























At a medieval feast where food is better! This picture illustrate the theme of this and the next blog: “more is often better”! (Source: Adobe Stock)
In two recent blogs, I investigated the new Apache Kafka® Tiered Storage architecture which enables Kafka to stream more (essentially unlimited data) for less cost (by storing more older records on cloud-native storage).
In Part 1 I explored how local vs. remote storage works in theory, and in Part 2 I revealed some performance results and my conclusion that Kafka tiered storage is more like a (pumped hydro) dam (or a write-through cache) than a tiered fountain.
In this blog we’ll take a broader look at why and when more and older data motivates potential Kafka tiered storage use cases. Along the journey, we’ll flow through Kafka time and space, experience Kafka time travel, go seeking with the Kafka consumer, explore delivery semantics, lose ourselves in the river of Kafka infinite streams, and encounter different time scales.
In the next episode we will explore the impact of various consumer behaviours on the amount and age of data processed starting with real-time processing, then move on to slow consumers, Kafka as a buffer, disconnected consumers, Kafka record replaying and reprocessing use cases, new Kafka sink/downstream systems, and end up on a new colony planet with replicating/migrating Kafka clusters.
Time and space in Kafka

Time vs Space–which one will win? (Source: Adobe Stock)
Time is a critical concept in streaming systems in general, and Apache Kafka is no exception. Common definitions of streaming time include:
- Wall-clock time
- The time “now” on a particular server/broker/application (hopefully synchronized and therefore close across all of them, probably using NTP). Here are some older instructions on how to do this for Instaclustr’s managed Apache Cassandra® clusters.
- Event or source time
- The wall-clock time that an event was created by the source. In Kafka, this is the time at the producer, CreateTime.
- Ingestion time
- The wall-clock time that an event is ingested into the Kafka broker—this is after event time, LogAppendTime.
- Processing time
- The wall-clock time that an event is processed by a consumer—after ingestion time (and only if it is processed).
- Stream time
- The largest/latest/most recent timestamp seen in Kafka Streams—it only moves forward—it’s mentioned here.
To summarize (where a < b means ‘a occurs before b’):
- event time [earliest, producer time] <
- ingestion time [broker time] <
- processing time [latest, consumer time]
In Kafka, there’s a timestamp associated with each record (along with a value and optional key and metadata headers) which, depending on the Kafka configuration, has the temporal semantics of either event or ingestion time. Processing time is determined solely and optionally by consumers. Note that because Kafka events can be read multiple times, they can have multiple processing times—or none if an event is not processed.
The default timestamp semantics in Kafka is event time, called CreateTime in Kafka, which can be changed to ingestion time (LogAppendTime in Kafka) at the cluster level with log.message.timestamp.type or per topic with message.timestamp.type. Processing time is just the wall-clock time, as determined by a consumer, when (and if) a record is processed.
Kafka time travel

(Source: Adobe Stock)
Taking this a bit further, Kafka can time travel. Real-time processing is in the present, say, less than a few seconds time delay. If consumers start to slow down, then they process events from the near past. And with event replaying consumers can move even further backwards in time and process events from the more distant past.
In theory, Kafka can even process events out of order, and even backwards, etc.! So, Kafka doesn’t just enable time travel and time dilation (speeding up, slowing down, e.g. in the movie Interstellar) but time-reversal or inversion—or time flowing backwards (e.g. the movie Tenet).
Time reversal is actually useful in other time series domains such as signal processing (e.g. to reconstruct source events, including lightning strikes), and I can imagine use cases in Kafka—for example, finding the most recent event of a certain type, or set of data points that diverge from expected ML model predictions. Note that Kafka consumers receive batches of records in order after each poll, so the consumer would need to manually handle processing them in reverse chronological order.
And this reminds me that Kafka can handle late or out-of-order events—that’s pretty clever! This is a potential reprocessing (a concept we’ll see more of later) use case for Kafka streams and includes reprocessing for missing, erroneous and out-of-order/late events, see Kafka Streams Out-of-Order Handling documentation).
Oh no! It appears I’m in a time loop (something to watch out for in distributed streaming systems such as MM2 [theory] and MM2 [practice])—here’s an early blog I wrote on Kafka reprocessing use cases that I found when researching Kafka time travel for this blog—with more brain memory space I may have remembered this older blog sooner! I also came across this blog which takes a fun look at parallels between Kafka’s time and the movie Dark.
So, what does time have to do with space?
Well, producing and storing more records for longer requires more space, so time and space are related. As we saw in the previous blogs in this tiered storage series, Kafka limits the amount of space taken up by records by deleting records that are older than the time or space retention limits.
But with the new tiered storage architecture, records are also (and mostly) stored on potentially unbounded cloud storage, so records can be kept for longer, enabling cheaper access to more and therefore older records. So, it’s cool that more space gives you more time (famously, the Doctor’s TARDIS is “bigger on the inside” than the out—some sort of clever space/time magic/science evidently!)
Consumer seeking

