






















1. How Do Kafka Concurrency and Throughput Work?
Apache Kafka® is a high-throughput, low-latency distributed streaming platform. It enables messages to be sent from multiple distributed producers via the distributed Kafka cluster and topics, to multiple distributed consumers. Here’s a photo I took in Berlin of a very old machine that has a similar architecture; I’ll reveal what it does later.

(Source: Paul Brebner)
Partitions and Consumers
In common with other modern Big Data platforms, Kafka achieves unlimited horizontal scalability by partitioning data across multiple nodes in a cluster. For Kafka, this means that each topic has 1 or more partitions. The more partitions a topic has, the higher the concurrency and therefore the higher the potential throughput. To actually process the messages in Kafka, you need to have 1 or more consumers subscribed to a topic (or the messages just sit in the topic and eventually expire and are removed).
But how many consumers can subscribe to a topic (in a single group)? Is there a limit?
The rule in Kafka is a maximum of 1 consumer per partition (as each partition must only be allocated to 1 consumer), so you can only have as many consumers (in a single consumer group) as there are partitions for a topic, but you can also have less. This means that in practice consumers can process records from 1 or more partitions. The maximum throughput will be achieved with 1 consumer per partition, or as many consumers are there are partitions.
If consumers are dogs, and partitions are bowls, then you imagine the scenarios that work out well. A dog can eat from multiple bowls, or one bowl, but you can’t have multiple dogs eating from the same bowl. You can have more bowls (partitions) than dogs (consumers), but not more dogs (consumers) than bowls (partitions) – e.g., this situation isn’t allowed:

6 hungry animals and only 2 bowls isn’t a good idea!
(Source: Shutterstock)
Thread Safety and Slow Consumers
Kafka consumers are not thread safe—you can’t share a consumer instance among multiple threads. On the other hand, Kafka producers are thread-safe and can be shared among multiple threads.
The default Kafka consumer is only single-threaded, so it can only process records sequentially, with committing done automatically upon successful record processing. This works fine if the processing time is close to 0 but becomes a problem if the processing time is longer—so-called “slow consumers”. Basically, each record has to wait in line to be processed, which increases the end-to-end latency of the records.
In addition, single-threaded consumers can’t take advantage of potential concurrency from being assigned multiple partitions (dogs with multiple bowls), as records from multiple partitions are still processed sequentially, rather than concurrently.
Because each consumer is single-threaded, in order to obtain higher throughput, the only solution is to increase the number of partitions and consumers. However, partitions and consumers both use resources. Because of Kafka replication, too many partitions can actually result in an eventual drop in throughput (original results, updated results with Kafka KRaft). Multiple consumer groups (enabling high fan-out architectures) require more partitions, and consumer groups with large numbers of consumers can take a long time to rebalance (introducing undesirable latencies when no processing is done). Consumers also require memory and CPU resources so often require more infrastructure resources than the Kafka cluster itself.
Too Many Partitions
Now, Little’s Law (Concurrency = Throughput x Time, we’ve used this before to tune Kafka Connect) explains the relationship between the number of consumers (Concurrency), also equal to the number of partitions for the maximum throughput, the record processing throughput, and the processing time of the records, and can be used to compute any 1 variable given the other 2 variables. For example, this graph shows the decreasing Throughput for Partitions=Consumers with different processing times (0, 1, 10, 100ms), computed using Throughput=/Concurency/Time. The x-axis is the number of partitions=consumers for the topic, the y-axis (logarithmic scale) is throughput. The yellow line shows the theoretical maximum throughput (assuming an arbitrary but realistic 10,000 TPS per partition) and zero processing time. The other lines show the increasing impact of processing time on throughput.
