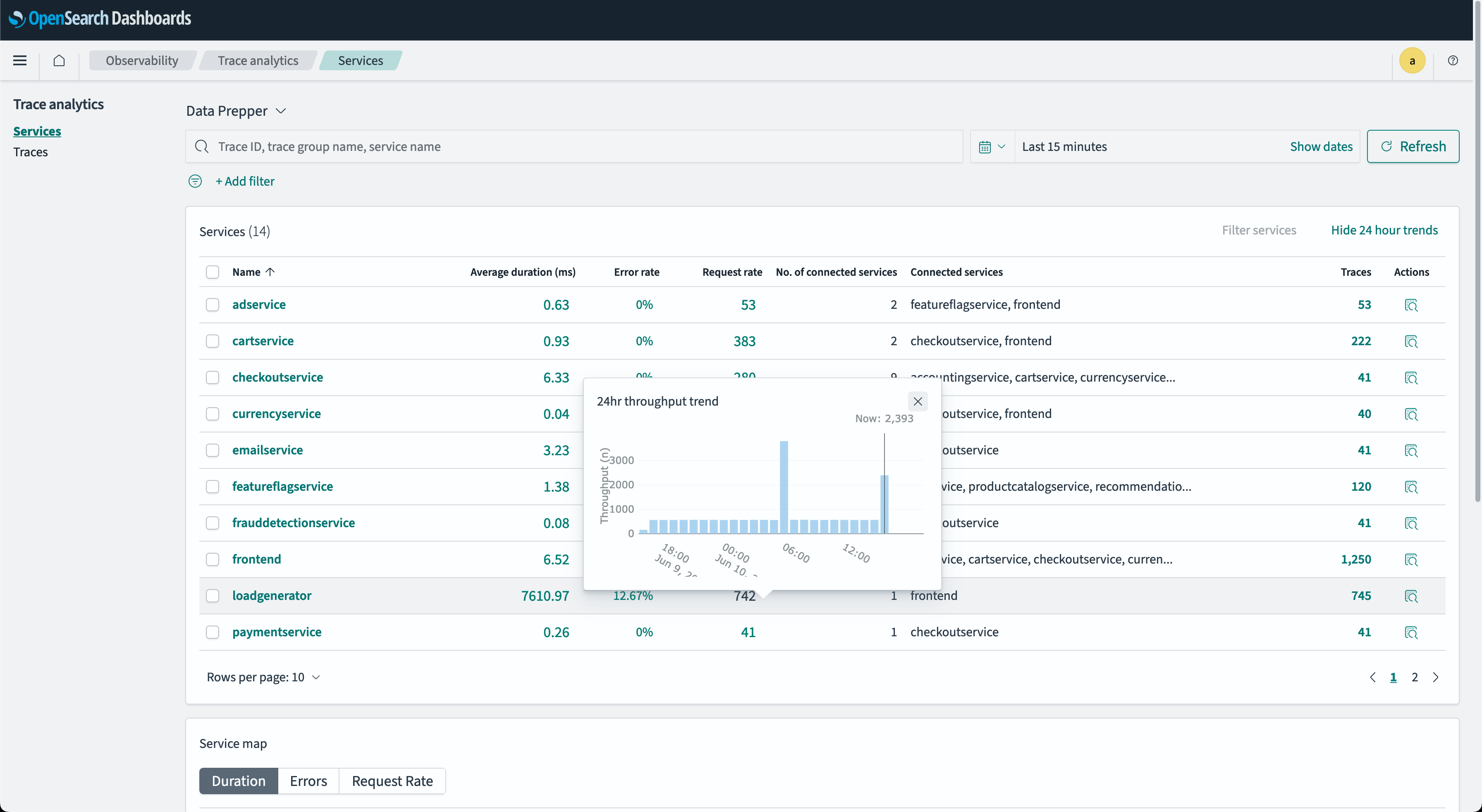
OpenSearch is an open-source, enterprise-grade suite for search, analytics, and observability, aiming to handle unstructured data at scale. It originated as a fork of the Elasticsearch project, and is now managed by the Linux Foundation. It helps organizations to create customized solutions for data search, monitoring, and analysis.