Sir Galahad was famous for seeking the Holy Grail (Source: Adobe Stock)
How does a Kafka record get to time travel? Well, it’s up to the Kafka consumers, as they determine the processing time (the time travel delay and direction etc) of records.
As we’ll see later, this can be due to unavoidable delays between the source and processing times due to a variety of factors, or due to the intentional behavior/interest of the Kafka consumers. Once Kafka consumers successfully subscribe to a topic, by default they start reading from the latest available records.
However, they can also choose (using consumer.seek()) to read from the earliest available, latest available, or specific offsets (and times if you use the offsetsForTimes() method to first get the offsets for times). Two things to note:
- The earliest available offset may be > offset zero (if records have been deleted).
- auto.offset.reset is an important default, otherwise, you can end up having to handle the InvalidOffsetException.
So, the consumer “time travel” behaviour can be as simple (real-time, forwards only) or as complex as you like, or the use case demands.
Delivery semantics (at least once, exactly-once)
The reason that Kafka consumers can seek is due to a design feature of Kafka that puts the consumers in charge of keeping track of successfully processed records (consumer position or offset). The default consumer behaviour acknowledges batches of polled records once they have all been processed (i.e. at the next poll).
However, if something goes wrong and the consumer crashes the whole batch of records will be re-consumed when another consumer takes over, so there is the potential for messages to be consumed multiple times—this gives us “at least once” delivery semantics, and requires that records are persisted at least until they are acknowledged (but in practice longer).
So, the side-effect of this decision is that a consumer can deliberately rewind back to an old offset and re-consume data (replaying). For more information, see this blog which explains delivery semantics in more detail (“I’m only going to say this {zero, once, multiple} times!”), and this blog on how to get exactly-once delivery semantics in Kafka Streams (“Transactional Magic Pixie Dust”).
A note on kafka-consumer-groups CLI Command
There’s a useful Kafka CLI tool that helps monitor and manage consumer group offsets, kafka-consumer-groups.sh, and provides more abstractions and examples of Kafka time/offset shifting options.
Options (for reset-offsets) are to-datetime, to-earliest, to-latest, shift-by (positive or negate integer shift), from-file (reset offsets to multiple values from a file), to-current, by-duration (duration from current timestamp) and to-offset.
Watch out as impossible times or offsets (past or future) are adjusted to available offsets, and all consumers in the group must be inactive.
Infinite streams

A photo of the Milky Way from the middle of the Australian outback earlier this year. iIt’s very dark in the outback, so even a phone camera does a reasonable job of capturing our galaxy (which in English is just called the “Milky Way”) (Source: Paul Brebner)
As if time and space aren’t tricky enough, how about adding infinity to the mix?
Conceptually, streams of Kafka data are infinite! Well, unbounded and continuously updating at least, so definitely unknown in size, and therefore potentially infinite. Now, infinity is “big”—like the Milky Way.
Up until 100 years ago astronomers believed that all the stars were contained in the Milky Way, but in the 1920’s they discovered many more galaxies with even more stars. Also related to Kafka streaming is that many cultures saw the Milky Way as a river—e.g. the House River (Aboriginal), the River Ganga of the sky (Indian), the Silver River (Chinese) and the River of Heaven (Japanese).
So, it may not be technically “infinite” but at 87,000 light years in diameter, the Milky Way is big enough for my local galaxy and illustrates well the idea of an infinite river/stream.
Just remember that in practice Kafka streams are not practically infinite as they have finite features including a start offset/time, a latest offset/time, and due to the very real limitations of physical storage (even cloud native) they can only store a subset of data. So, if the earliest data is no longer available, a request for old data will fail.
On the other hand, if you decide to use tiered storage with a high retention time/space, then you will end up with potentially enormous volumes and ages of data to play around with!
Time scales