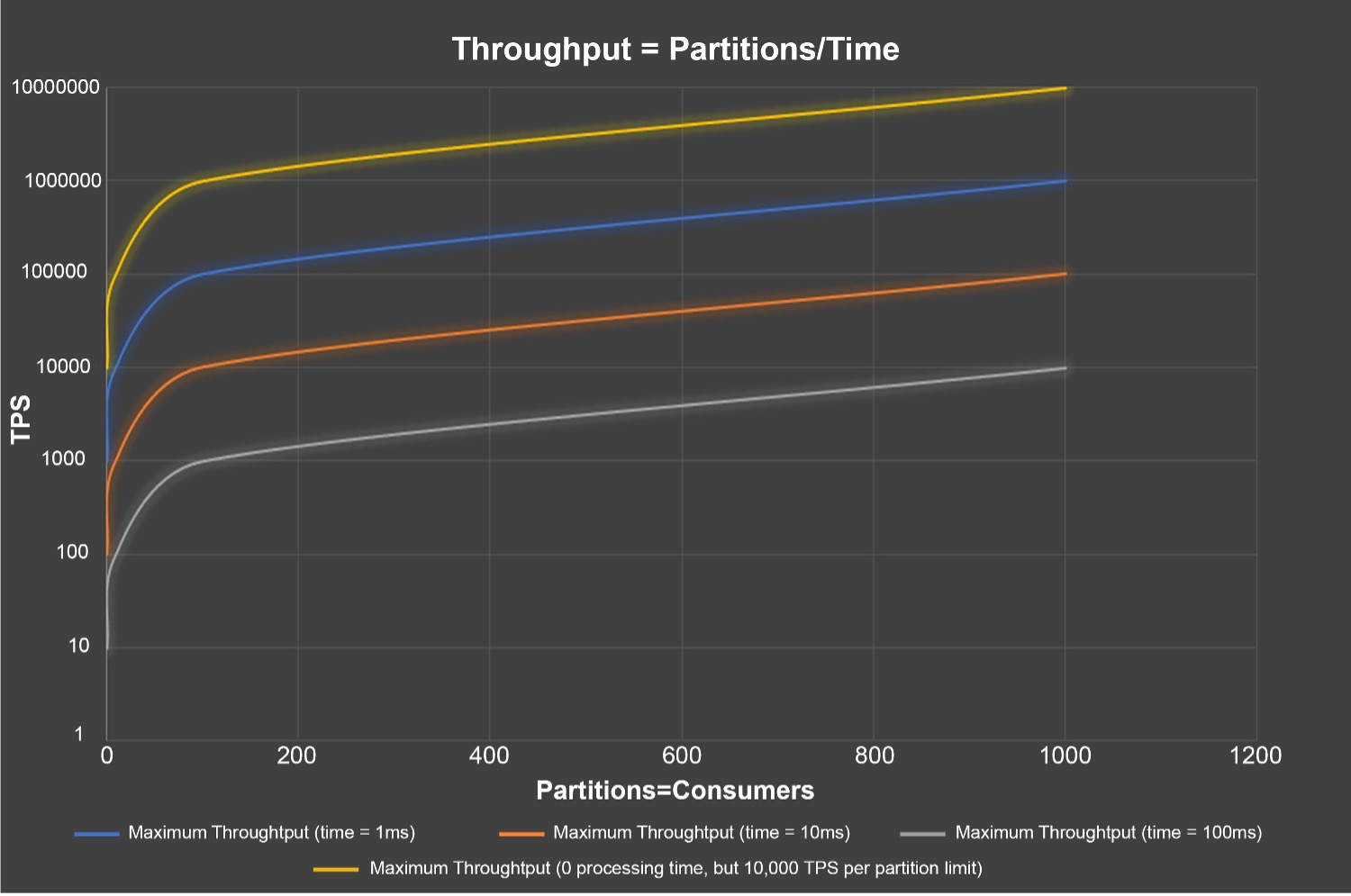
If we have a target of 1M TPS with non-zero processing times, what can we do to achieve it?
Another way of looking at the same data is how many partitions (and consumers) are required to achieve 1M TPS with increasing processing time—from 1000 at 1ms to 100,000 at 100ms. This shows the real problem, which is that too many partitions (and consumers) may be required for longer processing times, potentially requiring bigger Kafka clusters and more consumer resources than is practical or economical.