Key features:
- Search capabilities: Includes tools for natural language search and vector database capabilities, enabling smarter and more efficient data queries.
- Observability tools: Offers performance monitoring, log analysis, and real-time issue detection to optimize infrastructure and application health.
- Security analytics: Provides features for detecting security threats, correlating events, and managing threat intelligence.
- Scalable platform: Integrated components for data ingestion, search, and visualization ensure flexibility and extensibility.
- Machine learning support: Enables AI-driven analytics and predictive modeling to improve decision-making.
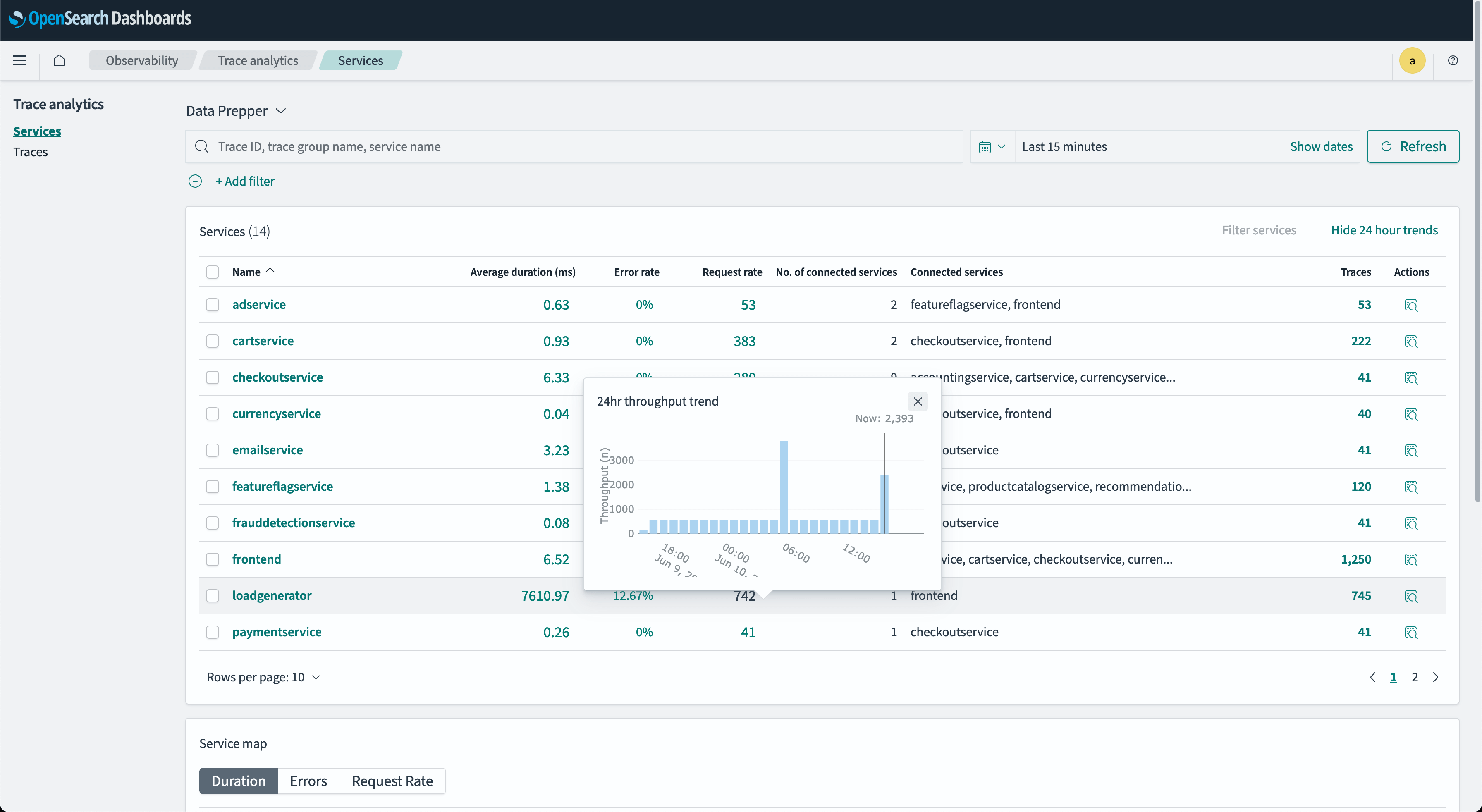
Source: OpenSearch
{kind=link}
7. PostgreSQL

PostgreSQL is an open source relational database management system (RDBMS) known for its reliability, scalability, and standards compliance. It supports both SQL for relational and JSON for non-relational queries, making it a versatile database solution.