Space-time diagram showing the vastly different timescales of the universe varying from microseconds to billions of years. (Source: Adobe Stock)
Also related to time, space, and infinity, are time scales: things that run faster or slower, potentially across vast magnitudes of time scales or orders of time, from nanoseconds to billions of years.
Apache Kafka is a good example of a fast stream processing system, but also capable of handling longer time scales—allowing close to real-time processing for some workloads, and potentially slower or less linear processing for others (time travelling, replaying etc). But Kafka can also be used in conjunction with other technologies to bridge between different architectural styles and time scales.
For example, I wrote a series last year called “Spinning Your Drones With Cadence and Apache Kafka.” In this series, I combined slow/long-running Cadence® workflows with fast Kafka microservices to coordinate drone delivery events across multiple systems and workflows running at different speeds including drones, orders, shops, deliveries, and customers.
Some interesting time orders of magnitude (in seconds) include:
- nanosecond (1 ns, the time to execute a machine cycle in a 1 GHZ CPU)
- millisecond (1 ms, the time for a neuron in the human brain to fire and return to rest)
- decisecond (1 ds, a blink of an eye)
- hectoseconds (2 hs, an average length video)
- kiloseconds (86.4 ks/24 h, the length of a day on earth)
- megaseconds (2.36 Ms, the lunar month)
- gigaseconds (1.73 Gs, seconds since start of Unix time now)
Obviously, there are lots of times longer and older than this, but in terms of recordings on digital media, I assume this is the oldest we are likely to encounter, backwards in time at least (who knows how long computers will last into the future?).
In practice, it’s currently unrealistic to store and access streaming data for billions of years, but some natural and artificial processes can run for ages, potentially for years, or Gs if you prefer (one millennium is 31.6 Gs—to put this in perspective, the oldest working clock is only around 638 years old).
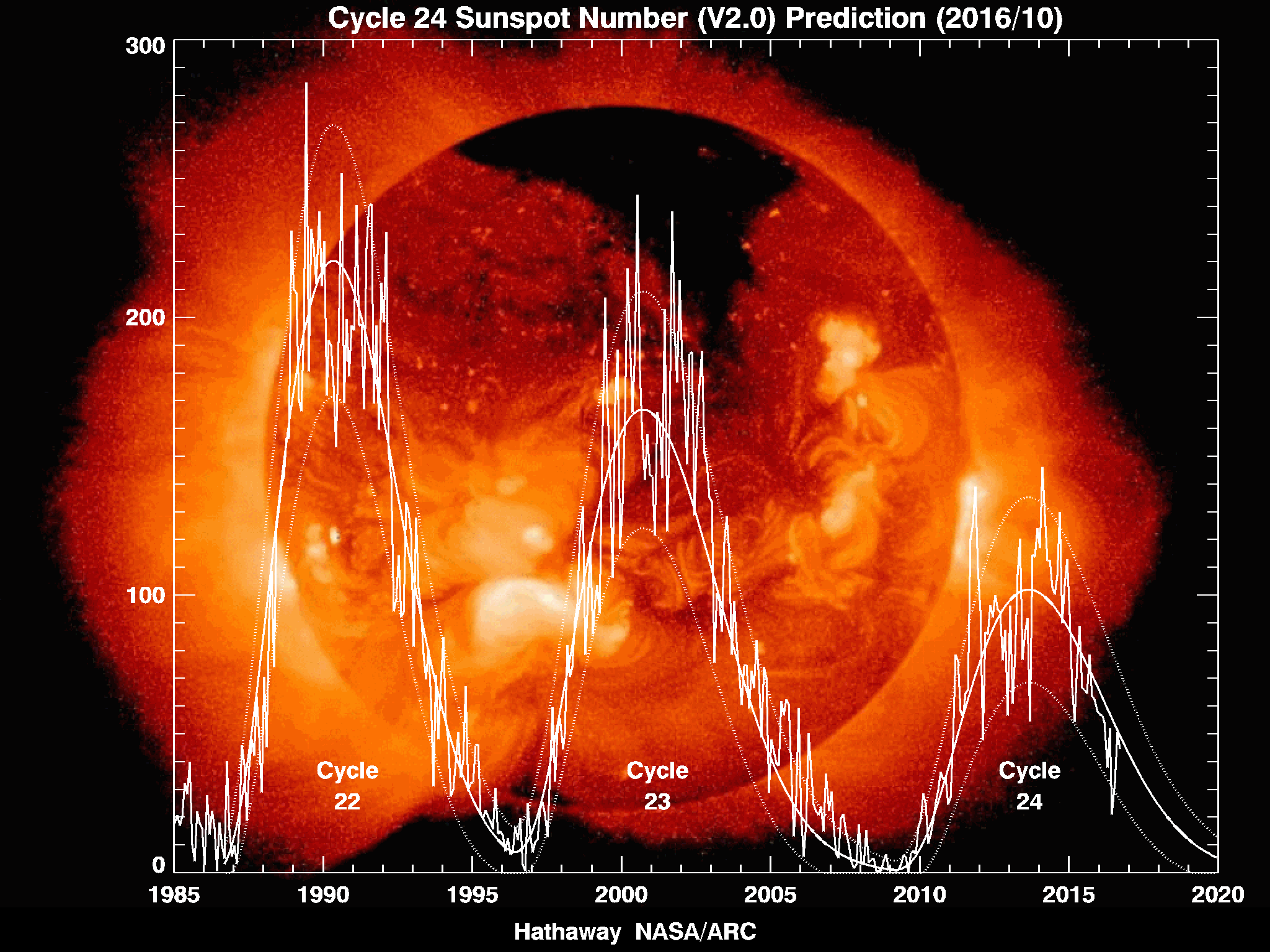
The solar cycle (which causes more and larger solar flares) is approximately 11 years long or 0.35 Gs, well within the realms of processing with Kafka (Source: Wikipedia)
For the normal real-time processing of records, this just means that the producers and consumers are working flat out, and the Kafka broker and the clients will need to be long-lived, processing data continuously for eons/aeons (using the informal definition of an eon = a long indefinite period c.f. astronomy = a billion years)!
But for other types of consumers and use cases, as we’ll see, this may mean that more or less data is replayed for a variety of reasons. Just to keep an open mind that even though Kafka is designed for fast/continuous processing of streams, it may be used for more “temporally anomalous” time scale crossing use cases as well!
In Part 4, we’ll take a look at the motivation for some different use cases and consumer behaviours, across increasing temporal scales.
Instaclustr for Apache Kafka Tiered Storage is now available as a Public Preview, so find out more here and try it out with some of these types of use cases.