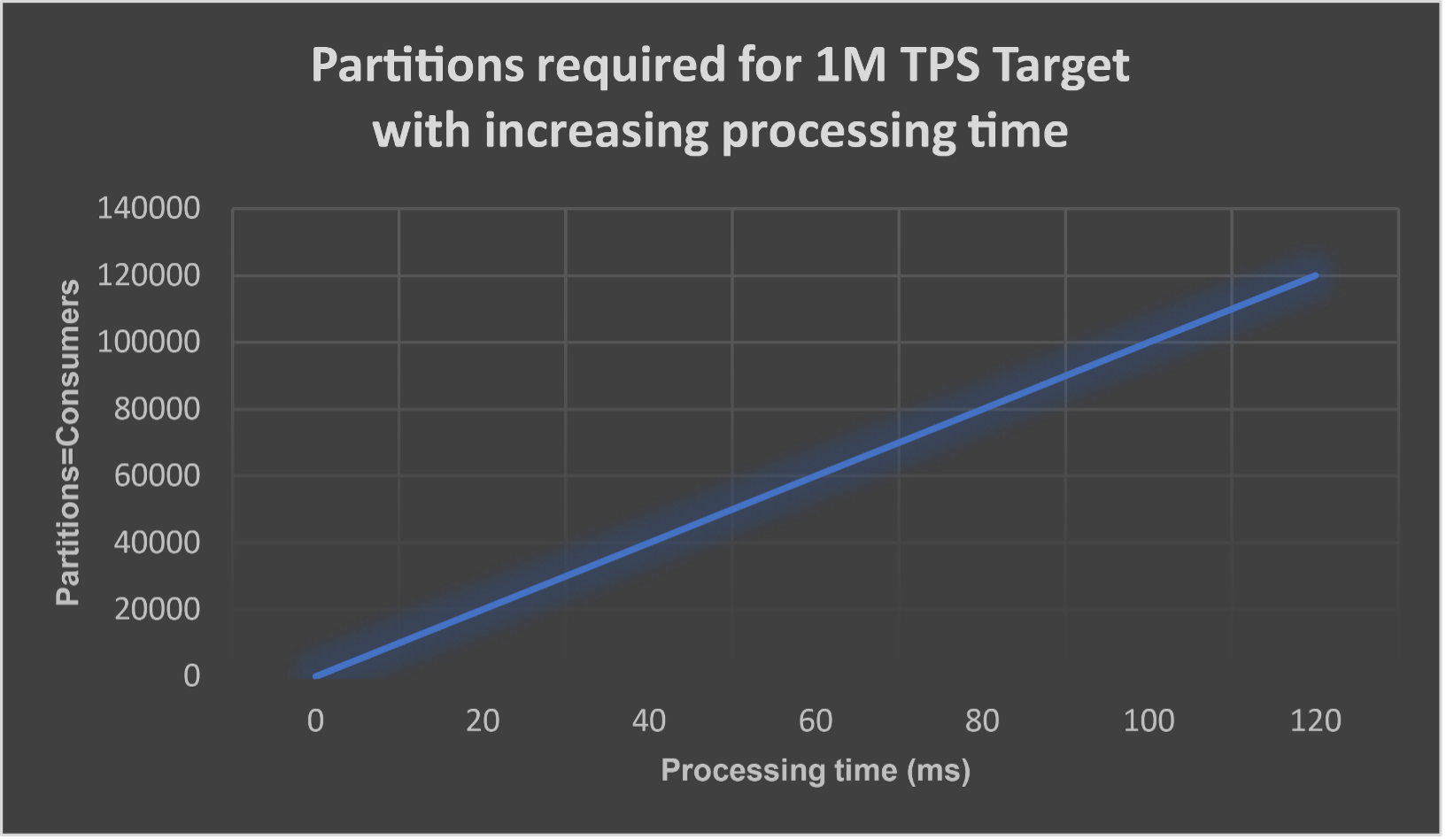
2. How Can Kafka Concurrency Be Increased?
In the past 6 years, I’ve built several demonstration Kafka applications for blogs, and I experienced the challenge of scaling Kafka applications early on. Kafka itself is massively scalable, but to ensure your application is scalable end-to-end, with low latency as well, requires some non-standard solutions.