Key features:
- ACID compliance: Ensures reliable transactions and data integrity with full ACID (Atomicity, Consistency, Isolation, Durability) compliance.
- Extensibility: Supports custom functions, data types, operators, and indexes, enabling customization.
- Advanced indexing techniques: Includes support for B-tree, hash, GiST, SP-GiST, GIN, and BRIN indexes, optimizing query performance.
- Foreign data wrappers (FDW): Allows querying and integrating data from external databases and data sources.
- Replication: Supports various replication methods, including streaming replication, logical replication, and cascading replication.
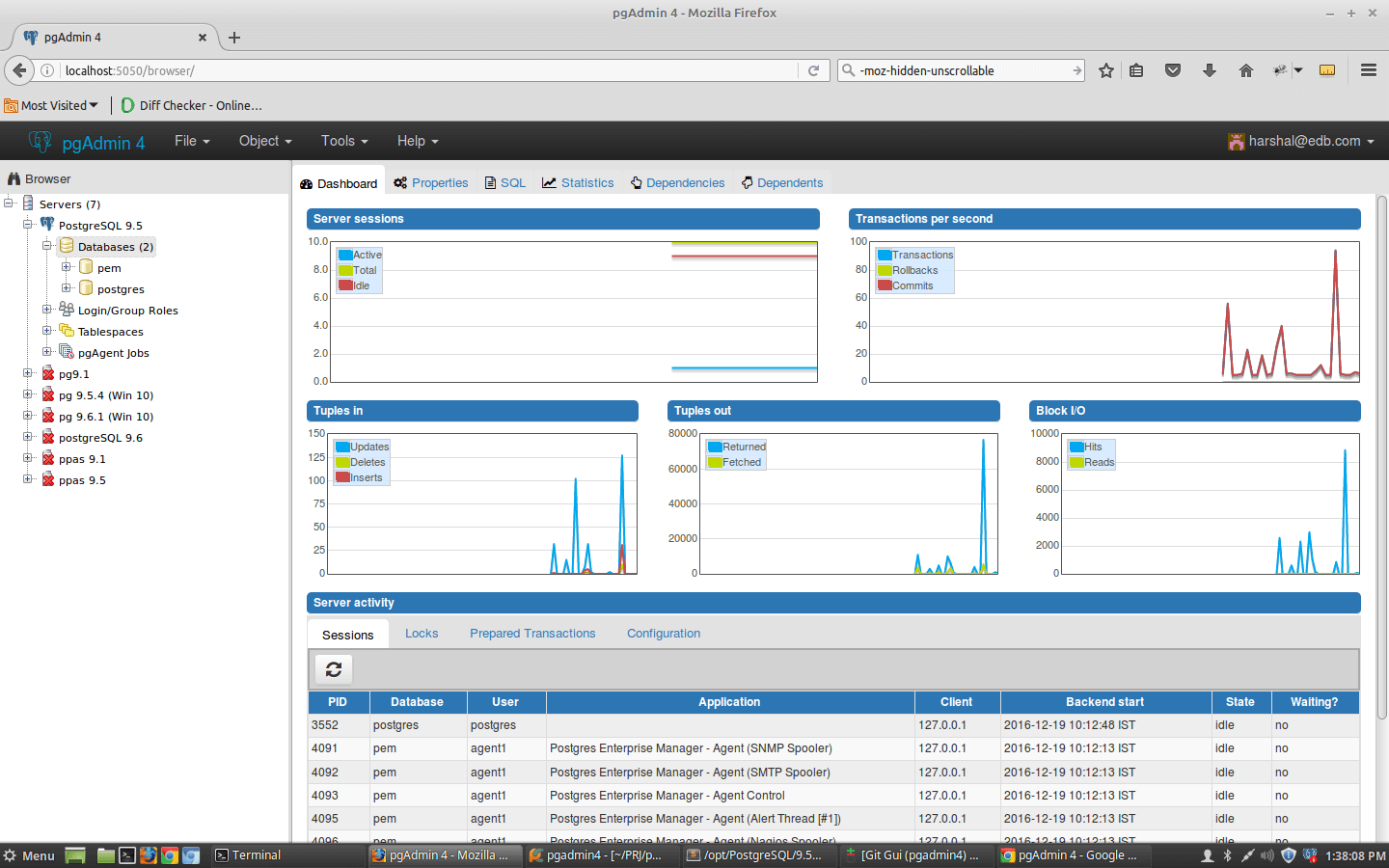
Source: PostgreSQL