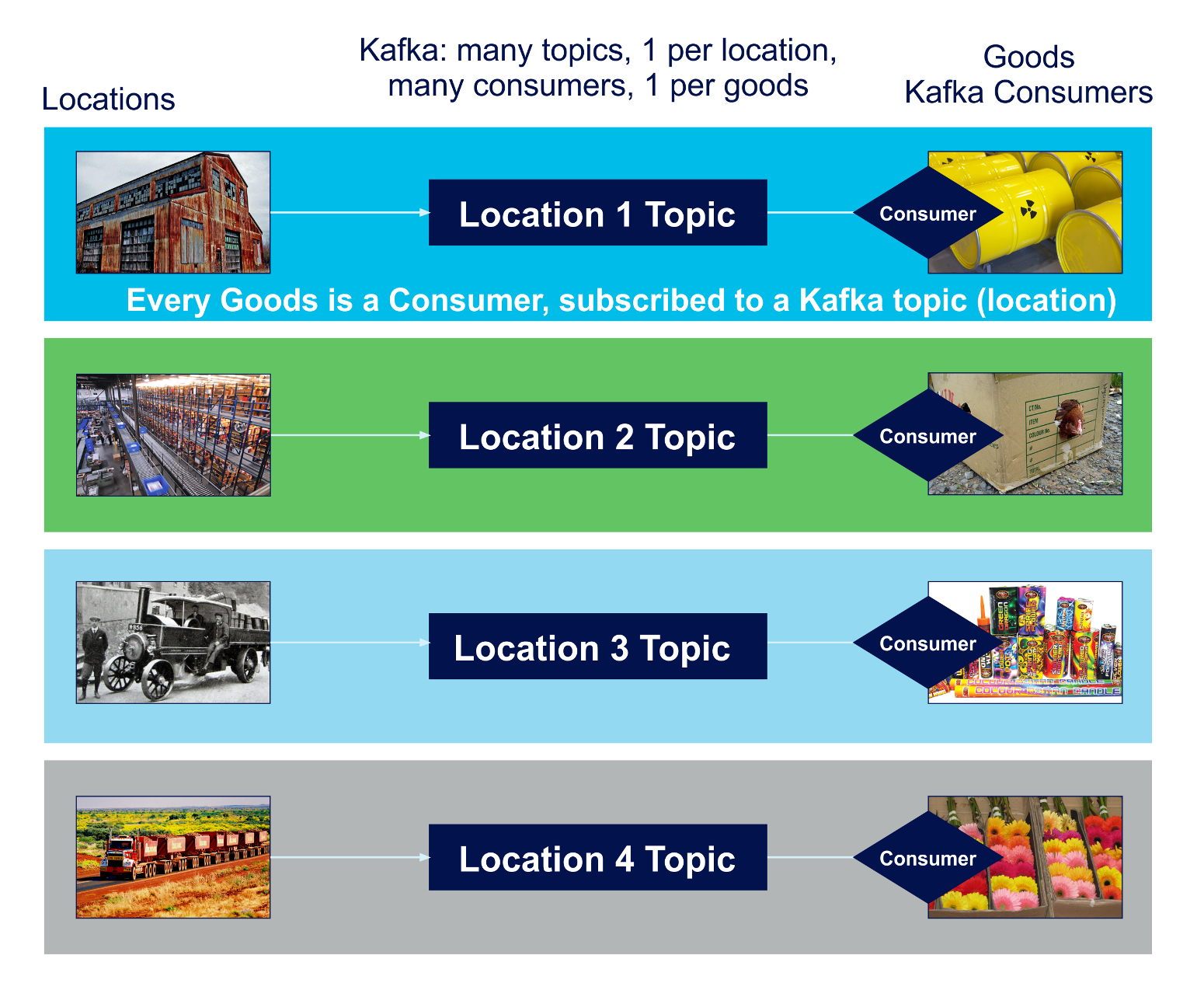
What happens when you are just (apparently) stuck with too many consumers, requiring as many partitions to support as there are consumers—potentially millions?!