{kind=link}
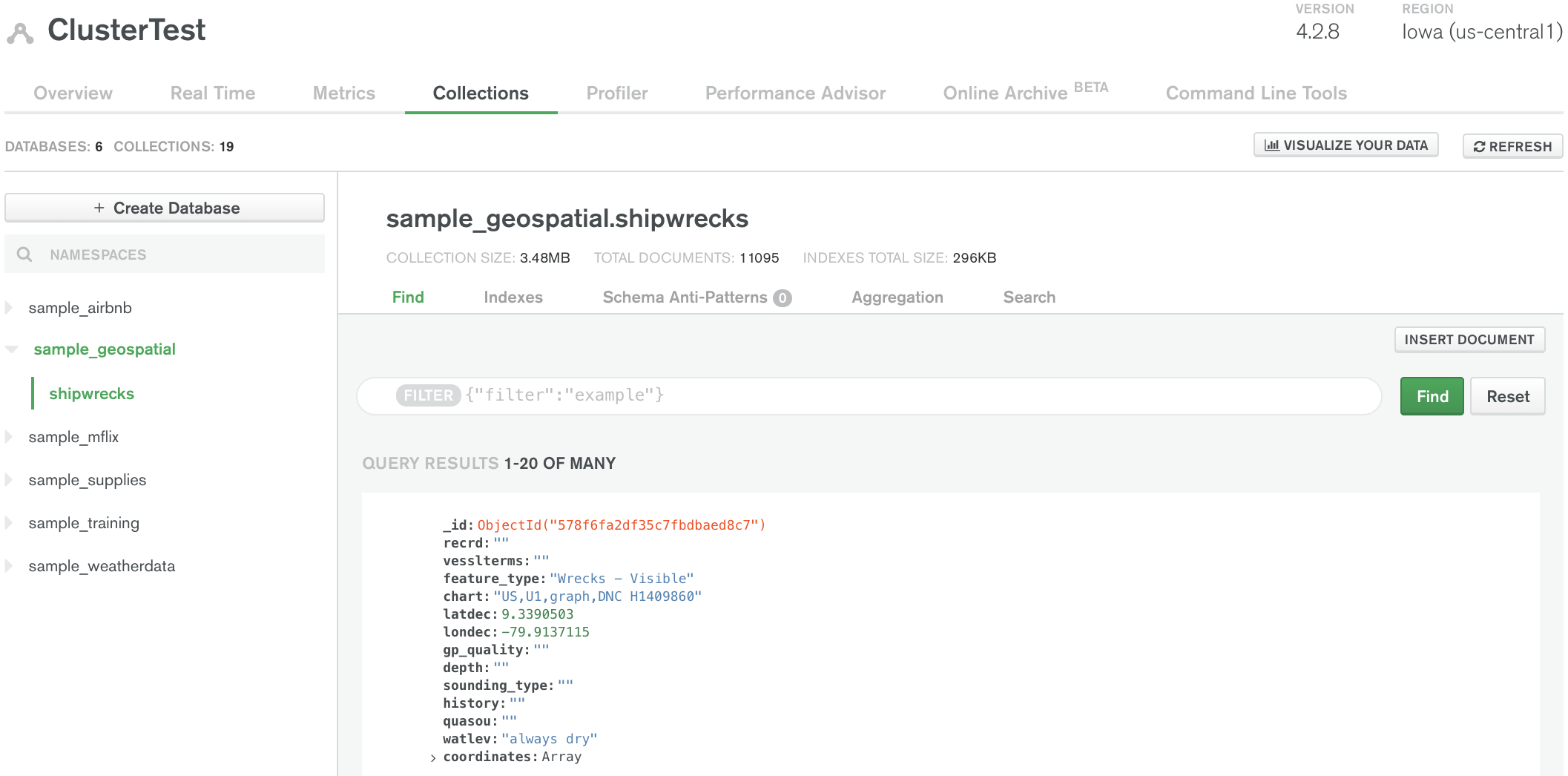
8. MongoDB
![]()
MongoDB is a popular open source NoSQL database known for its flexibility, scalability, and ease of use. It stores data in a JSON-like format called BSON (Binary JSON), which allows for dynamic schema design.
Key features:
- Document-oriented storage: Stores data as documents, enabling flexible and hierarchical data structures.
- Scalability: Supports horizontal scaling through sharding, distributing data across multiple servers.
- High availability: Provides built-in replication with replica sets, ensuring data redundancy and fault tolerance.
- Indexing: Supports various indexing strategies, including single field, compound, geospatial, and text indexes, to optimize query performance.
- Aggregation framework: Offers an aggregation pipeline for data processing and analysis.
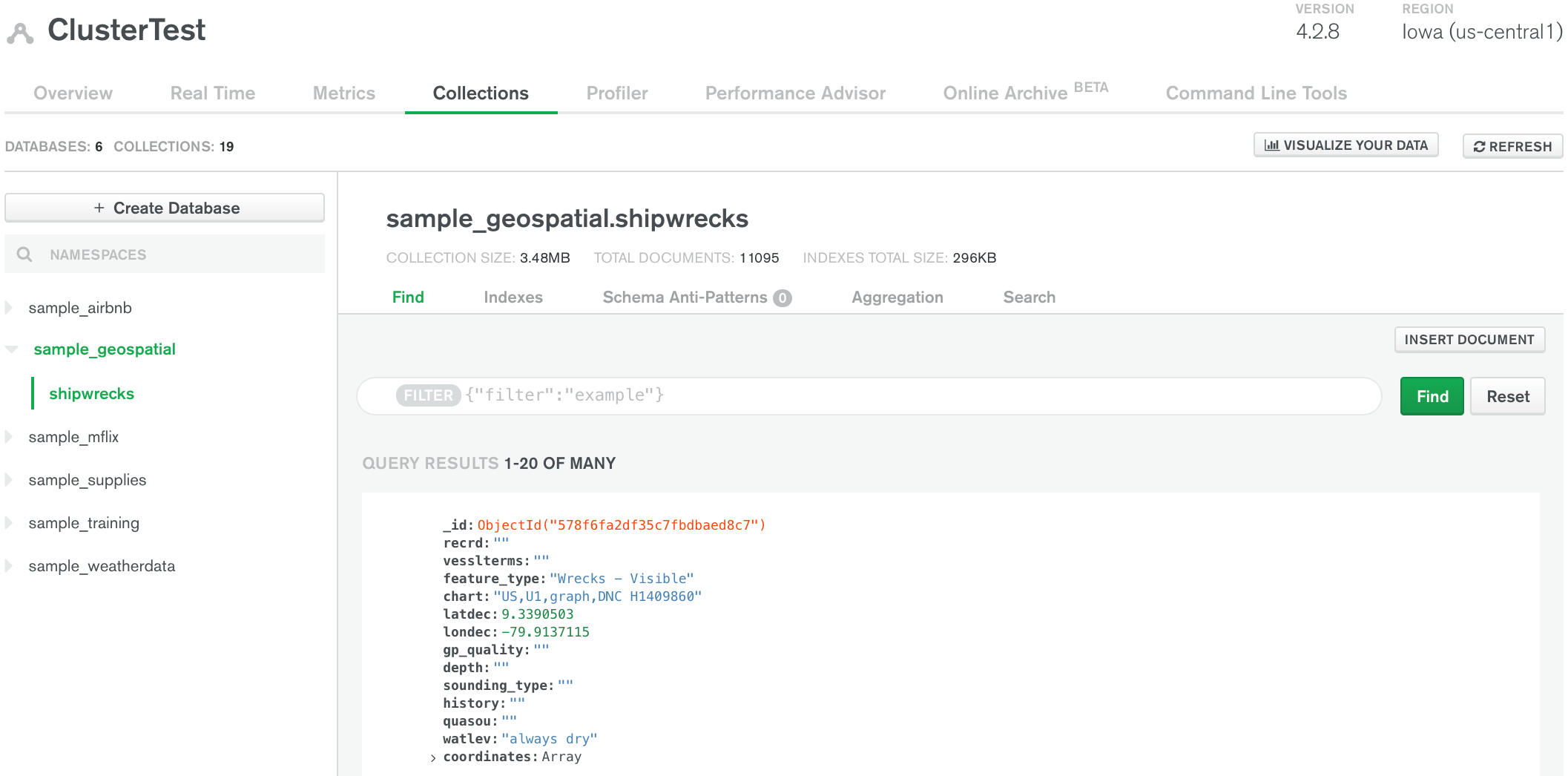
Source: MongoDB
{kind=link}
9. CouchDB

CouchDB is an open source NoSQL database that uses a schema-free, JSON-based document store. It focuses on high availability, offline-first capabilities, and ease of replication across distributed environments.
Key features:
- Multi-version concurrency control (MVCC): Ensures consistency and isolation without locking, allowing concurrent read and write operations.
- Replication and synchronization: Supports bidirectional replication, making it ideal for distributed and offline applications.