For example, one of the earliest challenges I came across was to build a logistics application (simulating the delivery of goods, by trucks, to and from warehouses), which required checking of multiple rules for Goods in real-time. The simplest design had the Goods objects subscribing directly to topics, i.e., they were tightly coupled with Kafka consumers (see above). However, this had a serious performance impact due to the large number of partitions required to support potentially millions of Goods/consumers. There was also a large fan-out requirement, as some messages had to be delivered to many consumers, requiring a large number of consumer groups.
The solution I came up with was to decouple the Goods from the Kafka consumers. I built a separate event notification service between the Kafka consumers and the Goods objects using the Google Guava Event Bus, see this blog, and the diagram below.
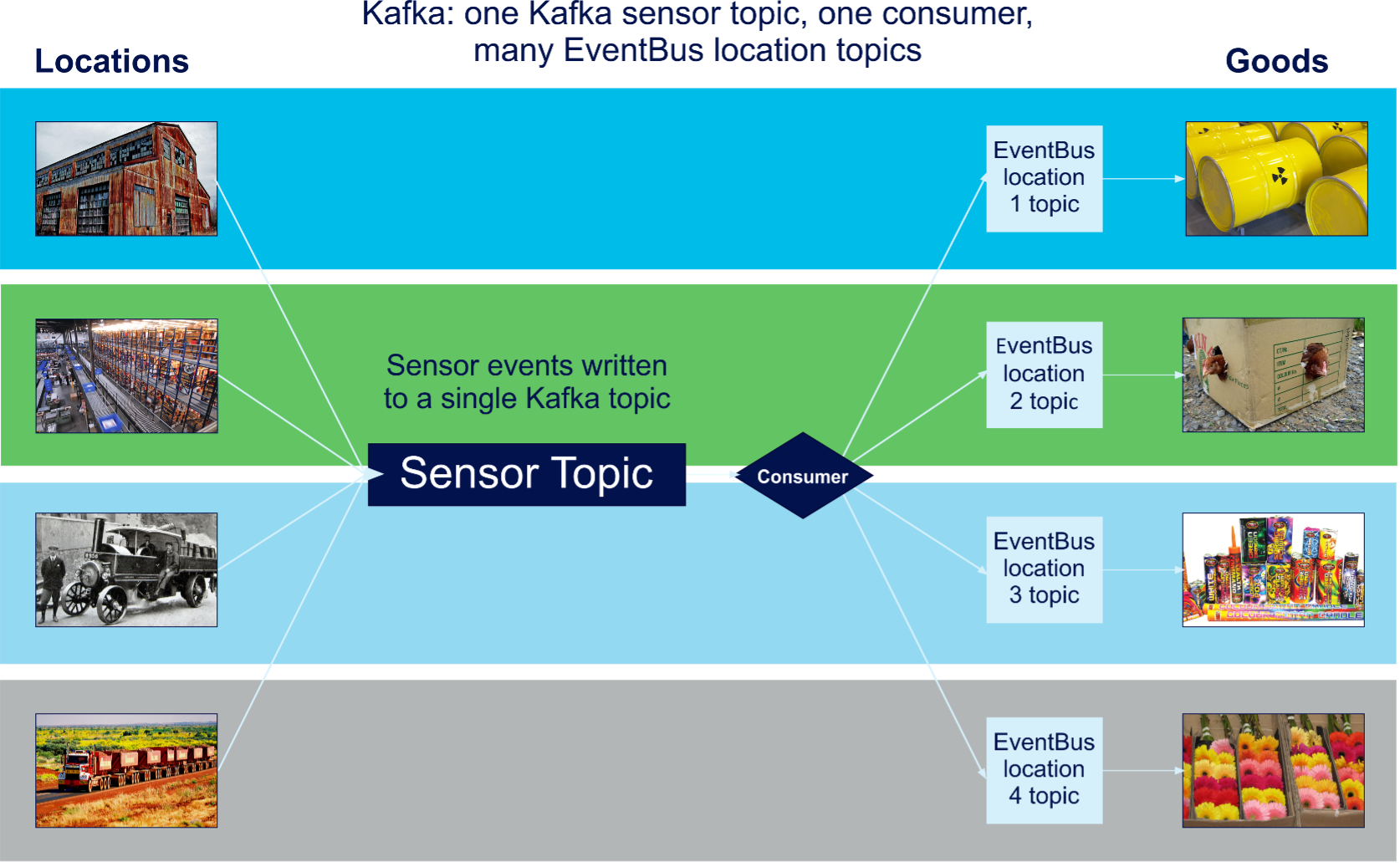
Decoupling the recipients (Goods objects) from the Kafka consumers means that you don’t need as many Kafka partitions/consumers as there are Goods—potentially only 1 partition and a few consumers (depending on the throughput requirements). The performance impact of this solution, along with an investigation of the impact of 1 or many topics (which impacts the number of partitions) was covered in here, here, and here (which also investigated some other scalability issues including the “Key parking problem” and consumer “rebalancing storms”).