- RESTful API: Provides a simple and accessible HTTP/JSON API for database interactions.
- MapReduce views: Utilizes MapReduce to create indexed views and perform complex queries on stored data.
- Eventual consistency: Ensures data consistency across distributed nodes, prioritizing availability and partition tolerance.
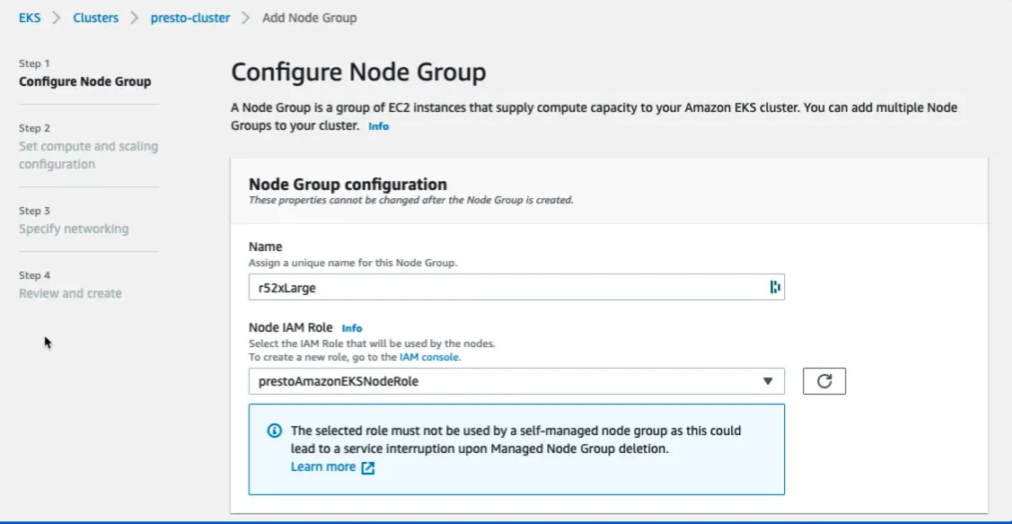
10. Presto
![]()
Presto is a high-performance, distributed SQL query engine designed for processing large datasets across various data sources. Unlike traditional databases, it supports querying data where it resides, including databases like MySQL, Cassandra, or HDFS, without requiring data migration.
Key features:
- Distributed SQL engine: Queries large datasets distributed over multiple sources, enabling flexible data processing.
- Scalable architecture: Can scale out to support many nodes, making it suitable for handling big data analytics across massive clusters.
- In-memory processing: Unlike MapReduce-based systems, processes data in-memory, delivering faster query performance.
- Multi-source querying: Can combine data from different sources (e.g., HDFS, NoSQL databases) in a single query.
- Low-latency analytics: Optimized for low-latency queries, making it ideal for interactive data exploration.

Source: Presto
{kind=link}
Benefits of using multiple open source big data tools
Using multiple big data tools within an open source data platform can provide several key benefits that enhance data processing, management, and analysis capabilities. Here are some notable advantages:
- Enhanced flexibility and customization: Combining different tools allows for a more tailored data ecosystem that can adapt to business needs. Each tool can be selected based on its strengths and integrated into the data pipeline to handle particular tasks, such as data ingestion, storage, processing, or visualization.
- Improved performance and efficiency: Specialized tools are often optimized for specific functions, leading to better performance and efficiency. For example, using Apache Kafka for real-time data streaming, Apache Spark for in-memory processing, and PostgreSQL for relational data storage ensures that each component operates at its best. This can significantly reduce processing time and resource consumption.
- Increased reliability and redundancy: Redundancy is built into the system, as different tools can provide backup options or failover mechanisms. For example, combining Hadoop’s HDFS for distributed storage with Cassandra’s fault-tolerant database design can ensure continuous data availability even in the event of individual component failures.
- Access to advanced features and capabilities: Different tools offer unique features for different use cases. For example, by using Elasticsearch for advanced search capabilities, Apache Airflow for workflow orchestration, and Grafana for real-time monitoring, organizations can exploit the best functionalities each tool offers.
- Community support and rapid innovation: Open source tools benefit from active communities that drive continuous improvement and innovation. By integrating multiple open source tools, organizations can tap into a range of community-driven enhancements, plugins, and integrations.
- Cost-effectiveness: Using open source tools reduces licensing costs associated with proprietary software. Organizations can allocate resources more effectively, investing in development and scaling rather than expensive software licenses.
Empowering open source data management with Instaclustr
Organizations are increasingly relying on open source technologies to gain a competitive edge–and for good reason.
Instaclustr offers a comprehensive suite of managed services that enable businesses to effectively leverage popular open source tools such as Apache Cassandra®, Apache Kafka®, OpenSearch®, PostgreSQL® and more. By simplifying the deployment and management of complex open source data technologies, organizations can focus squarely on building and scaling your applications.
Instaclustr’s managed services take care of the infrastructure setup, configuration, and ongoing maintenance, freeing organizations from the burden of managing these intricate systems themselves–all while ensuring the underlying data platform is running optimally, securely, and with high availability.
Other benefits you get with Instaclustr:
- 24x7x365 expert support ensuring minimal downtime in case of any issues
- Experienced engineers specializing in managing and optimizing open source data platforms
- Proactive monitoring, troubleshooting and performance tuning
- Scale seamlessly to meet the demands of increased workloads
- Ensure optimal performance and cost-efficiency by adding or removing nodes/resources whenever needed–and without worrying about capacity constraints or disruptions
- Industry-leading security and compliance, including GDPR, SOC2, PCI-DSS, ISO27001 and more
- Features like encryption at rest and in transit, fine-grained access controls, and regular security updates
- And more
Ready to experience the incredible power of an open source data platform? Explore our platform or request a personalized demo and let’s get started on creating the best open source solution for your organization.