The famous Bondi ocean pool (Sydney, Australia) actually has 2 pools (Kafka is the ocean in this example). (Source: Shutterstock)
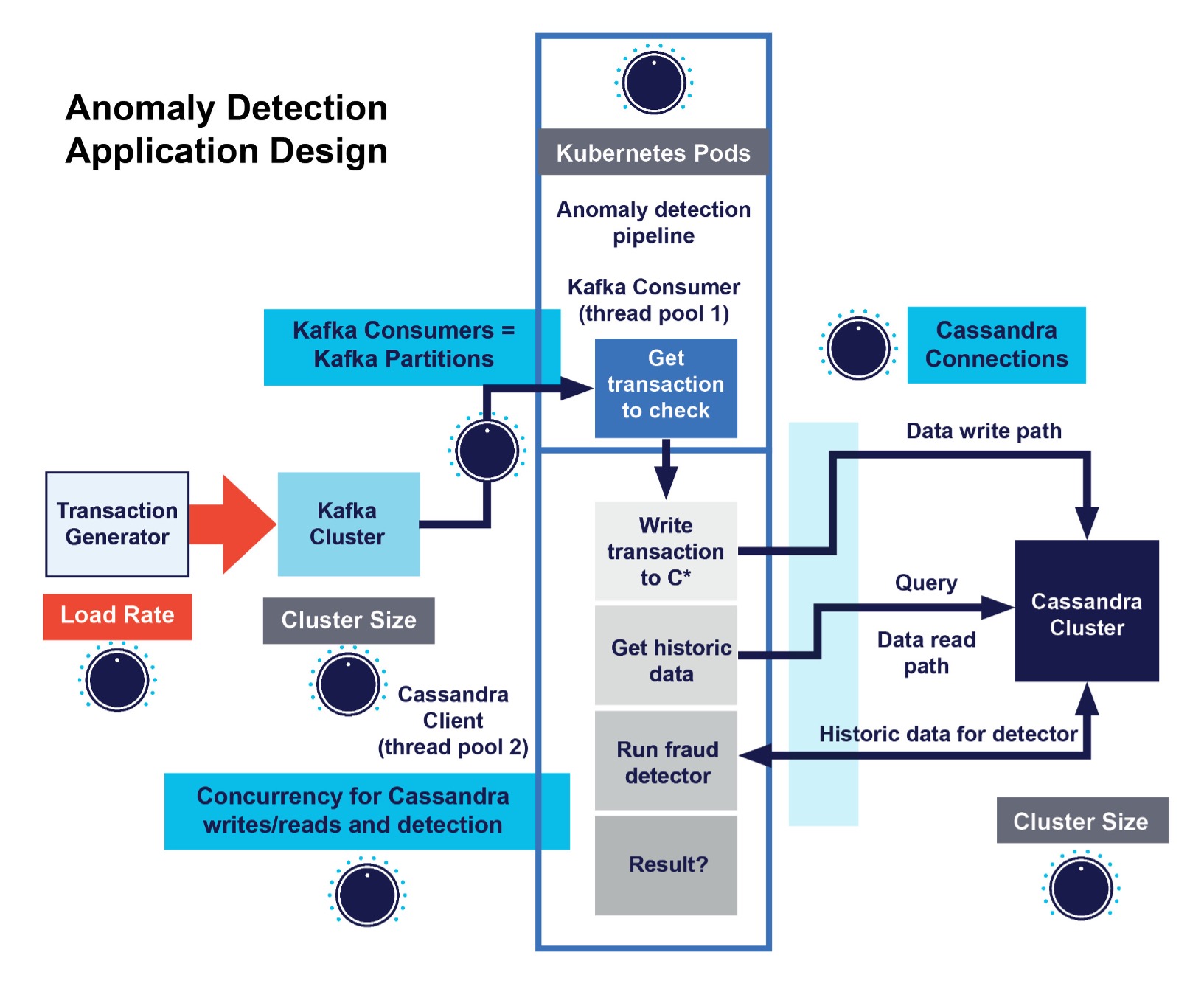
This approach of decoupling the record processing from the consumer polling loop was also used to improve the throughput and latency of the real-time anomaly detection application, Anomalia Machina. In this application, the Kafka consumer was “slow”, as for each record read it had to write data to Cassandra, read lots of historical data from Cassandra, and run the anomaly detection code. To get the final result (19 billion anomaly checks/day) I ended up using multi-threading, with 2 thread-pools, 1 pool for the polling loop, and 1 for the Cassandra client and detector code (as shown in this diagram) and tried both dynamic pool sizing, and manual pool sizing.
So, the idea of using a multi-threaded Kafka consumer is not new, but it is tricky to get right, tune, and make it generic enough for different applications. This is where the Kafka Parallel Consumer comes in.
3. Introducing the Kafka Parallel Consumer
The introductory photo actually shows a Jacquard Mechanical Loom. It used parallelism to automatically (with punched cards!) produce 18 different kinds of ribbon from multiple spools of thread.

Jacquard loom from the foyer of the Deutsches Technikmuseum, Berlin
(Source: Paul Brebner)
As we’ve seen so far, each default Kafka consumer is single-threaded and therefore has limited concurrency (1), and records with long processing times will cause increased latency, delaying other records. An obvious solution is therefore to decouple the polling loop from the processing loop using multiple thread pools. The size of the pools can be configured too so that records are read as fast as possible from Kafka, but also processed concurrently resulting in improved throughput and reduced latency. However, there are some complications including ensuring that offset commits are still processed correctly and preventing consumer timeouts due to the increase in commit times. A potential solution is the Kafka Parallel Consumer, which has an Apache 2.0 license. It has multiple components (and thread pools) to handle all of these for you.
But what about message ordering? By default, Kafka guarantees message ordering by Partition, which is also the default unit of concurrency. How would you improve consumer-side concurrency and still retain ordering guarantees? Basically, the Parallel Consumer allows you to configure it for different concurrency levels (maximum threads) and ordering mode. The idea is that each “unit” of concurrency can have a dedicated consumer thread, thereby still guaranteeing ordering and maximizing concurrency (i.e. Consumer, Partition, Key, Record).
Here’s a table summarizing the options listing consumer type and Mode, the Concurrency Limit for each mode, and the actual Concurrency Per Consumer achievable.
| Mode | Concurrency Limit | Concurrency Per Consumer |
| Default Consumer | Number of Consumers (<= Partitions) | 1 |
| Parallel Consumer, Partition Order | Number of Partitions | Partitions/Consumers |
| Parallel Consumer, Key Order | Number of distinct Keys | Keys/Consumers |
| Parallel Consumer, Unordered | Unlimited (Cluster and client infrastructure) | Per Record |
Because the potential concurrency increases for each mode, each option has the capability of delivering greater than or equal to the throughput of the previous option. The primary benefit for the Parallel Consumer is that each consumer is multi-threaded, so you can do more with less consumers (also requiring less partitions), i.e., In order of minimum to maximum Throughput:
|
1 |
Default Consumer <= Parallel Consumer (Partition Order) <= Parallel Consumer (Key Order) <= Parallel Consumer (Unordered, Per Record) |

The Kafka Parallel Consumer allows you to choose between different message orders – dogs can also be ordered in different ways, e.g., by height, age, cuteness, etc.
(Source: Shutterstock)
That’s all for the 1st part of this series. In Part 2 we’ll show some Kafka Parallel Consumer example code, a trace of slow consumer behavior, how to achieve 1 million TPS in theory, some experimental results, what else is interesting about the Parallel Consumer, and finally consider if you should use it in production or not.